在序列标注(sequence labeling)任务中,网络的目标是为输入序列中的每个词元分配一个来自小型固定标签集的标签。 其中最常见的序列标注任务之一是命名实体识别(Named Entity Recognition, NER)。
9.5.1 命名实体
粗略地说,命名实体(named entity)是指任何可以用专有名称指代的事物,例如人、地点或组织。 命名实体识别(NER)的任务是从文本中找出构成专有名称的文本片段(spans),并为其标注对应的实体类型。 最常用的四种实体标签是:PER(Person,人物)、LOC(Location,地点)、ORG(Organization,组织)、GPE(Geo-Political Entity,地缘政治实体,如国家、州、城市等)。 不过,“命名实体”这一术语通常被扩展使用,也包括一些严格意义上并非“实体”的表达,例如时间表达式(如日期、时刻),甚至数值表达式(如价格)。 以下是一个 NER 标注器的输出示例:
Citing high fuel prices, [
ORGUnited Airlines] said [TIMEFriday] it has increased fares by [MONEY$6] per round trip on flights to some cities also served by lower-cost carriers. [ORGAmerican Airlines], a unit of [ORGAMR Corp.], immediately matched the move, spokesman [PERTim Wagner] said. [ORGUnited], a unit of [ORGUAL Corp.], said the increase took effect [TIMEThursday] and applies to most routes where it competes against discount carriers, such as [LOCChicago] to [LOCDallas] and [LOCDenver] to [LOCSan Francisco].
这段文本共包含 13 个命名实体,其中包括 5 个组织、4 个地点、2 个时间、1 个人物和 1 个金额。 图 9.10 列出了典型的通用命名实体类型。 许多应用还需要识别更具体的实体类型,例如蛋白质、基因、商品或艺术作品。
| 类型 | 标签 | 示例类别 | 示例句子 |
|---|---|---|---|
| 人物 | PER | 人、虚构角色 | Turing is a giant of computer science. |
| 组织 | ORG | 公司、体育队伍 | The IPCC warned about the cyclone. |
| 地点 | LOC | 区域、山脉、海洋 | Mt. Sanitas is in Sunshine Canyon. |
| 地缘政治实体 | GPE | 国家、州、城市 | Palo Alto is raising the fees for parking. |
图 9.10 通用命名实体类型列表及其所指代的实体类别。
命名实体识别在多种自然语言处理任务中都具有重要作用,包括将文本链接到结构化知识源(如维基百科);分析文本中对特定实体的情感或态度;作为文本匿名化(anonymization)流程的一部分以保护隐私。 然而,NER 任务颇具挑战性,因为实体边界存在歧义,需要判断哪些词元属于实体、哪些不属于,而文本中大多数词实际上都不是命名实体。 另一项挑战是存类型歧义(type ambiguity)。 例如,“Washington” 可能指代人物、体育队伍、城市,或美国政府,如图 9.11 所示:
[
PERWashington] was born into slavery on the farm of James Burroughs. [ORGWashington] went up 2 games to 1 in the four-game series. Blair arrived in [LOCWashington] for what may well be his last state visit. In June, [GPEWashington] passed a primary seatbelt law.
图 9.11 “Washington” 一词在不同语境中表现出的类型歧义示例。
9.5.2 BIO 标注
在序列标注中,像命名实体识别(NER)这类序列标准任务面临难题:如何识别由连续词元组成的实体片段(span-recognition problem)。对此,一种标准的解决方案是 BIO 标注(Ramshaw 和 Marcus, 1995)。 该方法通过引入能同时编码片段边界(起始/内部)和实体类型的标签,将 NER 转化为一个逐词的序列标注任务。 考虑以下句子:
[
PERJane Villanueva] of [ORGUnited], a unit of [ORGUnited Airlines Holding], said the fare applies to the [LOCChicago] route.
图 9.12 展示了同一段文本分别使用 BIO 标注、以及两种变体——IO 标注 和 BIOES 标注 的表示方式。 在 BIO 标注中,任何片段起始位置的词元标记为 B(Begin),片段内部(非起始)的词元标记为 I(Inside),所有不属于任何目标片段的词元标记为 O(Outside)。 虽然只有一个 O 标签,但每种命名实体类别都有各自对应的 B 和 I 标签。 因此,若共有 $n$ 种实体类型,则总标签数为 $2n + 1$。 BIO 标注能够完全等价地表达带方括号的原始标注信息,其优势在于可将 NER 任务以与词性标注(POS tagging)相同的方式建模:即为每个输入词 $x_i$ 分配一个单一标签 $y_i$。
| 词语 | IO 标签 | BIO 标签 | BIOES 标签 |
|---|---|---|---|
| Jane | I-PER | B-PER | B-PER |
| Villanueva | I-PER | I-PER | E-PER |
| of | O | O | O |
| United | I-ORG | B-ORG | B-ORG |
| Airlines | I-ORG | I-ORG | I-ORG |
| Holding | I-ORG | I-ORG | E-ORG |
| discussed | O | O | O |
| the | O | O | O |
| Chicago | I-LOC | B-LOC | S-LOC |
| route | O | O | O |
| . | O | O | O |
图 9.12 将 NER 表示为序列标注任务,展示了 IO、BIO 和 BIOES 三种标注方案。
图中还展示了两种变体标注方案:IO 标注省略了 B 标签,仅用 I 表示实体内的所有词元,因此会丢失片段边界信息(例如无法区分连续两个同类型实体);BIOES 标注在 BIO 基础上进一步细化,增加了 E(End)标签用于标记片段的结尾,并引入 S(Single)标签表示单个词构成的完整片段(如 “Chicago” 作为单独的地名)。
9.5.3 序列标注
在序列标注任务中,我们将每个输入词元对应的最终输出向量送入一个分类器,该分类器会为每个词元生成一个在所有可能标签上的 softmax 概率分布。 若采用单层前馈神经网络作为分类器,则需学习的权重矩阵为 $\mathbf{W_K}$,其维度为 $[d \times k]$,其中 $k$ 是该任务中可能的标签总数。 一种简单的贪心解码策略是:对每个词元独立地取 softmax 输出中概率最大的标签(即 $\arg\max$)作为其预测结果,从而生成最终输出标签序列。 图 9.13 展示了这一方法的示例,其中 $\mathbf{y}_i$ 表示第 $i$ 个词元在所有标签上的概率分布,而 $k$ 用于索引各个标签类别:
$$ \begin{align*} \mathbf{y_i} &= \text{softmax}(\mathbf{h^L_i}\mathbf{W_K}) \tag{9.12} \\ \mathbf{t_i} &= \text{argmax}_k(\mathbf{y}_i) \tag{9.13} \end{align*} $$此外,也可以将每个词元 softmax 输出的标签分布传递给一个条件随机场(Conditional Random Field, CRF)层。CRF 能够建模标签之间的全局转移约束(关于 CRF 的详细内容见第 17 章)。
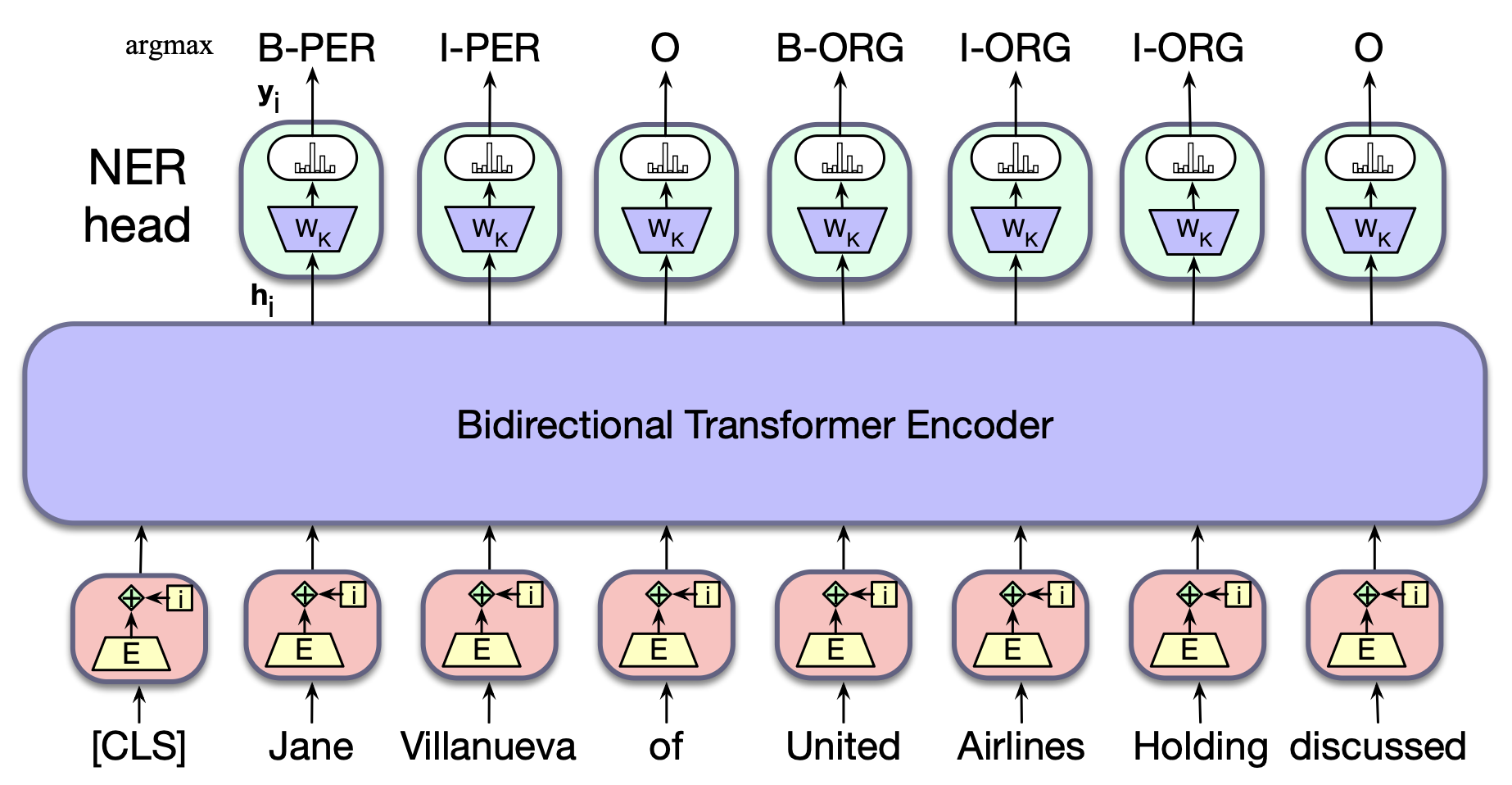
图 9.13 使用双向 Transformer 编码器进行命名实体识别的序列标注架构。 每个输入词元的输出向量被送入一个简单的 $k$ 路分类器,以预测其对应的标签。
词元化与 NER
需要注意的是,采用 BIO 标签形式的 NER,其有监督的训练数据通常以词级别分词(word-level segmentation)为基础。 例如,下面这个包含两个命名实体的句子:
[
LOCMt. Sanitas] is in [LOCSunshine Canyon].
其对应的逐词 BIO 标注如下:
(9.14) Mt. Sanitas is in Sunshine Canyon .
B-LOC I-LOC O O B-LOC I-LOC O
然而,当使用像 WordPiece 这样的子词(subword)词元化器时,该句子产生的序列无法直接与 BIO 标签的标注记对齐:
'Mt', '.', 'San', '##itas', 'is', 'in', 'Sunshine', 'Canyon', '.'
为解决这一对齐错位(misalignment)问题,我们需要在训练阶段将标签分配给由子词词元;在解码阶段从子词标签中恢复出词级别的最终预测标签。 在训练时,可直接将某个词的真实 BIO 标签复制给它对应的所有子词。
解码时,最简单的方法是仅采用一个词的第一个子词所预测的标签作为整个词的标签。
在上述例子中,我们会用 'Mt' 的预测标签作为 “Mt.” 的标签,用 'San' 的预测标签作为 “Sanitas” 的标签,而忽略 '.' 和 '##itas' 的预测结果。
当然,也存在更复杂的方法:综合一个词所有子词的标签概率分布,推断出最优的词级别标签。
9.5.4 命名实体识别的评估
命名实体识别系统通常使用召回率(recall)、精确率(precision)和F¹ 分数(F₁ measure)进行评估。 召回率是指被正确标注的实体数量占所有应被标注实体总数的比例; 精确率是指被正确标注的实体数量占系统实际标注实体总数的比例; F分数则是精确率与召回率的调和平均值。
要判断两个 NER 系统的 F₁ 分数差异是否具有统计显著性,通常采用配对自助法检验(paired bootstrap test)或类似的随机化检验(randomization test)(参见第 4.9 节)。
在命名实体标注任务中,评估的基本单位是“实体”而非“词”。 例如,在图 9.12 的示例中,Jane Villanueva、United Airlines Holding 和非实体词 discussed 各自被视为一个独立的响应。
由于命名实体识别包含片段切分(segmentation)这一成分,而文本分类或词性标注等任务则没有这一环节,这给评估带来了一些特殊挑战。
例如,若一个系统仅将 “Jane” 标注为 PER,而漏掉了 “Villanueva”,会产生两个错误,得到 O 是假阳性,I-PER 是假阴性。
此外,使用实体作为响应单位,单训练以词为单位,这种做法,导致了训练与最测试条件之间的不一致。