预训练语言模型的强大之处在于,它们能够从海量文本中提取出通用的语言规律,而这些规律对大量下游应用都非常有用。 要将这些通用知识应用于具体任务,主要有两种方式。 最常见的方式是使用自然语言对模型进行提示(prompt),引导模型进入某种状态,使其在上下文中生成我们期望的输出。
本节将探讨另一种利用预训练语言模型解决下游任务的方法:即第 7 章介绍过的微调(finetuning)范式的一种变体。 在针对掩码语言模型的微调方法中,我们会在预训练模型之上添加面向特定任务的模块(通常称为专用“头”,head),以预训练模型的输出作为该模块的输入。 微调过程利用带标签的任务数据来训练这些新增的、任务特定的参数。 通常情况下,这一训练过程会冻结预训练模型的大部分参数,或仅对其做极小幅度的调整。
接下来几节将介绍针对最常见任务类型的微调方法:序列分类(sequence classification)、句子对分类(sentence-pair classification)和序列标注(sequence labeling)。
9.4.1 序列分类
序列分类(sequence classification)任务的目标是为一整段文本序列分配一个单一的类别标签。 这类任务通常统称为文本分类(text classification),例如情感分析或垃圾邮件检测(见附录 K),在这些任务中,我们将一段文本分为两类或三类(如正面、负面);也包括类别数量较多的任务,例如文档级别的主题分类。
在序列分类中,我们用一个向量来表示整个待分类的输入序列。
表示序列的方式有多种。
一种方法是对序列中每个词元在模型最后一层输出的向量进行求和或取平均。
但对于 BERT,我们采用另一种方式:在词汇表中引入一个特殊的唯一标记 [CLS](代表“classification”),在预训练和推理阶段都将该标记添加到所有输入序列的开头。
模型最后一层中对应 [CLS] 标记的输出向量即被用作整个输入序列的表示,并作为后续分类器头部(classifier head)的输入。该分类器通常是一个逻辑回归模型或小型神经网络,用于做出最终的分类决策。
举个例子,回到情感分类问题。
针对该任务进行微调,需要学习一组权重矩阵 $\mathbf{W_C}$,将 [CLS] 标记的输出向量 $\mathbf{h}^L_{\text{CLS}}$ 映射到各个情感类别上的得分。
假设这是一个三分类情感任务(正面、负面、中性),且模型的隐藏维度为 $d$,那么 $\mathbf{W_C}$ 的维度就是 $[d \times 3]$。
要对一篇文档进行分类,我们首先将输入文本送入预训练语言模型,得到 $\mathbf{h}^L_{\text{CLS}}$,然后将其与 $\mathbf{W_C}$ 相乘,并将结果通过 softmax 函数归一化为概率分布:
对 $\mathbf{W_C}$ 的微调需要依赖带标签的监督训练数据,即每条输入序列都标注了正确的情感类别。 训练过程采用标准方式:使用 softmax 输出与真实标签之间的交叉熵损失来驱动 $\mathbf{W_C}$ 的学习。
此外,该损失函数不仅可以用于更新分类器的权重,还可以反向传播以微调预训练语言模型本身的参数。 在实践中,通常只需对语言模型参数做极小幅度的调整就能获得良好的分类性能,且更新往往仅限于 Transformer 的最后几层。 图 9.9 展示了这种序列分类的整体架构。
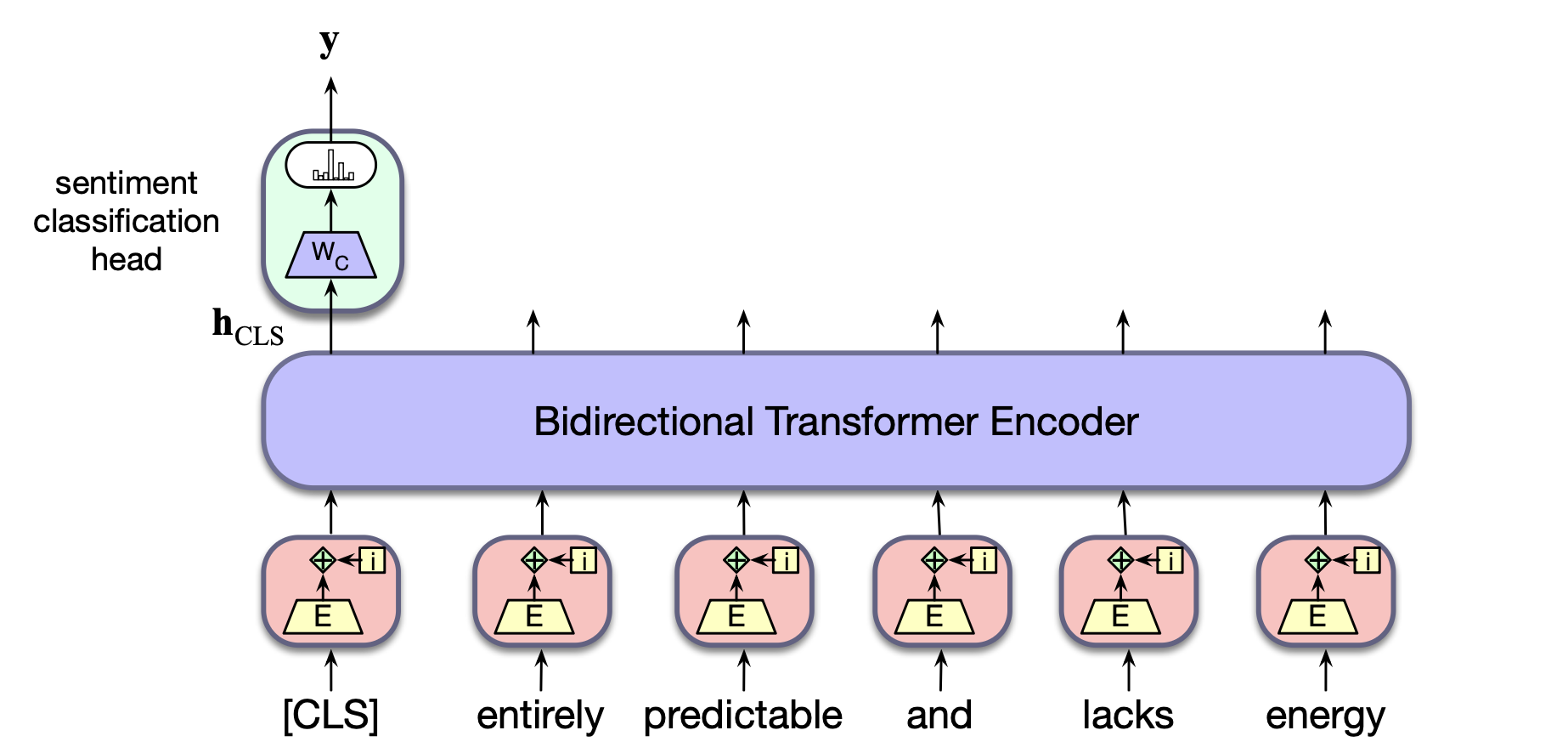
图 9.9 基于双向 Transformer 编码器的序列分类。
[CLS] 标记的输出向量作为简单分类器的输入。
9.4.2 句子对分类
如第 9.2.2 节所述,一类重要的任务涉及对两个输入序列组成的句子对进行分类。 这类任务的实际应用包括释义检测(paraphrase detection,两个句子是否互为释义?)、逻辑蕴涵(logical entailment,句子 A 是否在逻辑上蕴含句子 B?)、话语连贯性判断(discourse coherence,句子 B 作为句子 A 的后续是否连贯?)。
针对这类任务的微调过程与预训练阶段使用的下一句预测(NSP)目标非常相似。
在微调时,模型接收来自监督微调数据集的带标签句子对,将它们送入模型的所有层,生成每个输入词元的输出向量 $\mathbf{h}$。
与序列分类一样,添加在输入开头的 [CLS] 标记所对应的输出向量被用作整个句子对的表示。
同时,与 NSP 预训练一致,两个输入句子之间用特殊的 [SEP] 标记分隔。
为了完成分类,该 [CLS] 向量会与一组可学习的分类权重相乘,并通过 softmax 函数生成类别预测结果,随后利用这些预测更新模型参数。
以多体裁自然语言推理(Multi-Genre Natural Language Inference, MultiNLI)数据集(Williams 等,2018)中的蕴涵分类任务为例。 在自然语言推理(Natural Language Inference, NLI),也称为文本蕴涵识别(Recognizing Textual Entailment)任务中,模型接收一对句子,并需判断它们语义之间的关系。 在 MultiNLI 语料库中,每对句子被标注为以下三类之一:entails(蕴涵)、contradicts(矛盾)和 neutral(中立)。 这些标签描述了前提句(premise,第一句)与假设句(hypothesis,第二句)之间的语义关系。 以下是语料库中各类别的典型示例:
Neutral(中立)
a: Jon walked back to the town to the smithy.
b: Jon traveled back to his hometown.Contradicts(矛盾)
a: Tourist Information offices can be very helpful.
b: Tourist Information offices are never of any help.Entails(蕴涵)
a: I’m confused.
b: Not all of it is very clear to me.
其中,contradicts 表示前提与假设相互矛盾;entails 表示前提在语义上支持或蕴含假设;neutral 则表示两者之间既无明显蕴涵也无矛盾关系。 需要注意的是,这些标签的含义比严格的逻辑蕴涵或矛盾更为宽松——它们反映的是普通人类读者在理解句子时最可能做出的语义判断。
为了在 MultiNLI 任务上微调分类器,我们将前提-假设句子对输入上述的双向编码器,并使用 [CLS] 标记的输出向量作为分类头的输入。
与普通序列分类类似,该分类头构成一个三分类器,可在 MultiNLI 训练语料上进行训练。