给定一个预训练好的语言模型和一个新的输入句子,我们可以将模型输出的序列视为输入中每个词元的上下文嵌入(contextual embeddings)。 这些上下文嵌入是向量,用于表示某个词元在其具体上下文中的语义某一方面,可应用于任何需要理解词元或词语含义的任务。 更形式化地,给定一个输入词元序列 $x_1, \cdots, x_n$,我们可以使用模型最终层 $L$ 的输出向量 $\mathbf{h}^L_i$ 作为词元 $x_i$ 在句子 $x_1, \dots, x_n$ 上下文中的语义表示。 或者,除了仅使用最终层的向量 $\mathbf{h}^L_i$ 外,一种常见做法是通过对模型最后四层的输出向量进行平均来构建 $x_i$ 的表示,$\mathbf{h}^L_i$、$\ \mathbf{h}^{L-1}_i$、$\mathbf{h}^{L-2}_i$、$\mathbf{h}^{L-3}_i$。
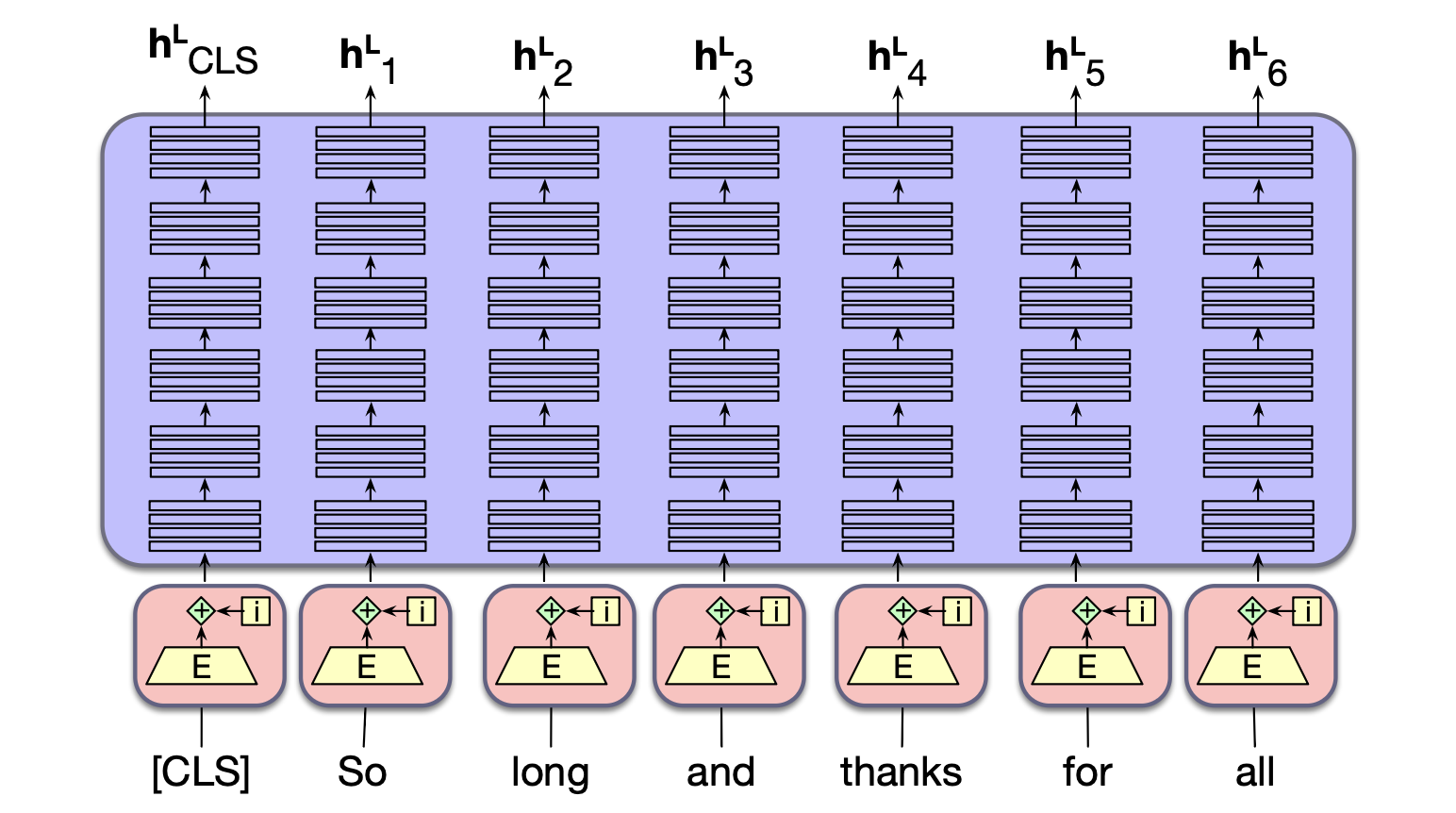
图 9.5 BERT 类模型的输出是对每个输入词元 $x_i$ 生成的一个上下文嵌入向量 $\mathbf{h}^L_i$。
正如我们在第 5 章中使用 word2vec 等静态嵌入(static embeddings)来表示词语的含义一样,我们也可以将上下文嵌入用作词语在具体语境中含义的表示,以支持任何需要建模词语语义的任务。 静态嵌入表示的是词型(word types,即词汇表条目)的含义,而上下文嵌入表示的是词例(word instances)的含义——即某一特定词型在特定上下文中的具体出现实例。 因此,如果说 word2vec 为每个词型只提供一个固定向量,那么上下文嵌入则为该词型在每一个句子上下文中的每次出现都提供一个独立的向量。 正因如此,上下文嵌入可用于诸如衡量两个词语在各自上下文中的语义相似度等任务,并在需要词语语义建模的语言学任务中发挥重要作用。
9.3.1 上下文嵌入与词义
词语具有歧义性(ambiguous):同一个词可以表达不同的含义。 在第 5 章中我们看到,单词 “mouse” 可以指:(1) 一种小型啮齿动物,或 (2) 一种用于控制光标的手持设备。“bank” 则可能指:(1) 一家金融机构,或 (2) 河岸(即一侧倾斜隆起的土坡)。 我们称像 “mouse” 或 “bank” 这样的词为多义词(polysemous),该词源自希腊语 “many senses”(poly- 表示“多”,sema 表示“符号、标记”)。1
一个词义(sense 或 word sense)是对词语某一特定含义的离散化表示。 我们可以用上标来区分不同词义:如 bank¹ 与 bank²、mouse¹ 与 mouse²。 这些词义可以在在线词典或同义词词典(thesauruses/thesauri)中找到,例如 WordNet(Fellbaum,1998)——它提供了多种语言的数据集,列出了大量词语的不同词义。 在具体上下文中,不同词义很容易区分,以下英文例句展示了英语中典型的一词多义现象:
- mouse¹: …. a mouse controlling a computer system in 1968.
- mouse²: …. a quiet animal like a mouse
- bank¹: …a bank can hold the investments in a custodial account …
- bank²: …as agriculture burgeons on the east bank, the river …
上例中,上下文消除了“mouse” 和 “bank” 词义中的歧义,这一现象也可以从几何角度直观呈现。 图 9.6 展示了英语和德语中单词 die 的大量 BERT 嵌入实例在二维空间中的投影。 图中每个点代表 die 在某一句输入句子中的使用。 我们可以清晰地看到 die 至少包含两种不同的英语词义(一是“骰子”的单数形式,二是动词“死亡”),以及德语中的冠词用法——它们在 BERT 嵌入空间中形成了不同的聚类。
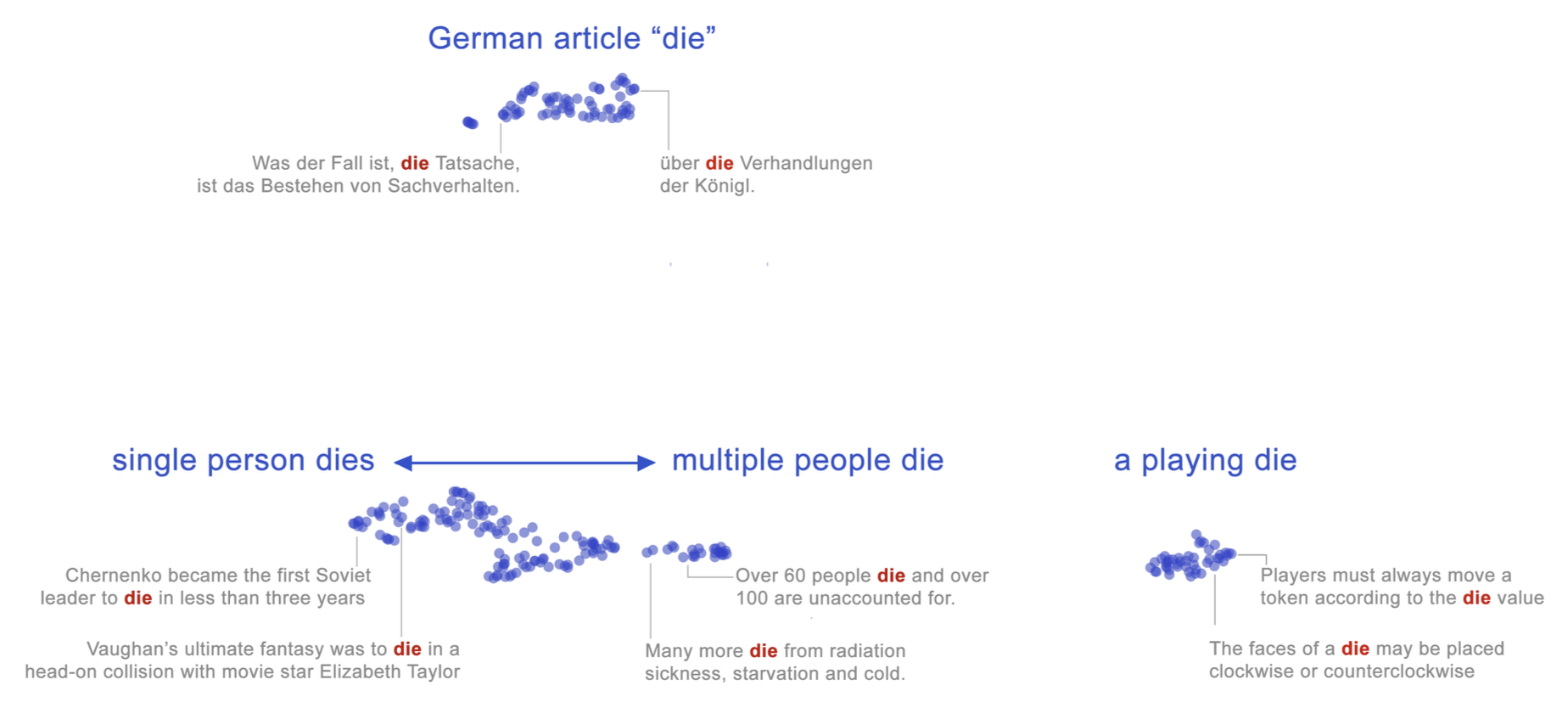
图 9.6 每个蓝点表示来自英语和德语不同句子中单词 die 的 BERT 上下文嵌入,通过 UMAP 算法投影到二维空间。 德语与英语的含义、以及英语内部的不同词义,各自聚集成不同的簇。 图中标注了一些样本点及其对应的上下文句子。 引自 Coenen 等(2019)。
因此,尽管 WordNet 等词典提供的是离散的词义列表,但嵌入表示(无论是静态嵌入还是上下文嵌入)所提供的是一种连续的、高维的语义模型,这种模型虽然可以聚类出近似词义的区域,但并不严格划分为完全离散的词义单元。
词义消歧
为词语选择正确词义的任务被称为词义消歧(Word Sense Disambiguation, WSD)。 WSD 算法的输入是一个处于上下文中的词语以及一个固定的候选词义清单(例如 WordNet 中列出的词义),输出则是该词语在当前上下文中的正确词义。 图 9.7 示意了这一任务。
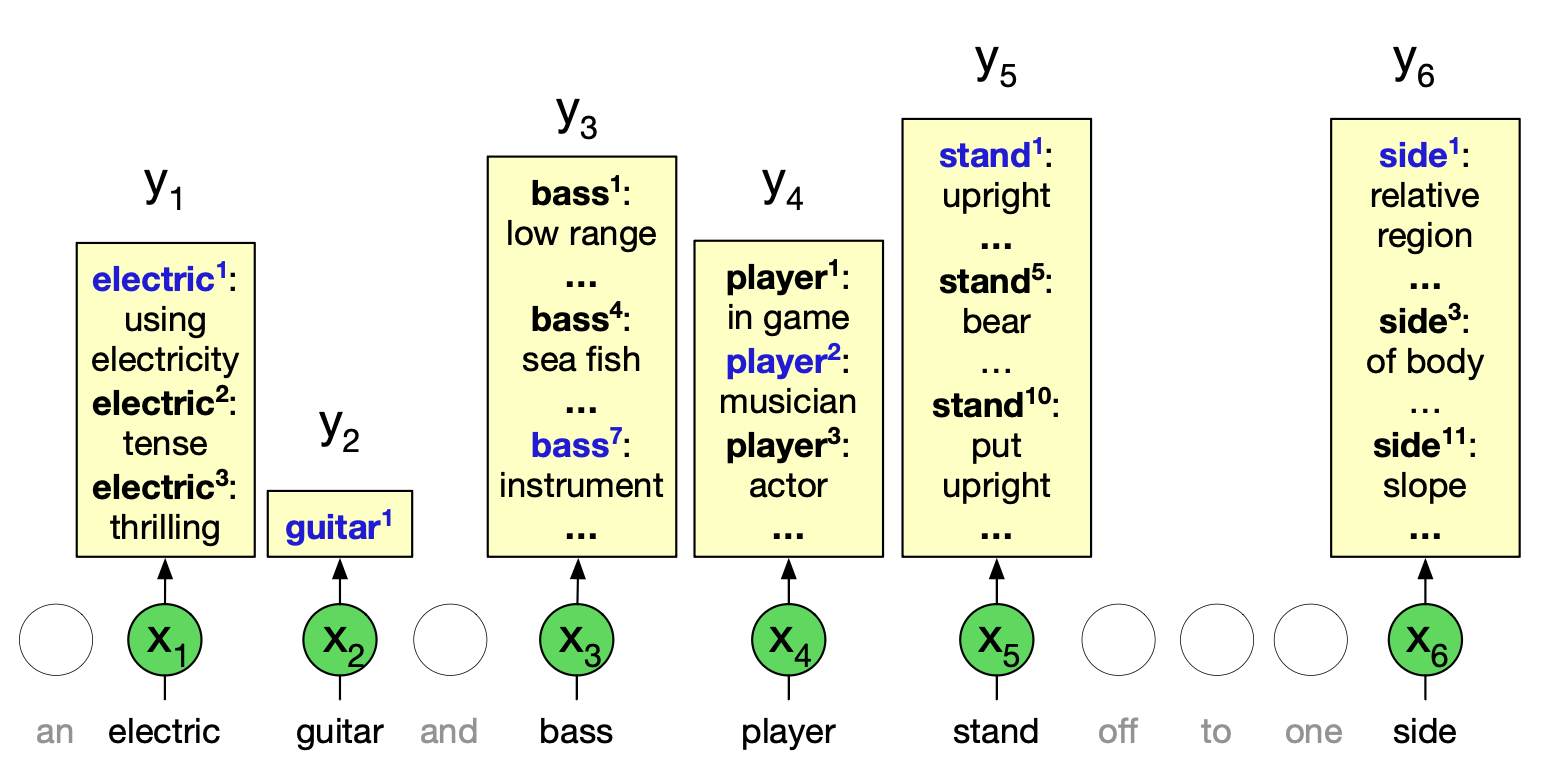
图 9.7 全词词义消歧(all-words WSD)任务:将输入词语(x)映射到 WordNet 词义(y)。 图示灵感来自 Chaplot 与 Salakhutdinov(2018)。
WSD 可作为人文与社会科学中文本分析的一项有用分析工具,词义也有助于提升词表示模型的可解释性。 此外,词义还具有有趣的分布特性。 例如,在一段语篇中,一个词通常以大致相同的词义被反复使用——这一现象被称为一篇一义律(one sense per discourse rule)(Gale 等,1992a)。
目前性能最好的 WSD 算法是一种基于上下文词嵌入的简单 1-最近邻(1-nearest-neighbor)方法,由 Melamud 等(2016)和 Peters 等(2018)提出。 在训练阶段,我们将某个带有词义标注的数据集(如多语言的 SemCor 或 SenseEval 数据集)中的每个句子输入任意上下文嵌入模型(例如 BERT),从而为每个已标注的词元生成其上下文嵌入。 (计算词元 $i$ 的上下文嵌入 $\mathbf{v}_i$ 有多种方式;对于 BERT,通常的做法是对最后四层中该词元的向量表示进行加总,实现多层池化。) 随后,对于语料库中任意词语的每个词义 $s$,我们收集该词义对应的全部 $n$ 个词元实例,对其各自的上下文嵌入 $\mathbf{v}_i$ 求平均,得到该词义 $s$ 的词义嵌入(sense embedding)$\mathbf{v}_s$:
$$ \mathbf{v}_s = \frac{1}{n} \sum_i \mathbf{v}_i \quad \forall \mathbf{v}_i \in \text{tokens}(s) \tag{9.6} $$在测试阶段,给定目标词 $t$ 在某一上下文中的词元,我们首先计算其上下文嵌入 $\mathbf{t}$,然后从训练集中选择与其最相似的词义——即词义嵌入与 $\mathbf{t}$ 余弦相似度最高的那个词义:
$$ \text{sense}(t) = \underset{s \in \text{senses}(t)}{\text{argmax}} \; \text{cosine}(\mathbf{t}, \mathbf{v}_s) \tag{9.7} $$图 9.8 展示了该模型的工作流程。
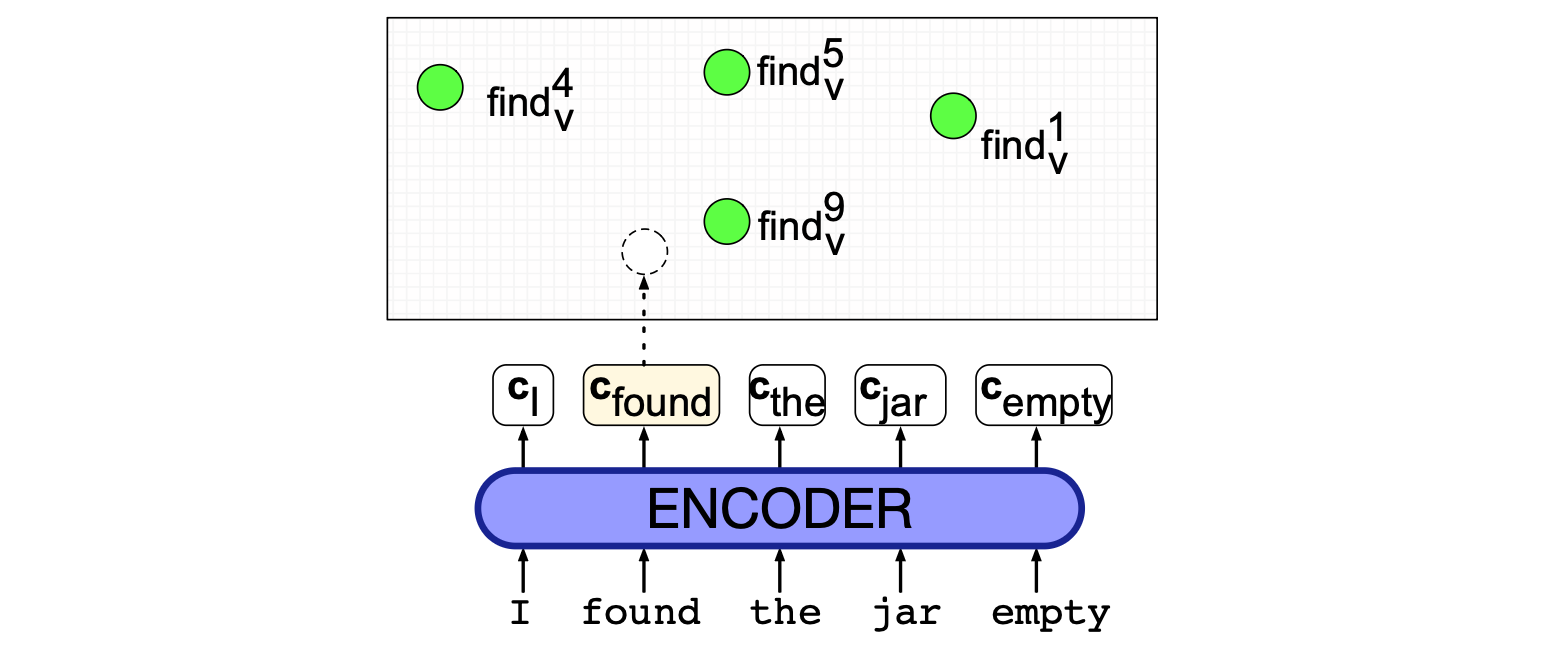
图 9.8 用于 WSD 的最近邻算法。 绿色部分是为每个词语的各个词义预先计算好的上下文嵌入;此处仅展示了动词 find 的若干词义。 系统为上下文中的目标词 found 计算其上下文嵌入,然后选择最近邻的词义(本例中为 $\text{find}^9_v$)。 图示灵感来自 Loureiro 与 Jorge(2019)。
9.3.2 上下文嵌入与词语相似度
在第 5 章中,我们介绍了通过几何距离来衡量两个词语相似度的思想,其中常用余弦相似度作为相似性函数。 这一语义相似性的概念在图 9.6 的语义聚类中也清晰可见:某个词在特定上下文中所呈现的表示,会更靠近该词其他具有相同词义的实例。 因此,我们通常通过计算两个词语实例(可以是两个不同词,也可以是同一词在不同上下文中的两次出现)的上下文嵌入之间的余弦值,来衡量它们在语境中的相似度。
然而,在计算余弦相似度之前,通常需要对嵌入向量进行某种变换。 这是因为上下文嵌入(无论是来自掩码语言模型还是自回归模型)中,所有词的向量都极其相似。 观察 BERT 或其他模型最后一层的输出,随机选取任意两个词元实例的嵌入,它们的余弦值往往极高,甚至接近 1,这意味着所有词向量都倾向于指向几乎相同的方向。 这种向量系统中所有向量趋向于指向某一方向的特性,被称为各向异性(anisotropy)。 Ethayarajh(2019)将一个模型的各向异性定义为:语料库中任意两个词嵌入之间余弦相似度的期望值。 “各向同性”(isotropy)意指在所有方向上均匀分布;因此,在一个理想的各向同性模型中,嵌入向量应均匀地指向各个方向,任意两个随机嵌入之间的期望余弦值应为 0。 Timkey 与 van Schijndel(2021)指出,各向异性的一个成因是:余弦相似度被上下文嵌入中少数几个维度所主导,这些维度的取值与其他维度显著不同。这些所谓的异常维度(rogue dimensions)具有极大的幅值和极高的方差。
为缓解此问题,Timkey 与 van Schijndel(2021)提出可通过标准化(z-score 标准化)使嵌入更加各向同性,即对向量减去均值并除以标准差。 给定某个语料库中所有嵌入组成的集合 $C$,每个嵌入维度为 $d$(即 $\mathbf{x} \in \mathbb{R}^d$),其均值向量 $\boldsymbol{\mu} \in \mathbb{R}^d$ 为:
$$ \boldsymbol{\mu} = \frac{1}{|C|} \sum_{\mathbf{x} \in C} \mathbf{x} \tag{9.8} $$每个维度上的标准差 $\sigma \in \mathbb{R}^d$ 为:
$$ \sigma = \sqrt{ \frac{1}{|C|} \sum_{\mathbf{x} \in C} (\mathbf{x} - \boldsymbol{\mu})^2 } \tag{9.9} $$随后,每个词向量 $\mathbf{x}$ 被替换为其标准化版本 $\mathbf{z}$:
$$ \mathbf{z} = \frac{\mathbf{x} - \boldsymbol{\mu}}{\boldsymbol{\sigma}} \tag{9.10} $$然而,标准化并不能解决余弦相似度的另一个问题:对于高频词,余弦相似度往往会低估人类对其语义相似性的判断(Zhou 等,2022)。
术语 polysemy(多义性)本身也存在歧义;你可能会看到它被用于更狭义的场景,仅指那些词义之间存在某种结构性关联的情况,而将同形异义(homonymy)一词保留给那些词义之间毫无关联的歧义情形(Haber 和 Poesio,2020)。本文中,我们将用 “polysemy” 泛指任何形式的词义歧义,而用 “structured polysemy” 特指词义之间存在关联的多义现象。 ↩︎