在第 8 章中,我们通过让因果型 Transformer 语言模型逐词预测文本中的下一个词来进行训练。 然而,一旦我们在注意力机制中移除了因果掩码,这种“预测下一个词”的语言建模任务就变得毫无意义——因为答案已经直接出现在上下文中(模型可以“偷看”未来词)。因此,我们需要一种全新的训练方案。 取而代之的是,模型不再预测下一个词,而是学习完成一种填空任务(fill-in-the-blank task),在技术上被称为 Cloze 任务(Taylor, 1953)。 为理解这一点,让我们回到第 3 章中的那个示例。 传统语言模型会尝试预测下面这句话接下来最可能出现的词:
The water of Walden Pond is so beautifully ____
而在 Cloze 任务中,给定句子中缺失一个或多个词的情况,要求模型根据其余部分预测缺失的内容。例如:
The ___ of Walden Pond is so beautifully …
也就是说,给定一个部分被遮蔽的输入序列,学习目标是还原出被遮蔽的元素。 更具体地说,在训练过程中,模型会被剥夺输入序列中的一个或多个词元,并必须为每个缺失位置生成一个在整个词表上的概率分布。 然后,我们利用模型在每个被遮蔽位置上的预测与真实词之间的交叉熵损失来驱动整个学习过程。
这种方法可以推广到多种对训练输入进行破坏(corrupt)后再让模型恢复原始内容的策略。 已被采用的破坏方式包括:掩码(masking)、替换(substitutions)、重排(reorderings)、删除(deletions)、插入干扰项(extraneous insertions)。 这类训练方法统称为 去噪(denoising):我们以某种方式对输入引入噪声(例如遮蔽一个词,或插入一个错误词),而模型的目标就是去除噪声、重建原始干净的输入。
9.2.1 词元掩码
下面我们介绍用于训练双向编码器的掩码语言建模(Masked Language Modeling, MLM)方法(Devlin 等,2019)。
与我们之前看到的语言模型训练方法类似,MLM 也使用大规模语料库中的无标注文本。
在 MLM 训练中,模型接收来自训练语料的一系列句子,其中一定比例的词元(在 BERT 模型中为 15%)会被随机选中,并通过掩码操作进行处理。
以输入句子 lunch was delicious 为例,假设我们随机选择处理第 3 个词元 delicious:
- 80% 的概率:将该词元替换为特殊的词汇表标记
[MASK],例如:lunch was delicious→lunch was [MASK] - 10% 的概率:将该词元替换为从词汇表中根据一元词频分布随机采样的另一个词元,例如:
lunch was delicious→lunch was gasp - 10% 的概率:保留原词不变,例如:
lunch was delicious→lunch was delicious
随后,我们训练模型去预测这些被修改词元的原始正确词元。
为什么要采用这三种修改方式?
引入 [MASK] 标记会导致预训练阶段与下游任务的微调或推理阶段之间出现不匹配,因为当我们使用 MLM 模型执行下游任务时,输入中不会包含任何 [MASK] 标记。
如果我们只是简单地将词元替换为 [MASK],模型可能会只在看到 [MASK] 时才尝试预测词元;而我们真正希望的是,模型始终尝试预测输入中的原始词元。
为了训练模型进行预测,首先使用子词模型词元化原始输入序列,并从中采样出一部分词元用于修改。 输入中所有词元的词嵌入均从嵌入矩阵 $\mathbf{E}$ 中取出,并与位置嵌入相加,构成 Transformer 的输入;该输入随后依次经过堆叠起来的双向 Transformer 块,再送入语言建模头。 MLM 的训练目标是:对每一个被掩码的词元,预测其原始输入值;这些预测所产生的交叉熵损失,驱动模型中所有参数的训练更新。 也就是说,所有输入词元都参与自注意力计算,但只有被采样的那些词元用于学习(即仅它们的预测参与损失计算)。
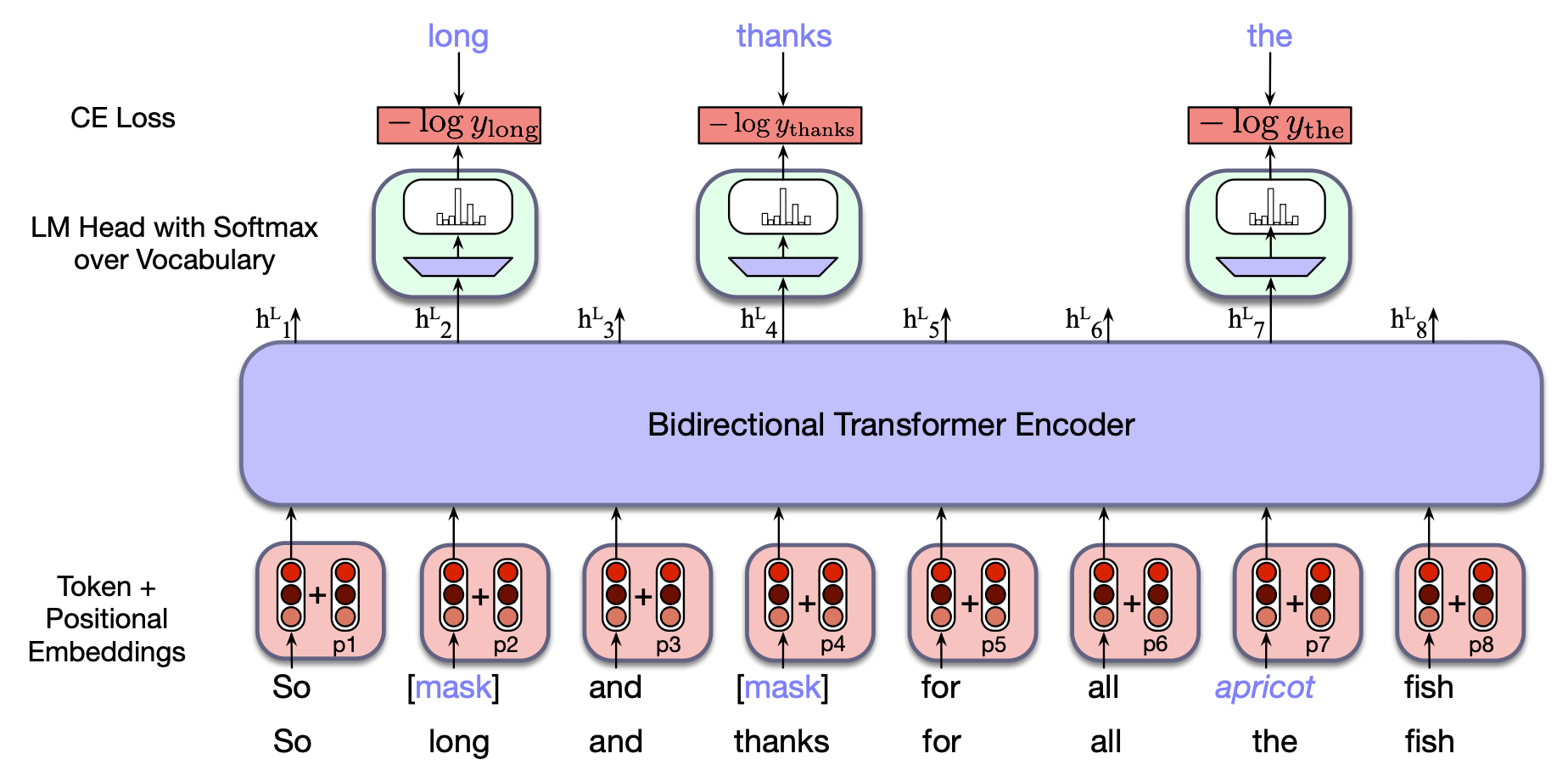
图 9.3 掩码语言模型训练示例。
本例中,输入序列中有三个词元被选中:其中两个被替换为 [MASK],第三个被替换为无关词 apricot。
模型对这三个位置的预测概率用于计算训练损失。
其余五个词元不参与损失计算。
图 9.3 通过一个简单示例展示了这一方法。
在此例中,从训练序列中采样出 long、thanks 和 the 三个词元,其中前两个被替换为掩码([MASK]),而 the 被替换为一个随机采样的词元 apricot。
所得到的嵌入向量随后被送入一个双向 Transformer 块的堆叠结构中。
回顾第 8 章第 8.5 节的内容:为了对每个被掩码的词元生成词表上的概率分布,语言建模头会取最终 Transformer 层 $L$ 中每个被掩码词元 $i$ 的输出向量 $\mathbf{h}^L_i$,将其与反嵌入层(unembedding layer)$\mathbf{E}^\top$ 相乘以得到 logits 向量 $\mathbf{u}$,再通过 softmax 将这些 logits 转换为词表上的概率分布 $\mathbf{y}$:
有了每个被掩码项的预测概率分布后,即可用交叉熵损失计算每个掩码位置的误差——即模型赋予真实被掩词元的负对数概率(如图 9.3 所示)。
更形式化地,设输入句子(或批次)的词元序列为 $\mathbf{x}$,被掩码的词元索引集合为 $M$,掩码后的序列为 $\mathbf{x}^{\text{mask}}$,模型输出序列为 $\mathbf{h}$。对于某个被掩词元 $x_i$(如图中的 long),其损失为:
对于每个被掩码项,模型都会输出一个预测的概率分布,我们可以利用交叉熵来计算每个被掩码项的损失——即模型赋予真实被掩码词元的那个概率的负对数,如图 9.3 所示。
更形式化地,对于句子或批次中给定的输入词元向量 $\mathbf{x}$,令被掩码的词元集合为 $M$,将其中部分词元替换为掩码后得到的序列为 $\mathbf{x}^{\text{mask}}$,模型输出的向量序列为 $\mathbf{h}$。
对于某个给定的输入词元 $x_i$(例如图 9.3 中的单词 long),其损失即为:在给定 $\mathbf{x}^{\text{mask}}$ 的条件下,模型预测出正确词 long 的概率(该条件信息被汇总在单个输出向量 $\mathbf{h}^L_i$ 中):
构成权重更新基础的梯度,是基于单个训练序列(或序列批次)中所有被采样学习项的平均损失计算得出的:
$$ L_{\text{MLM}} = -\frac{1}{|M|} \sum_{i \in M} \log P(x_i \mid \mathbf{h}^L_i) $$注意:只有集合 $M$ 中的词元参与损失计算,其余词元对梯度更新没有贡献。因此,从这个角度看,BERT 及其衍生模型在训练上是低效的——每次训练仅利用了输入中约 15% 的词元来更新参数。1
9.2.2 下一句预测
基于掩码的学习重点是根据上下文预测词语,其目标是生成有效的词级表示。 然而,有一类重要应用涉及判断句子对之间的关系。 这类任务包括释义检测(paraphrase detection,判断两个句子是否具有相似含义)、蕴含识别(entailment,判断两个句子的语义是相互蕴含还是彼此矛盾)、语篇连贯性判断(discourse coherence,判断两个相邻句子是否构成连贯的语篇)。
为了捕获此类应用所需的知识,BERT 系列中的一些模型引入了第二个学习目标,称为下一句预测(Next Sentence Prediction, NSP)。 在该任务中,模型接收成对的句子,并被要求预测:每一对句子究竟是来自训练语料中的真实相邻句对,还是由两个无关的句子组合而成。 在 BERT 中,50% 的训练句对为正样本(即真实相邻句对),其余 50% 的句对中,第二个句子是从语料库其他位置随机选取的。 NSP 损失即基于模型区分真实句对与随机句对的能力来计算。
为支持 NSP 训练,BERT 在输入表示中引入了两个特殊标记(这些标记在后续微调阶段也被证明十分有用)。
在使用子词模型对输入词元化后,在句对开头添加标记 [CLS];在两个句子之间以及第二个句子末尾插入标记 [SEP]。
实际上还有另外两个特殊标记:“第一段”(First Segment)标记和“第二段”(Second Segment)标记。
这些标记在输入阶段被加入到词嵌入和位置嵌入中。
也就是说,输入 $\mathbf{X}$ 中的每个词元实际上是三个嵌入向量之和:词嵌入、位置嵌入和段落嵌入(第一段或第二段)。
在训练过程中,最终层中与 [CLS] 标记对应的输出向量 $\mathbf{h}^L_{\text{CLS}}$ 被用于下一句预测。
与 MLM 目标类似,我们在此也添加一个专用的预测头——即 NSP 头,它包含一组可学习的分类权重 $\mathbf{W}_{\text{NSP}} \in \mathbb{R}^{d \times 2}$,用于从原始的 [CLS] 向量 $\mathbf{h}^L_{\text{CLS}}$ 生成二分类预测:
模型对每个输入的句子对,使用交叉熵计算 NSP 损失。 图 9.4 展示了 NSP 训练的整体设置。 在 BERT 中,NSP 损失与 MLM 训练目标联合使用,共同构成最终的总损失。
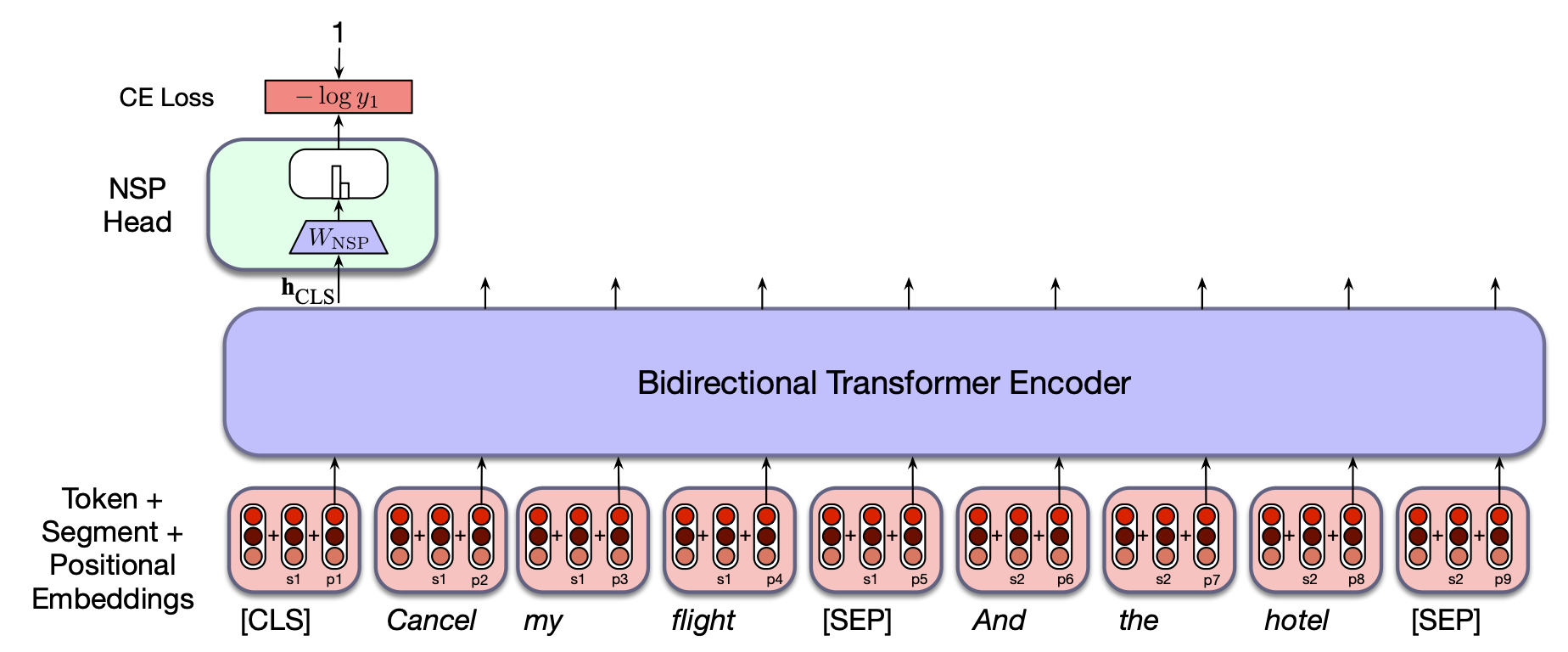
图 9.4 计算 NSP 损失的一个示例。
9.2.3 训练方案
BERT 及其他早期基于 Transformer 的语言模型是在约 33 亿词的语料上训练的(该语料由英文维基百科和一个名为 BooksCorpus 的书籍文本语料库(Zhu 等,2015)组成;后者因知识产权原因现已不再使用)。 如今的掩码语言模型则在规模大得多的网络文本数据集上进行训练——这些数据经过一定过滤,并辅以维基百科等高质量数据,与第 8 章中讨论的因果型大语言模型所用数据类似。 多语言模型同样使用网络文本和多语言维基百科。 例如,XLM-R 模型使用来自 Common Crawl(https://commoncrawl.org/)的网络数据,在 100 种语言中训练了约 3000 亿个词元。
在原始 BERT 模型的训练中,按照下一句预测任务的 50/50 方案,从训练语料中选取文本段对。
这些段对被采样时需满足:合并后的总长度小于 512 个词元。
随后,对这些句子对中的词元采用 MLM 方法进行掩码,并将 MLM 和 NSP 目标的损失相加,构成最终的联合损失。
由于该最终损失会通过整个 Transformer 进行反向传播,因此每一层的嵌入都会学习到有助于根据邻近词预测当前词的表示。
又因为 [CLS] 标记是 NSP 分类器的直接输入,其学习到的表示往往会包含整个序列的全局信息。
模型大约需要对训练数据遍历 40 轮(epochs)才能收敛。
某些模型(如 RoBERTa)舍弃了下一句预测目标,因而对训练方案做了些许调整。
它们不再采样句子对,而是直接将一系列连续的句子作为输入(仍以特殊标记 [CLS] 开头)。
如果当前文档在达到 512 个词元前结束,则添加一个额外的分隔符,并继续从下一个文档中拼接句子,直到填满 512 个词元为止。
此类训练通常使用较大的批次规模,一般在 8K 到 32K 个词元之间。
多语言模型还需做出一项额外决策:应使用哪些数据来构建词表? 回想一下,所有语言模型都采用子词分词方法(BPE 或 SentencePiece Unigram LM 是两种最常用的算法)。 那么,在学习这种多语言分词时,应使用哪些文本?毕竟某些语言(如英语)的可用文本远多于其他语言。 一种选择是从训练数据(例如 Common Crawl 的网络文本)中随机采样句子来构建词表学习数据集。 但这样会导致大量样本来自网络资源丰富的语言(如英语),从而使词表偏向于英语中较罕见的子词,而非为低资源语言生成高频、有效的子词。 因此,更常见的做法是:将训练数据划分为 N 种语言的子语料库,计算每种语言 $i$ 的句子数量 $n_i$,然后重新调整采样概率,以提升低资源语言的采样权重(Lample 和 Conneau,2019)。 设语言 $i$ 的原始频率为 $n_i$,则调整后从各语言中采样句子的新概率 $\{q_i\}_{i=1,\dots,N}$ 定义为:
$$ q_i = \frac{p_i^\alpha}{\sum_{j=1}^N p_j^\alpha} \quad \text{其中} \quad p_i = \frac{n_i}{\sum_{k=1}^N n_k} \tag{9.5} $$回顾第 5 章公式 (5.19),当 $\alpha$ 取值在 0 到 1 之间时,会提高低频样本的权重。 Conneau 等人(2020)表明,取 $\alpha = 0.3$ 能有效提升稀有语言在分词中的参与度,从而整体改善多语言模型的性能。
这一预训练过程的产物包括学习得到的词嵌入,以及用于为新输入生成上下文嵌入的双向编码器的所有参数。
在许多应用场景中,预训练的多语言模型比单语模型更为实用,因为它避免了为每种语言(可能多达上百种!)分别构建独立模型的开销。 此外,多语言模型还能通过利用训练数据中资源较丰富且语言相近的语言所提供的语言学信息,提升低资源语言的性能。 然而,当语言数量变得非常庞大时,多语言模型会表现出所谓的“多语言诅咒”(curse of multilinguality)(Conneau 等,2020):每种语言上的性能均会劣于在较少语言上训练的模型。 另一个问题是,多语言模型“带有口音”(have an accent):高资源语言(通常是英语)的语法结构会“渗透”到低资源语言中;由于训练数据中英语占比极大,模型对低资源语言的表示会略微偏向英语化(Papadimitriou 等,2023)。
BERT 家族中的另一个成员 ELECTRA(Clark 等,2020b)则通过判别式任务实现了对所有输入词元的利用,从而提升了训练效率。 ↩︎