我们首先介绍双向 Transformer 编码器,这是 BERT 及其后续模型(如 RoBERTa(Liu 等,2019)或 SpanBERT(Joshi 等,2020))的基础。 第 7 章中我们介绍了从左至右的语言模型,应用于问答或摘要等自回归式上下文生成任务,第 8 章则展示了如何使用因果型(从左至右)的 transformer 实现语言模型。 然而,这类模型从左至右的特性也构成了一种限制:在某些任务中,处理某个词元(token)时若能“窥视”其未来的词元将大有裨益。 这一点在序列标注(sequence labeling)任务中尤为明显,在这些任务中,我们希望为每个词元打上标签,如 9.5 节将要介绍的的命名实体识别(named entity tagging),或如后续章节将介绍的词性标注或句法分析。
本节所介绍的双向编码器与因果模型属于截然不同的类型。 第 8 章中的因果模型是生成式模型,旨在高效地生成序列中的下一个词元。 而双向编码器的核心目标则是计算输入词元的上下文化表示(contextualized representations)。 双向编码器利用自注意力机制,将输入嵌入序列 $(x_1, \dots, x_n)$ 映射为长度相同的输出嵌入序列 $(h_1, \dots, h_n)$,其中每个输出向量均融合了整个输入序列的信息,从而实现上下文化。 这些输出嵌入构成了各输入词元的上下文相关表示,在各类需要基于上下文对词元进行分类或决策的应用中具有广泛用途。
回顾一下,我们在前文提到,第 8 章的模型有时被称为仅解码器(decoder-only)模型,因为它们对应于第 12 章将要介绍的编码器–解码器架构中的解码器部分。 相比之下,本章所讨论的掩码语言模型则常被称为仅编码器(encoder-only)模型,因为它们为每个输入词元生成编码表示,但通常不用于通过解码或采样来生成连贯文本。 这一点至关重要:掩码语言模型并不用于文本生成,而是主要用于解释性任务(interpretative tasks)。
9.1.1 双向掩码模型的架构
我们首先讨论整体架构。 基于 Transformer 的双向语言模型与前几章介绍的因果型 Transformer 在两个方面有所不同。 第一,注意力机制是非因果的,词元 $i$ 的注意力可以关注其后续词元(如 $i+1$ 等); 第二,其训练方式略有不同,因为我们预测的是文本中间的某个词元,而非序列末尾的下一个词元。 本节先讨论第一点,第二点将在下一节展开。
图 9.1a(此处复用自第 8 章)展示了第 8 章中从左至右方法的信息流。 在该方法中,每个词元的注意力计算仅基于其前面及当前的输入词元,忽略了位于当前词元右侧的潜在有用信息。 双向编码器通过允许注意力机制遍历整个输入序列,克服了这一限制,如图 9.1b 所示。
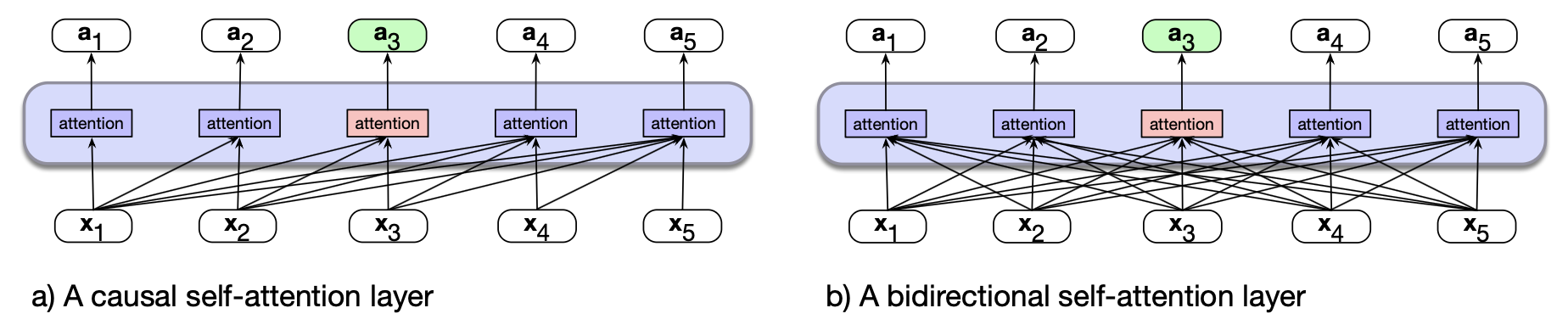
图 9.1 (a) 第 8 章中的因果型 Transformer,突出显示词元 3 处的注意力计算。每个词元的注意力值仅使用上下文中先前出现的信息进行计算。 (b) 双向注意力模型中的信息流。在处理每个词元时,模型可同时关注其前后所有输入词元。因此,词元 3 的注意力可以利用后续词元的信息。
实现方式其实非常简单! 我们只需移除第 8 章公式 (8.33) 中引入的注意力掩码步骤即可。 回顾第 8 章可知,为了确保因果 Transformer 不“窥视”未来词元,我们必须对 $\mathbf{QK}^\top$ 矩阵施加掩码(以下公式重复自 8.34,针对单个注意力头):
$$ \mathbf{head} = \text{softmax}\left(\text{mask}\left(\frac{\mathbf{QK}^\top}{\sqrt{d_k}}\right)\right)\mathbf{V} \tag{9.1} $$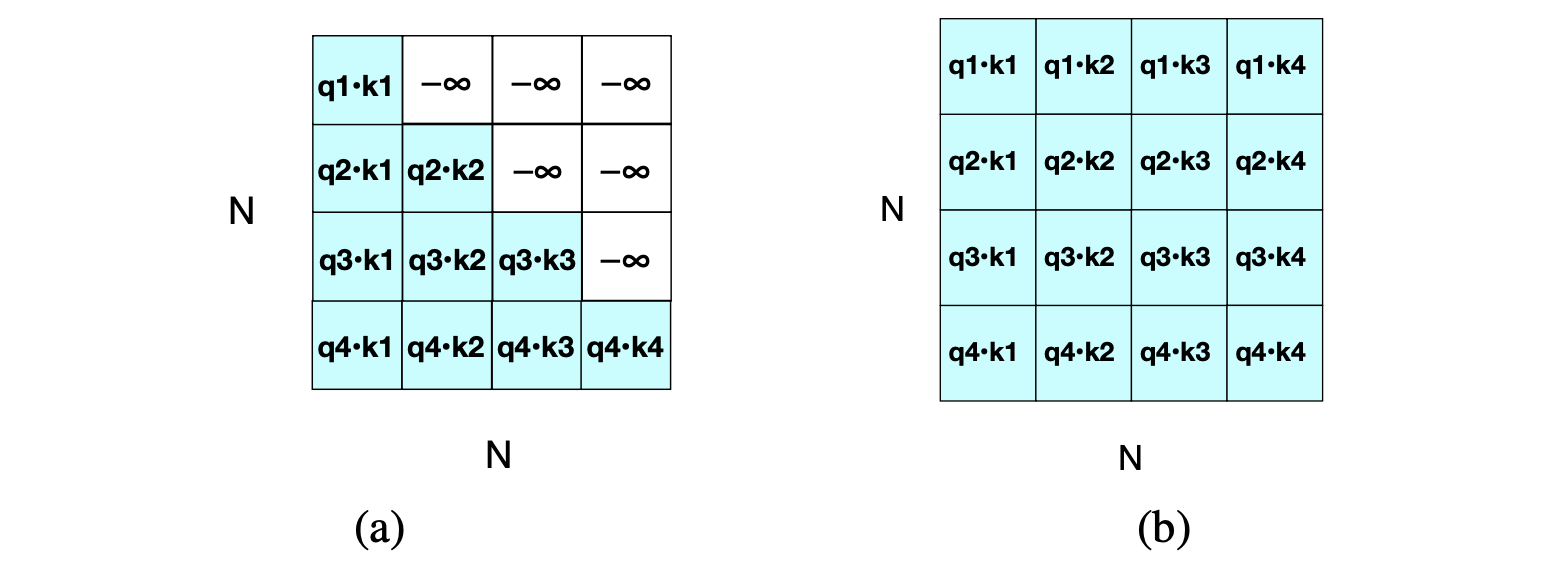
图 9.2 $N \times N$ 的 $\mathbf{QK}^\top$ 矩阵,其中元素为 $q_i \cdot k_j$。 (a) 显示矩阵的上三角部分被置零(实际设为 $-\infty$,经 softmax 后变为 0); (b) 显示未加掩码的完整版本。
图 9.2 展示了带掩码和不带掩码的 $\mathbf{QK}^\top$ 版本。 对于双向注意力,我们采用图 9.2b 中未掩码的版本。 因此,双向注意力的计算与公式 (9.1) 完全相同,只是去除了掩码:
$$ A = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right) V \tag{9.2} $$除此之外,注意力计算与第 8 章完全一致,Transformer 块的架构(包括前馈层、层归一化等)也保持不变。 与第 8 章一样,输入仍是一系列子词(subword),通常由三种主流分词算法之一生成:第 2 章已介绍过的 BPE(Byte Pair Encoding);WordPiece 算法;SentencePiece Unigram LM** 算法。 这意味着每个输入句子首先需要经过词元化处理,后续所有操作均作用于子词词元而非完整单词。 正如本书第三部分将要讨论的那样,对于某些依赖“词”概念的 NLP 任务(如句法分析),我们有时需要将子词重新映射回原始单词。
为使上述内容更具体,最初的英文双向 Transformer 编码器模型 BERT(Devlin 等,2019)具有以下配置:
- 使用 WordPiece 算法(Schuster 和 Nakajima, 2012)构建的英文专用子词词表,共 30,000 个词元;
- 输入上下文窗口长度 $N = 512$ 个词元,模型维度 $d = 768$;
- 因此模型输入 $\mathbf{X}$ 的形状为 $[N \times d] = [512 \times 768]$;
- 包含 $L = 12$ 层 Transformer 块,每层包含 $A = 12$ 个(双向)多头注意力头;
- 整体参数量约为 1 亿。
而更大规模的多语言模型 XLM-RoBERTa(在 100 种语言上训练)则具有:
使用 SentencePiece Unigram LM 算法(Kudo 和 Richardson,2018b)生成的、包含 250,000 个词元的多语言子词词汇表;
24 层 Transformer 块,每层包含 16 个多头注意力头;
隐藏层维度为 1024;
输入上下文窗口长度为 512 个词元;
模型总参数量约为 5.5 亿(550M)。
使用 SentencePiece Unigram LM 算法(Kudo 和 Richardson, 2018b)生成的多语言子词词表,共 250,000 个词元;
输入上下文窗口 $N = 512$,模型维度 $d = 1024$,故输入 $\mathbf{X}$ 的形状为 $[512 \times 1024]$;
$L = 24$ 层 Transformer 块,每层含 $A = 16$ 个多头注意力头;
总参数量约为 5.5 亿。
需注意的是,以当前大语言模型的标准来看,5.5 亿参数的规模相对较小(例如 Llama 3 拥有 4050 亿参数,比它大三个数量级)。 事实上,掩码语言模型通常远小于因果语言模型。
需要注意的是,5.5 亿参数在当今的大语言模型中其实相对较小(例如 Llama 3 拥有 4050 亿参数,比它大三个数量级)。 事实上,掩码语言模型(如 BERT)通常比因果语言模型小得多。