大语言模型确实非常庞大。 例如,Meta 发布的 Llama 3.1 405B Instruct 模型拥有 4050 亿参数(共 126 层,模型维度为 16,384,128 个注意力头),并在 15.6 TB 的文本词元上进行训练(Llama Team, 2024),使用了大小为 128K 的词汇表。 因此,学术界和工业界投入了大量研究来理解 LLM 的扩展规律,尤其是如何在有限计算资源下高效实现和部署这些模型。 在接下来几节中,我们将讨论如何思考模型规模问题(即“扩展定律”,scaling laws),以及一些关键的高效技术,如 KV 缓存(KV cache)和参数高效微调(parameter-efficient fine-tuning)。
8.8.1 扩展定律
研究表明,大语言模型的性能主要由三个因素决定:模型规模(参数量,通常不包括嵌入层参数);数据集规模(训练数据总量);训练所用的计算量(compute budget)。 换句话说,我们可以通过以下任一方式提升模型性能:增加参数(增加层数、扩大上下文或两者兼有);使用更多训练数据;增加训练迭代次数(即投入更多算力)。
这些因素与模型性能之间的关系被称为 扩展定律(scaling laws)。 粗略地说,大语言模型的性能(以损失 $L$ 衡量)与上述三个训练属性均呈幂律关系(power-law relationship)。
例如,Kaplan 等人(2020)发现,在其他两个因素保持不变的前提下,当分别受限于模型规模、数据量或计算预算时,损失 $L$ 与(非嵌入部分的)参数数量 $N$、数据集大小 $D$ 和计算预算 $C$ 的存在如下三种关系:
$$ L(N) = \left( \frac{N_c}{N} \right)^{\alpha_N} \tag{8.49} $$$$ L(D) = \left( \frac{D_c}{D} \right)^{\alpha_D} \tag{8.50} $$$$ L(C) = \left( \frac{C_c}{C} \right)^{\alpha_C} \tag{8.51} $$非嵌入参数总数 $N$ 可大致按如下方式估算(忽略偏置项,并设 $d$ 为模型输入/输出维度,$d_{\text{attn}}$ 为自注意力层维度,$d_{\text{ff}}$ 为前馈网络维度):
$$ \begin{align*} N &\approx 2 d \, n_{\text{layer}} (2 d_{\text{attn}} + d_{\text{ff}}) \\ &\approx 12 \, n_{\text{layer}} \, d^2 \\ &\quad \text{(假设 } d_{\text{attn}} = d_{\text{ff}}/4 = d \text{)} \tag{8.52} \end{align*} $$例如,GPT-3 有 $n_{\text{layer}} = 96$ 层,维度 $d = 12288$,则其参数量约为 $12 \times 96 \times 12288^2 \approx 1750 \text{ 亿}$
常数 $N_c, D_c, C_c$ 和指数 $\alpha_N, \alpha_D, \alpha_C$ 的具体值取决于具体的 Transformer 架构、词元化方式和词汇表大小。 因此,扩展定律的重点不在于精确数值,而在于揭示损失随规模变化的趋势1。
扩展定律在实践中非常有用。例如通过观察训练早期的损失曲线,或在小规模数据/模型上的性能,可以预测如果增加数据量或扩大模型,最终损失会是多少。 它还能指导我们:当模型规模扩大时,需要同步增加多少训练数据才能达到最优性能(避免“过拟合”或“欠训练”)。
8.8.2 KV 缓存(KV Cache)
我们在图 8.10 和公式 8.32(如下重述)中看到,在训练阶段,注意力向量可以通过两次矩阵乘法高效并行计算:
$$ \mathbf{A} = \mathrm{softmax}\left( \frac{\mathbf{QK}^\top}{\sqrt{d_k}} \right) \mathbf{V} \tag{8.53} $$然而,在推理阶段(inference),我们无法像训练时那样进行同样高效的并行计算。 原因在于:推理时我们是逐个生成词元的,每次只生成下一个词元。 假设我们刚刚生成了一个新词元 $x_i$,我们需要分别用权重矩阵 $\mathbf{W^Q}$、$\mathbf{W^K}$ 和 $\mathbf{W^V}$ 计算它的查询(Query)、键(Key)和值(Value)向量。 但如果我们每次都重新计算所有先前词元(即 $x_{< i}$),那就太浪费了,因为这些词元的 Key 和 Value 向量在之前的推理步骤中已经计算过! 因此,我们采用一种优化策略:每当计算出某个词元的 Key 和 Value 向量后,就将它们保存在内存中的 KV 缓存(KV cache)。后续生成新词元时,只需从缓存中直接读取这些已计算好的 Key 和 Value,而无需重复计算。 图 8.17 修改自图 8.10,展示了在生成单个新词元时的实际计算过程,并用黑色标出了哪些向量可以从缓存中复用,而无需重新计算。
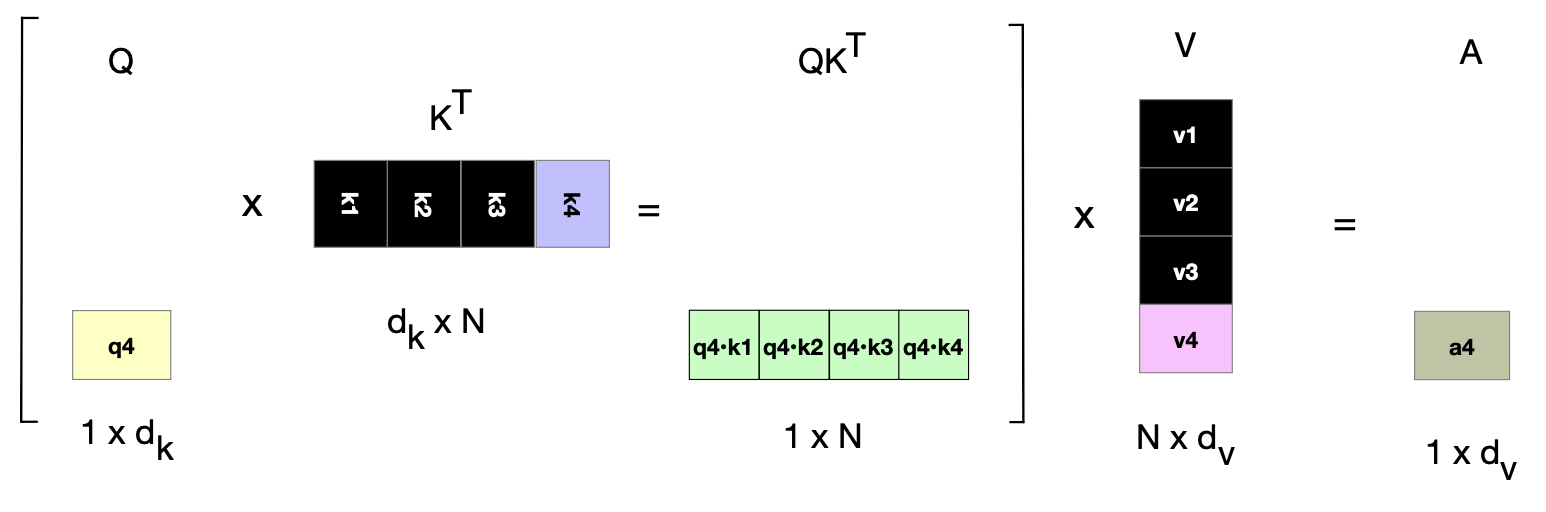
图 8.17 注意力计算的部分流程(摘自图 8.10),以黑色标出在计算第 4 个词元的注意力分数时,可以从缓存中直接获取(而非重新计算)的 Key 和 Value 向量。
8.8.3 参数高效微调
如上所述,通过微调(finetuning)将语言模型适应于新领域是非常常见的做法,即在额外的数据集上继续训练模型以预测即将出现的词汇。
对于非常大的语言模型而言,微调可能会极其困难,因为存在大量的参数需要训练;每次批量梯度下降的过程都需要反向传播通过许多巨大的层。 这使得对大型语言模型进行微调在计算能力、内存和时间方面都非常昂贵。 因此,有一些替代方法允许在不调整所有参数的情况下对模型进行微调。 这类方法被称为参数高效的微调或有时称为PEFT,因为我们高效地选择了一部分参数在微调过程中更新。 例如,我们可以冻结一些参数(不改变它们),只更新某些特定的参数子集。
这里我们描述了这样一种模型,称为LoRA,代表低阶适配(Low-Rank Adaptation)。LoRA 的基本思想是,transformers 模型中有很多执行矩阵乘法的密集层(例如注意力计算中的 $\mathbf{W_Q}$、$\mathbf{W_K}$、$\mathbf{W_V}$、$\mathbf{W_O}$ 层)。 微调过程中,不是更新这些层,而是而是采用 LoRA 方法:将原始权重冻结,并转而训练一个参数量更少的低秩近。
考虑一个维度为 $[N \times d]$ 的矩阵 $\mathbf{W}$,在微调过程中需通过梯度下降更新。 通常情况下,这个矩阵会得到维度为 $[N \times d]$ 的更新 $\delta \mathbf{W}$,用于梯度下降后更新 $N \times d$ 个参数。 在 LoRA 中,我们冻结 $\mathbf{W}$ 并改为更新 $\mathbf{W}$ 的低秩分解。 我们创建两个矩阵 $\mathbf{A}$ 和 $\mathbf{B}$,其中 $\mathbf{A}$ 的大小为 $[N \times r]$,$\mathbf{B}$ 的大小为 $[r \times d]$,并且我们选择 $r$ 相当小,满足 $r << min(d,N)$。 在微调期间,我们更新的是 $\mathbf{A}$ 和 $\mathbf{B}$ 而不是 $\mathbf{W}$。 也就是说,我们将 $\mathbf{W} + \delta \mathbf{W}$ 替换为 $\mathbf{W} + \mathbf{BA}$。 图 8.18 展示了这一思想。 对于替换前向传递 $\mathbf{h} = \mathbf{xW}$,新的前向传递变为:
$$ \mathbf{h} = \mathbf{xW} + \mathbf{xAB} \tag{8.54} $$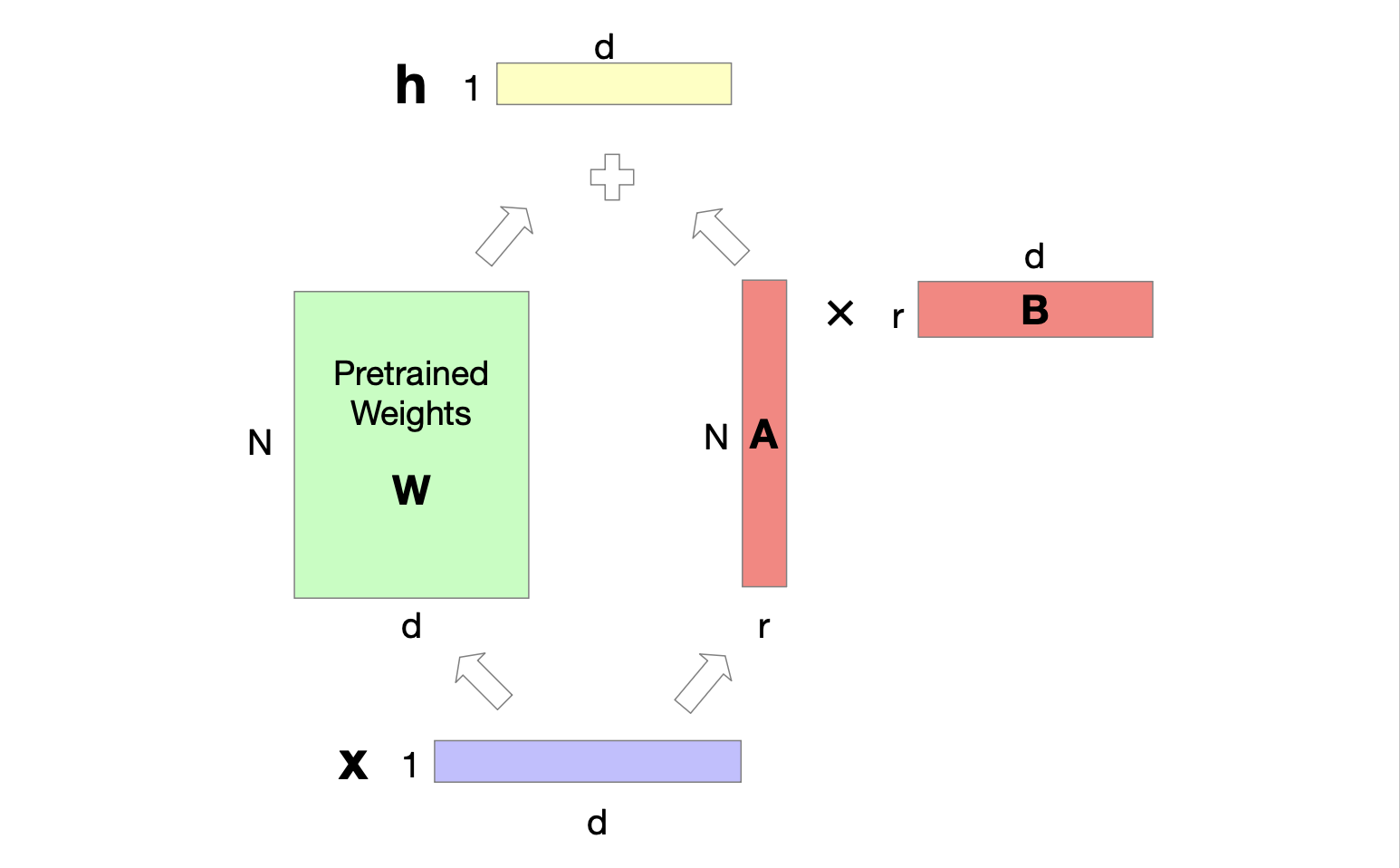
图 8.18 LoRA 的原理展示。我们将 $\mathbf{W}$ 固定为其预训练值,并通过训练一对矩阵 $\mathbf{A}$ 和 $\mathbf[B]$ 进行微调,更新这些矩阵而不是 $\mathbf{W}$,只需将 $W$ 与更新后的 $\mathbf{AB}$ 相加即可。
LoRA 具有许多优势。它显著减少了硬件需求,因为不需要为大多数参数计算梯度。 由于 $\mathbf{AB}$ 的大小与 $\mathbf{W}$ 相同,权重更新可以简单地添加到预训练权重中。 这意味着它不会增加推理时间。 这也意味着可以为不同的领域构建 LoRA 模块,并通过将其添加到或从 $\mathbf{W}$ 中减去来轻松交换使用。
在其原始版本中,LoRA 仅应用于注意力计算中的矩阵(即 $\mathbf{W_Q}$、$\mathbf{W_K}$、$\mathbf{W_V}$ 和 $\mathbf{W_O}$ 层)。 目前存在多种 LoRA 的变体。
Kaplan 等人(2020)初始实验中的具体参数为:$\alpha_N = 0.076$,$N_c = 8.8 \times 10^{13}$(参数),$\alpha_D = 0.095$,$D_c = 5.4 \times 10^{13}$(词元),$\alpha_C = 0.050$,$C_c = 3.1 \times 10^8$(petaflop-days)。 ↩︎