我们在前一章已经介绍了语言模型的训练过程。 回顾一下:*语言模型通常使用交叉熵损失,也称为负对数似然损失(negative log likelihood loss)。 在时间步 $t$,交叉熵损失等于模型对训练序列中下一个词所分配概率的负对数:$-\log p(w_{t+1})$
图 8.16 展示了通用的训练方法。 在每一步中,给定所有前置词元,Transformer 的最后一层会输出一个覆盖整个词汇表的概率分布。 训练时,模型为正确下一个词分配的概率被用于计算序列中每个位置的交叉熵损失。 一条训练序列的总损失是其所有位置上交叉熵损失的平均值。 随后,通过梯度下降法调整网络中的所有参数,以最小化该序列上的平均交叉熵损失。
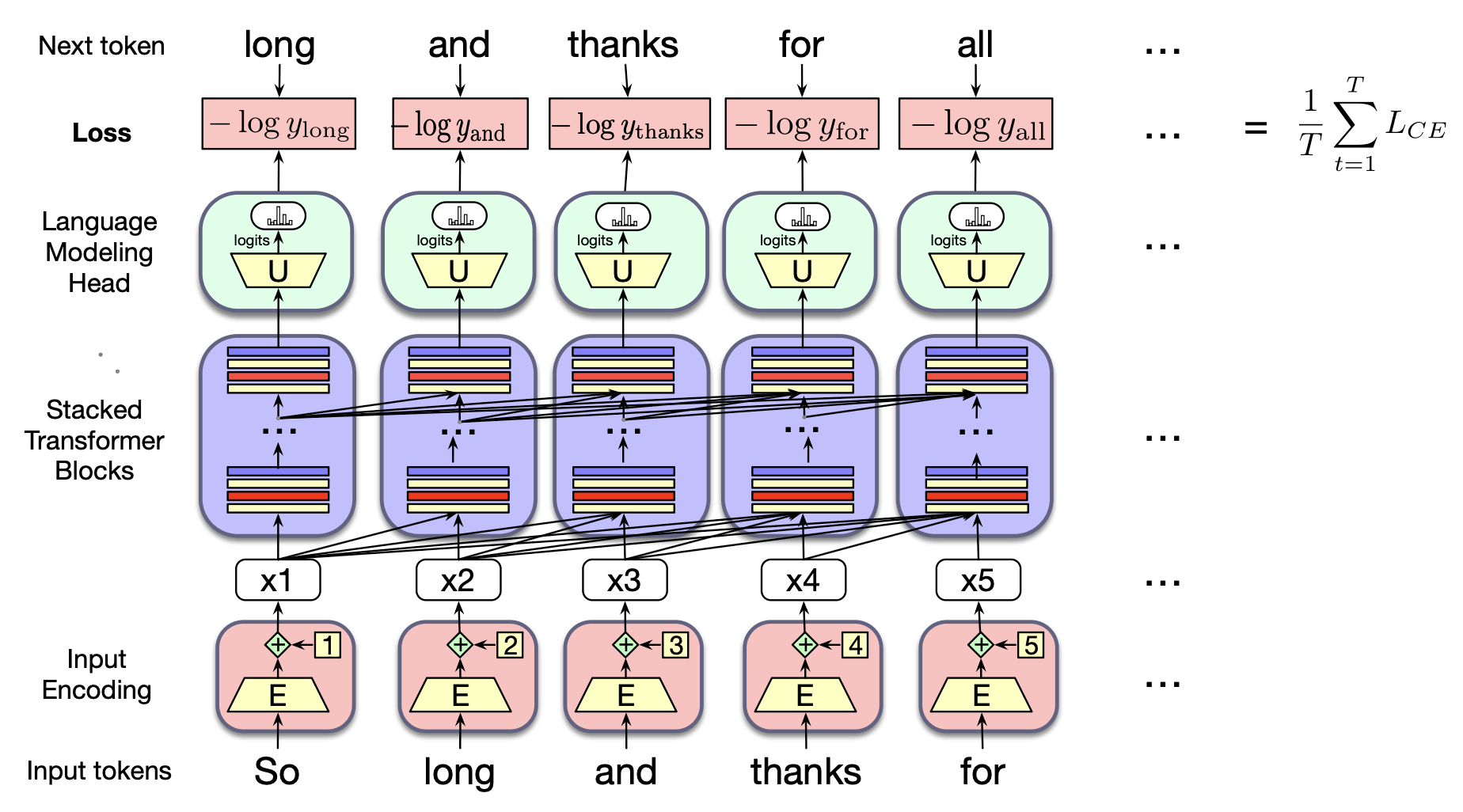
图 8.16 将 Transformer 作为语言模型进行训练。
在 transformer训练阶段,序列中的每个位置可以并行处理,因为序列中每个元素的输出是独立计算的。
大型模型通常会填满整个上下文窗口进行训练。例如 GPT-4 使用 4096 个词元的上下文窗口,Llama 3 则使用 8192 个词元。
如果单个文档长度不足,系统会将多个文档拼接(packed)到同一个窗口中,并在文档之间插入特殊的文本结束符(end-of-text token)。 此外,梯度下降所用的批大小(batch size)通常非常大。例如,GPT-3 最大的模型版本使用了高达 320 万词元。