我们必须介绍的 Transformer 最后一个组件是语言建模头部(language modeling head)。 这里所说的“头部”(head),是指在将预训练的 Transformer 模型应用于各种任务时,附加在基础 Transformer 架构顶部的额外神经网络结构。 而语言建模头部,正是我们进行语言建模任务所需的特定结构。
回顾一下:从第 3 章的简单 n-gram 模型,到第 6 章和第 13 章的前馈神经网络与循环神经网络(RNN)语言模型,语言模型本质上都是词元预测器。
给定一段上下文词序列,它们会为每一个可能的下一个词分配一个概率。
例如,如果前面的上下文是 Thanks for all the,我们想知道下一个词是 fish 的可能性有多大,就会计算:
P(fish | Thanks for all the)
语言模型能够为词汇表中每一个可能的下一个词都给出这样一个条件概率,从而形成一个完整的概率分布。 第 3 章中的 n-gram 语言模型通过统计目标词与其前 $n-1$ 个词共同出现的频次来计算概率。 因此其上下文长度固定为 $n-1$。 而 Transformer 语言模型的上下文长度则等于其上下文窗口大小,可以非常大,例如大型模型通常支持 32K 个词元的上下文。借助特殊的长上下文架构(如稀疏注意力、记忆机制等),甚至可扩展至数百万词元。
语言建模头部的任务是:取最后一层 Transformer 对最后一个输入词元(位置 $N$)的输出,并用它来预测位置 $N+1$ 处的下一个词元。 图 8.14 展示了如何完成这一任务:输入是最后一层中最后一个词元的输出嵌入(一个形状为 $[1 \times d]$ 的 $d$ 维向量),输出是一个覆盖整个词汇表的概率分布(从中我们可以选择一个词元用于生成)。
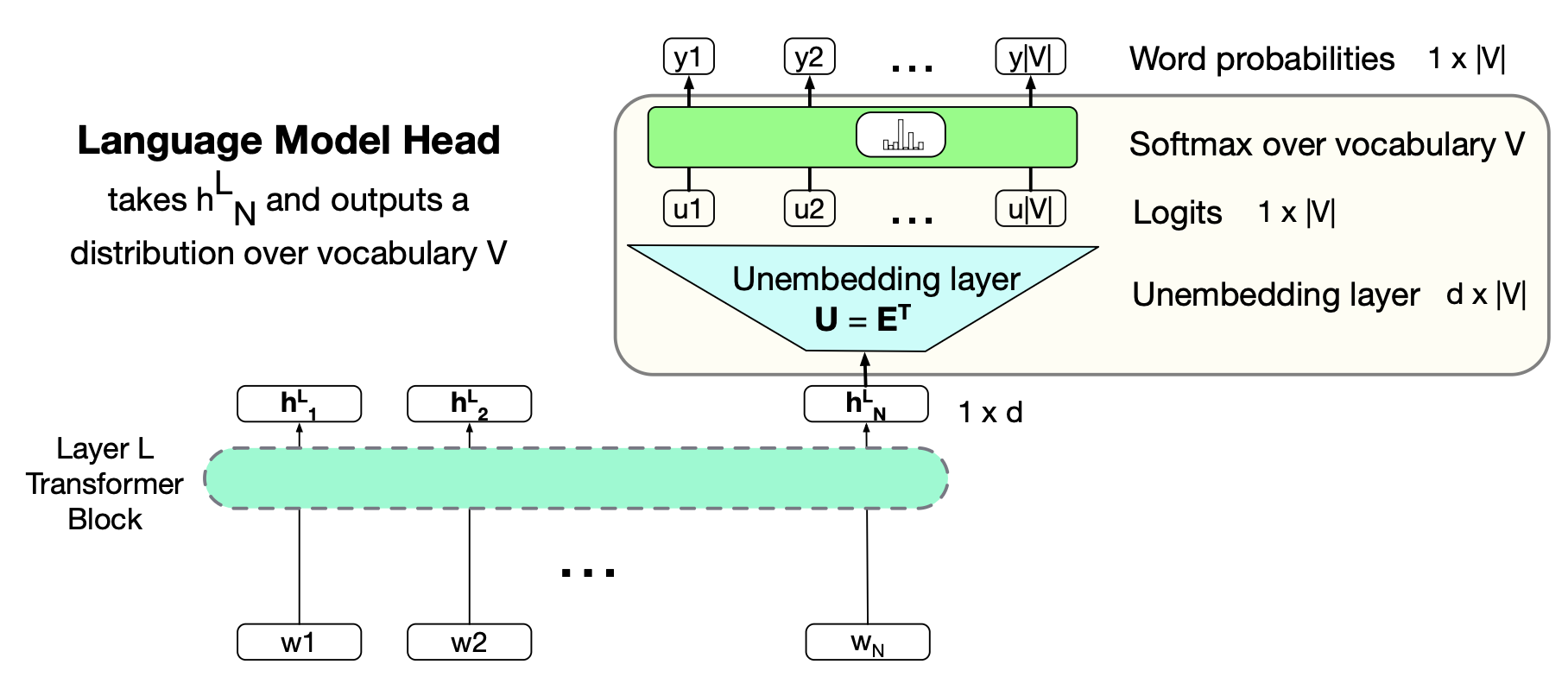
图 8.14 语言建模头部:位于 Transformer 顶部的结构,将最后一层对词元 $N$ 的输出嵌入 $h^L_N$ 映射为词汇表 $V$ 上的概率分布。
图 8.14 中的第一个模块是一个线性层(linear layer),其作用是将来自最后一层 $L$ 的输出 $h^L_N$(即位置 $N$ 处的输出词元嵌入,形状为 $[1 \times d]$)投影到一个 logit 向量(也称为得分向量)。该 logit 向量为词汇表 $V$ 中的每一个可能词元(共 $|V|$ 个)提供一个标量得分。 因此该 logit 向量的维度为 $[1 \times |V|]$,记作 $\mathbf{u}$。
这个线性层的权重可以独立学习,但更常见的做法是将其与嵌入矩阵 $\mathbf{E}$ 绑定(weight tying)。 所谓权重绑定(weight tying),是指在模型中两个不同的地方共享同一组参数。 在 Transformer 的输入端,嵌入矩阵 $\mathbf{E}$(形状为 $[|V| \times d]$)用于将词汇表上的独热向量($[1 \times |V|]$)映射为嵌入向量($[1 \times d]$); 而在语言建模头部,则使用该矩阵的转置 $\mathbf{E}^\top$(形状为 $[d \times |V|]$)将上下文嵌入($[1 \times d]$)映射回词汇表空间($[1 \times |V|]$)。 在训练过程中,嵌入矩阵 $\mathbf{E}$ 会被优化,以同时胜任这两个方向的映射任务。 正因如此,我们有时也将转置矩阵 $\mathbf{E}^\top$ 称为解嵌入层(unembedding layer),因为它执行的是从嵌入空间回到词汇表空间的“逆向”映射。
接下来,一个 softmax 层 将 logit 向量 $\mathbf{u}$ 转换为词汇表上的概率分布 $\mathbf{y}$:
$$ \begin{align*} \mathbf{u} &= \mathbf{h^L_N} \mathbf{E}^\top \tag{8.46} \\ \mathbf{y} &= \mathrm{softmax}(\mathbf{u}) \tag{8.47} \end{align*} $$我们可以利用这些概率完成多种任务,例如计算一段给定文本的整体概率。 但最重要的用途是生成文本:通过从概率分布 $\mathbf{y}$ 中采样(sampling)一个词元来实现。 我们可以选择概率最高的词(即“贪心解码”,greedy decoding),也可以采用第 7.4 节或第 8.6 节将介绍的其他采样策略。
无论采用哪种方式,一旦从概率向量 $\mathbf{y}$ 中选定了某个分量 $y_k$,我们就生成词汇表中索引为 $k$ 的那个词。
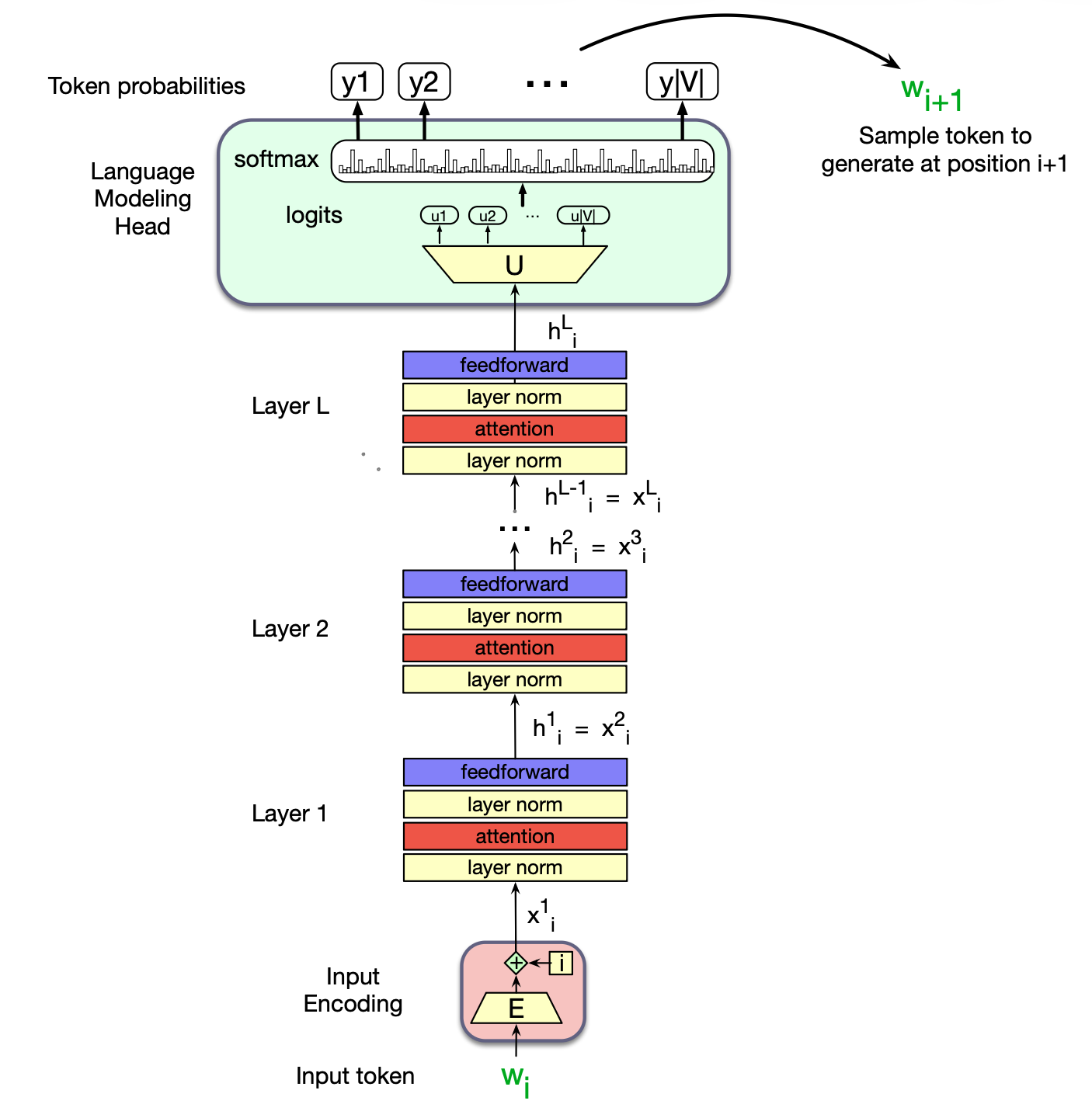
图 8.15 一个 Transformer 语言模型(仅解码器结构):堆叠多个 Transformer 块,将输入词元 $w_i$ 映射为预测的下一个词元 $w_{i+1}$。
图 8.15 展示了针对单个词元 $w_i$ 的完整堆叠架构。 注意:每个 Transformer 层的输入 $x^{\ell}_i$ 都等于前一层的输出 $h^{\ell-1}_i$(即残差流逐层传递)。
在结束本节之前,需澄清一个常见术语:你可能会看到这种用于单向因果语言建模(causal language modeling)的 Transformer 被称为 仅解码器模型(decoder-only model)。 这是因为该模型大致对应于我们在第 12 章将要学习的、用于机器翻译的 编码器-解码器(encoder-decoder)Transformer 架构中的解码器部分。 (这里有一点历史上的混淆:原始的 Transformer 论文(Vaswani et al., 2017)提出的是完整的编码器-解码器架构;而后来,人们发现仅使用其中的解码器部分(并加上因果掩码)就足以构建强大的自回归语言模型,这逐渐成为大语言模型的标准范式。)