现在我们来讨论输入矩阵 $\mathbf{X}$ 的来源。 给定一个包含 $N$ 个词元的序列($N$ 即上下文长度,以词元为单位),形状为 $[N \times d]$ 的矩阵 $\mathbf{X}$ 为上下文中的每个词元提供一个嵌入(embedding)。 Transformer 通过分别计算两种嵌入来实现这一点:词元嵌入(token embedding)和位置嵌入(positional embedding)。
词元嵌入在第 6 章中已介绍过,它是一个维度为 $d$ 的向量,作为输入词元的初始表示。 (随着向量在残差流中逐层向上流动,该嵌入表示会不断变化和丰富,融入上下文信息,并根据所构建的语言模型类型承担不同角色。) 所有初始词元嵌入存储在一个嵌入矩阵 $\mathbf{E}$ 中,其每一行对应词汇表中 $|V|$ 个词元中的一个。 (注意:此处的 $V$ 指词汇表(vocabulary),与注意力机制中的值向量 $V$ 无关。) 因此,每个词元由一个 $d$ 维行向量表示,$\mathbf{E}$ 的形状为 $[|V| \times d]$。
例如,对于输入字符串 Thanks for all the,我们首先将其转换为词汇表索引(这些索引是在使用 BPE 或 SentencePiece 等分词器对输入进行分词时生成的)。
假设 thanks for all the 对应的索引序列为 $\mathbf{w} = [5, 4000, 10532, 2224]$。
接着我们通过索引从 $\mathbf{E}$ 中选取对应的行(第 5 行、第 4000 行、第 10532 行、第 2224 行),得到每个词元的嵌入。
另一种理解方式是将词元表示为独热向量,形状为 $[1 \times |V|]$,即每个维度对应词汇表中的一个词元。
在独热向量中,除一个位置为 1(对应词元在词汇表中的索引)外,其余元素均为 0。
例如,若 thanks 在词汇表中的索引为 5,则其独热向量为:
[0 0 0 0 1 0 0 ... 0 0 0 0]
1 2 3 4 5 6 7 ... |V|
将嵌入矩阵 $\mathbf{E}$ 与这样一个仅在第 $i$ 位为 1 的独热向量相乘,结果就是 $\mathbf{E}$ 的第 $i$ 行——即词元 $i$ 的嵌入向量,如图 8.11 所示。
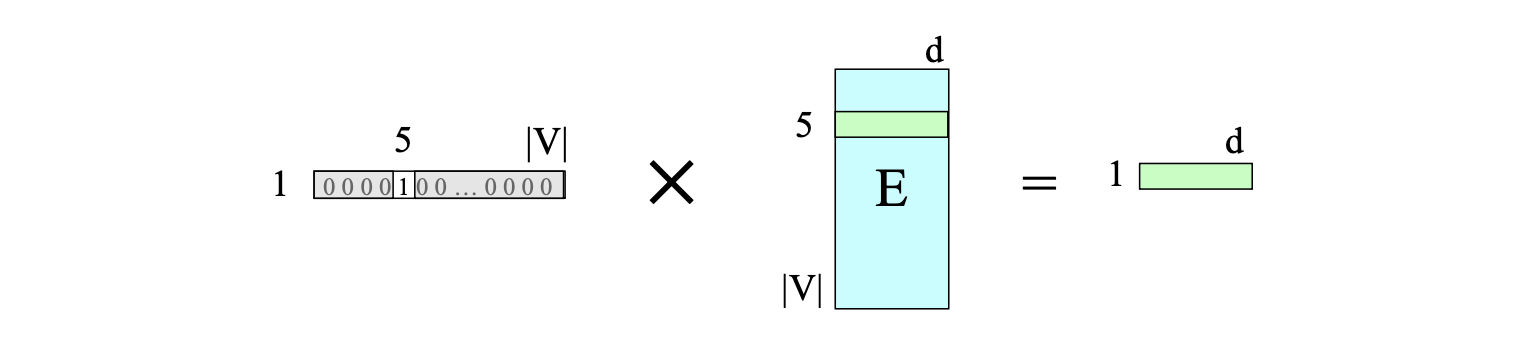
图 8.11 通过将嵌入矩阵 $\mathbf{E}$ 与在索引 5 处为 1 的独热向量相乘,选出词元 $V_5$ 的嵌入向量。
我们可以将这一思想扩展到整个词元序列:将输入序列表示为一个由 $N$ 个独热向量组成的矩阵,每行对应上下文窗口中的一个位置,如图 8.12 所示。
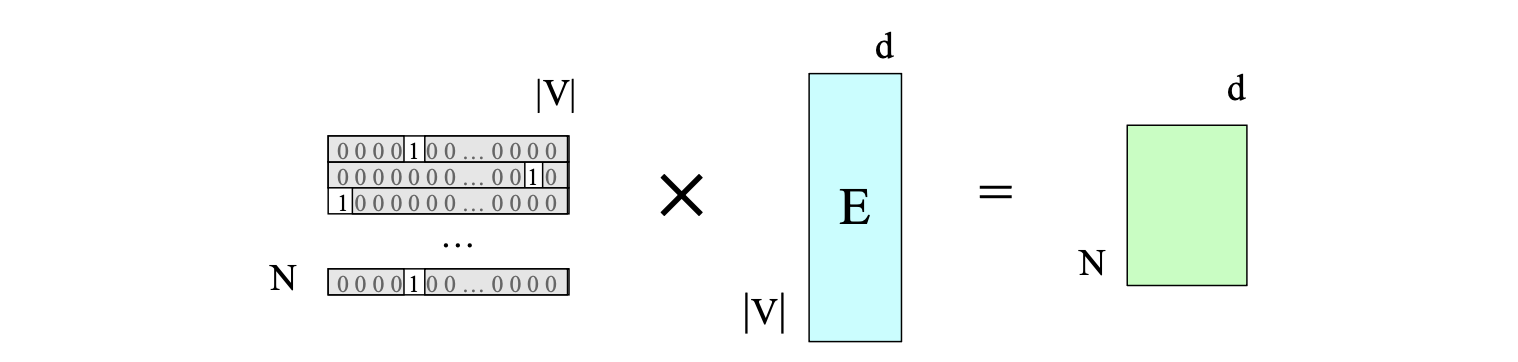
图 8.12 通过将对应于词元 ID 序列 $\mathbf{W}$ 的独热矩阵与嵌入矩阵 $\mathbf{E}$ 相乘,得到输入序列的嵌入矩阵。
上述词元嵌入本身不包含位置信息。 为了表示序列中每个词元的位置,我们需要将词元嵌入与位置嵌入(positional embedding)相结合,后者针对输入序列中的每个位置专门设计。
那么,位置嵌入从何而来?
最简单的方法称为绝对位置编码(absolute position):为从位置 0 到某个最大长度(如 512 或 1024)的每个可能位置初始化一个随机向量。
例如,就像我们有 fish 这个词的嵌入一样,我们也为位置 3 分配一个嵌入。
与词元嵌入类似,这些位置嵌入也在训练过程中与其他参数一起学习。
它们可以存储在一个位置嵌入矩阵 $E_{pos}$中,形状为 $[N \times d]$。
为了生成包含位置信息的输入嵌入,我们只需将每个词元的嵌入与其对应位置的位置嵌入相加。 由于词元嵌入和位置嵌入都是 $[1 \times d]$ 向量,它们的和仍是 $[1 \times d]$ 向量。 这个新嵌入就是下一步处理的输入。 图 8.13 展示了这个思想。
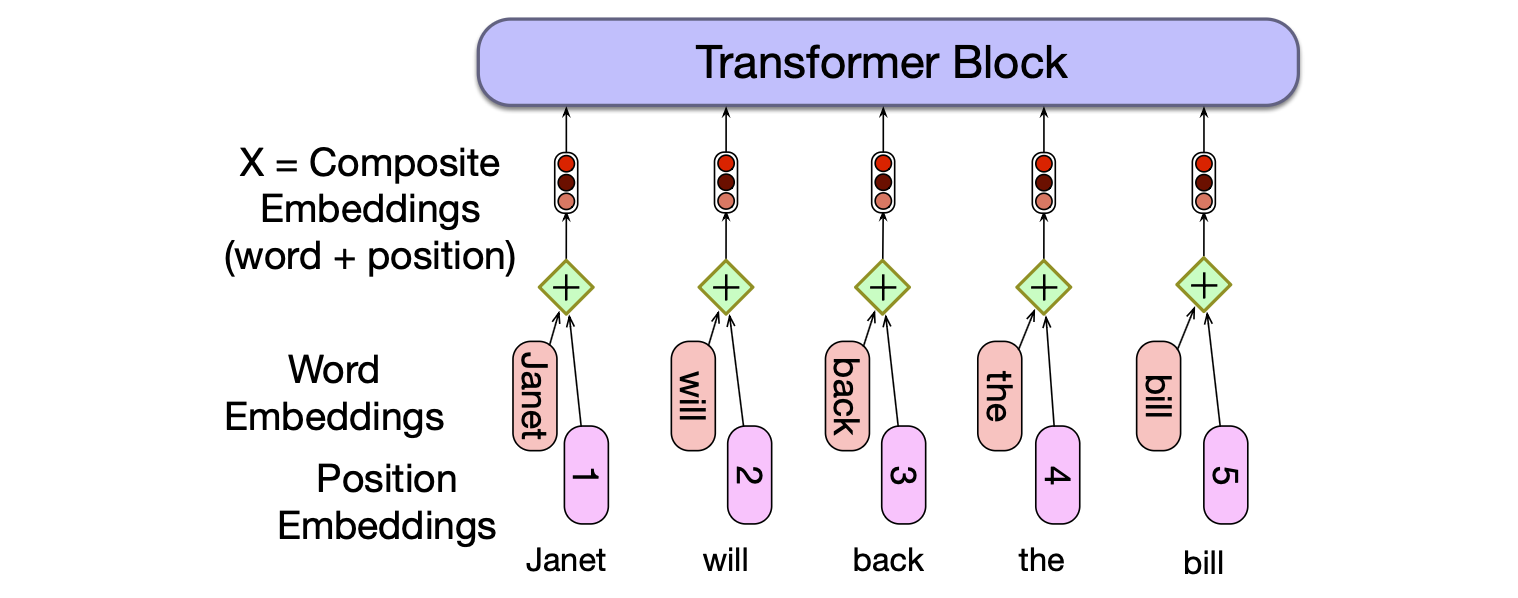
图 8.13 建模位置的一种简单方法:将绝对位置的嵌入加到词元嵌入上,生成相同维度的新嵌入。
最终的输入表示矩阵 $\mathbf{X}$ 是一个 $[N \times d]$ 的矩阵,其中第 $i$ 行是输入中第 $i$ 个词元的表示,计算方式是把位置 $i$ 上词元的嵌入 $\mathbf{E}[\text{id}(i)]$ 和 位置 $i$ 的位置嵌入相加。
简单的位置嵌入方法存在一个潜在问题:训练数据中,序列开头的位置(如位置 0、1、2)出现频率很高,而接近最大长度的位置样本稀少。 这导致靠后的位置嵌入训练不足,在测试时泛化能力较差。 一种替代方案是使用静态函数将整数位置映射为实值向量,从而更好地处理任意长度的序列。 在原始 Transformer 论文中,作者采用了正弦和余弦函数的组合,其频率随维度变化。 这种正弦位置编码(sinusoidal positional encoding)不仅能处理训练中未见过的长序列,还隐式地编码了位置间的相对关系。例如,位置 4 与位置 5 的关系比与位置 17 更近。
更复杂的方案进一步发展了这一思想,不再使用绝对位置,而是直接建模相对位置(relative position)。这类方法通常不在输入端一次性添加位置嵌入,而是在每一层的注意力机制内部显式地引入相对位置信息。