到目前为止,我们对多头注意力及 Transformer 块其余部分的描述,都是从单个残差流中、在单一时间步 $i$ 上计算单个输出的角度出发的。 但如前所述,为每个词元计算 $\mathbf{a}_i$ 的注意力操作彼此独立;同样,整个 Transformer 块中从输入 $\mathbf{x}_i$ 计算 $\mathbf{h}_i$ 的所有操作也都是相互独立的。 这意味着我们可以轻松地将整个计算并行化,充分利用高效的矩阵乘法运算。
具体做法是:将输入序列中 $N$ 个词元的嵌入向量打包成一个大小为 $[N \times d]$ 的矩阵 $\mathbf{X}$,其中每一行对应一个输入词元的嵌入。 大型语言模型中的 Transformer 通常支持的输入长度 $N$ 从 1K 到 32K 不等;通过调整架构,使用特殊的长上下文之类的机制,甚至可处理长达 128K 或数百万词元的上下文。 因此,对于标准(vanilla)Transformer,我们可以认为矩阵 $\mathbf{X}$ 包含 1K 至 32K 行,每行维度为嵌入维度 $d$(即模型维度)。
并行化注意力计算
我们先从单个注意力头开始,再扩展到多头,最后加入 Transformer 块中的其他组件。 对于单个头,我们将输入矩阵 $\mathbf{X}$ 分别与查询、键、值权重矩阵相乘:$\mathbf{W}^{\mathbf{Q}}$ 形状为 $[d \times d_k]$,$\mathbf{W}^{K}$ 形状为 $[d \times d_k]$,$\mathbf{W}^{V}$ 形状为 $[d \times d_v]$,从而得到三个矩阵:$\mathbf{Q} \in \mathbb{R}^{N \times d_k}$ 包含所有查询向量,$\mathbf{K} \in \mathbb{R}^{N \times d_k}$ 包含所有键向量,$\mathbf{V} \in \mathbb{R}^{N \times d_v}$ 包含所有值向量:
$$ \begin{align*} \mathbf{Q} &= \mathbf{X} \mathbf{W^Q}; \\ \mathbf{K} &= \mathbf{X} \mathbf{W^K}; \\ \mathbf{V} &= \mathbf{X} \mathbf{W^V} \tag{8.32} \end{align*} $$有了这些矩阵后,我们可以通过一次矩阵乘法 $\mathbf{Q} \mathbf{K}^\top$ 同时完成所有查询-键的点积比较。 结果是一个 $N \times N$ 的矩阵,如图 8.8 所示。
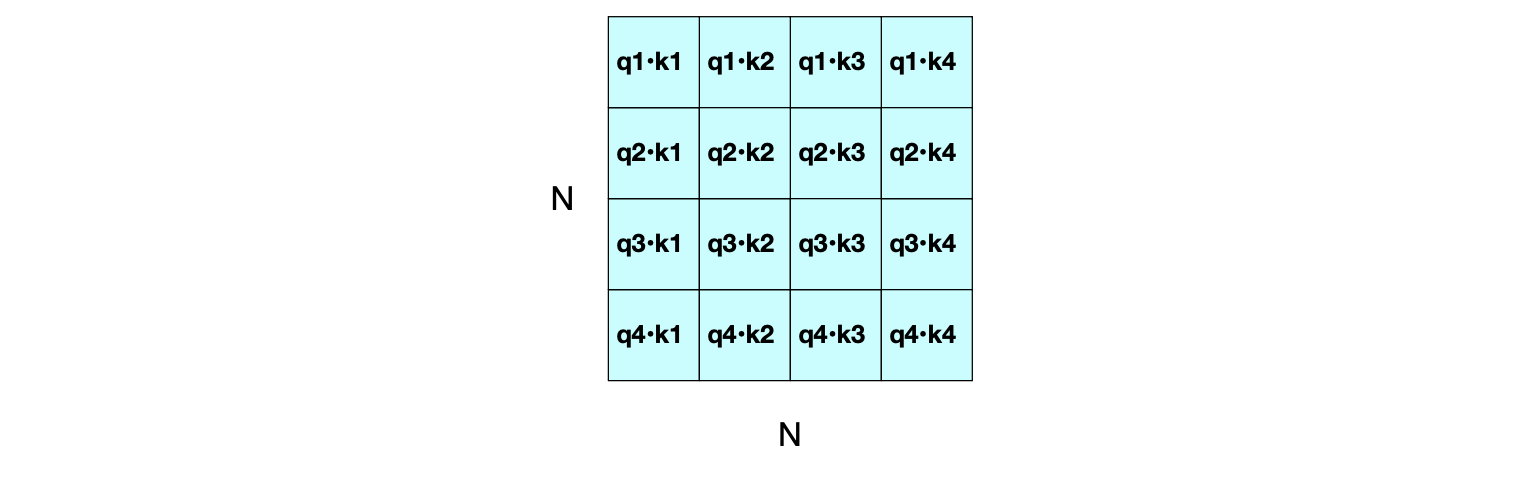
图 8.8 $N \times N$ 的 $\mathbf{QK^T}$ 矩阵,展示了如何通过一次矩阵乘法同时计算所有 $\mathbf{q}_i \cdot \mathbf{k}_j$ 的相似度。
一旦得到 $\mathbf{QK^T}$ 矩阵,我们便可高效地对得分进行缩放(除以 $\sqrt{d_k}$),应用 softmax 得到注意力权重,将结果与 $\mathbf{V}$ 相乘,得到形状为 $N \times d_v$ 的输出矩阵——即每个输入词元对应的加权值表示。 这样,我们就将整个序列(共 $N$ 个词元)在一个注意力头中的自注意力计算简化为以下形式:
$$ \begin{align*} \mathbf{head} &= \mathrm{softmax}\left( \mathrm{mask}\left( \frac{\mathbf{QK^T}}{\sqrt{d_k}} \right) \right) \mathbf{V} \tag{8.33} \\ \mathbf{A} &= \mathbf{head} \, \mathbf{W^O} \tag{8.34} \end{align*} $$屏蔽未来信息(Masking out the future)
你可能注意到,我们在上面的公式 (8.33) 中引入了一个 mask(掩码)函数。 这是因为,如前所述的自注意力计算存在一个问题:$\mathbf{QK}^\top$ 的计算会为每个查询向量与所有键向量(包括序列中位于它之后的词元)生成相似度得分。
这在语言建模任务中是不合适的——如果你已经知道下一个词是什么,那预测它就毫无意义了! 为了解决这个问题,我们需要屏蔽掉未来的信息:将矩阵中上三角部分(即 $j > i$ 的位置)的值设为 $-\infty$,从而彻底消除对后续词元的依赖。 在实践中,这是通过添加一个掩码矩阵 $\mathbf{M}$ 实现的:当 $j > i$ 时,$M_{ij} = -\infty$(对应上三角区域);否则,$M_{ij} = 0$。 图 8.9 展示了应用掩码后的 $\mathbf{QK}^\top$ 矩阵。 (我们将在第 10 章看到,在某些任务中如何利用未来词元的信息。)
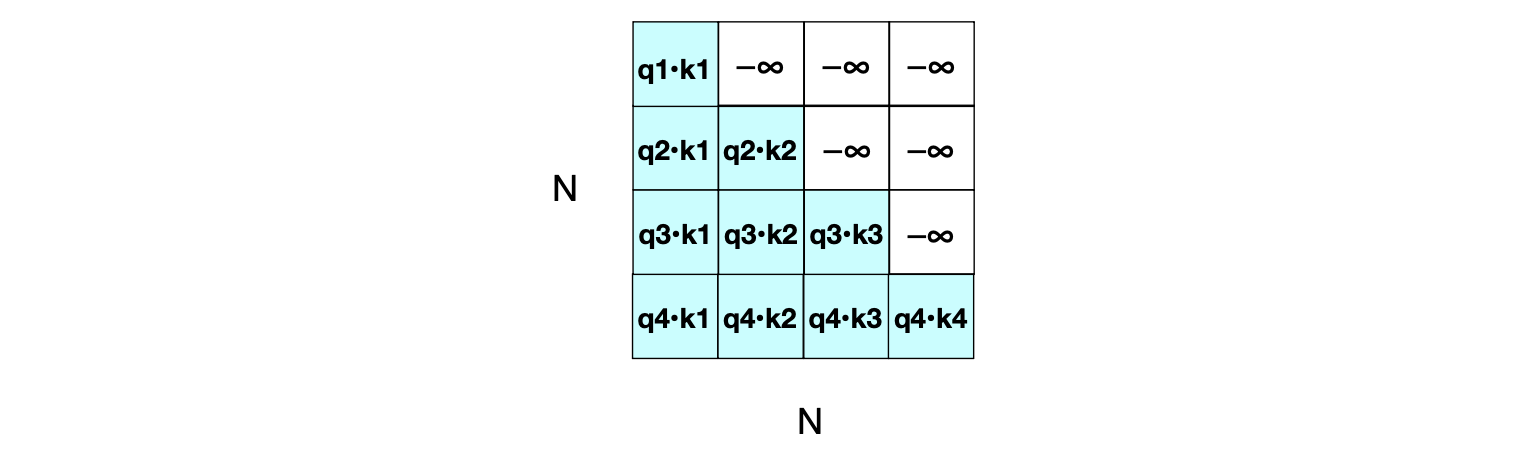
图 8.9 $N \times N$ 的 $\mathbf{QK}^\top$ 矩阵,显示了所有 $\mathbf{q}_i \cdot \mathbf{k}_j$ 的值,其中比较矩阵的上三角部分已被置零(实际设为 $-\infty$,经 softmax 后变为 0)。
图 8.10 则以示意图形式展示了单个注意力头在矩阵形式下的完整并行计算流程。
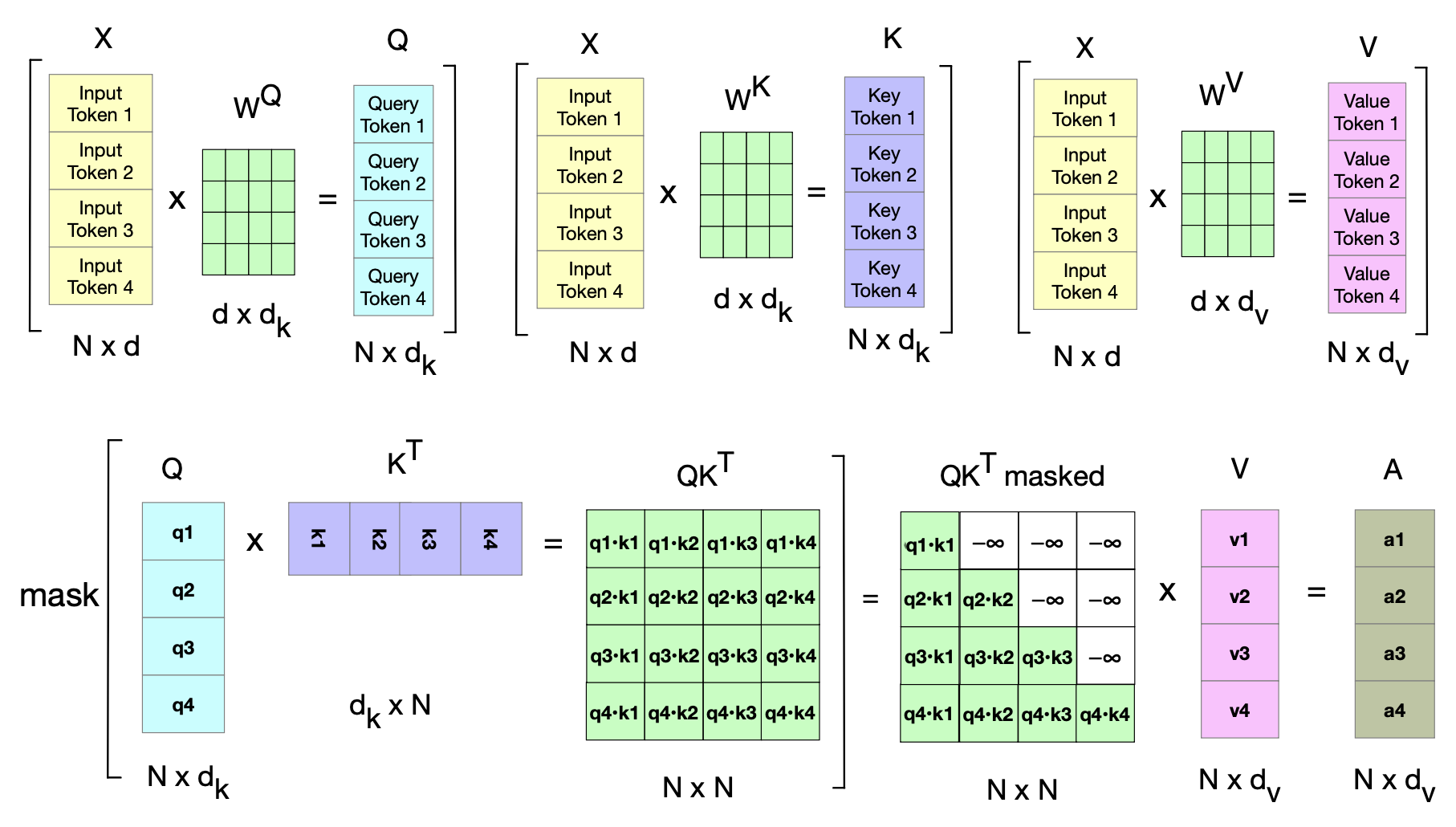
图 8.10 单个注意力头的并行化注意力计算示意图。 第一行展示了 $\mathbf{Q}$、$\mathbf{K}$ 和 $\mathbf{V}$ 矩阵的计算; 第二行展示了 $\mathbf{QK}^\top$ 的计算、掩码操作(图中未显示缩放和 softmax 步骤),以及对值向量进行加权求和以得到最终的注意力输出向量。
从图 8.8 和图 8.9 可以清楚看出:注意力机制的计算复杂度与输入长度呈平方关系,因为在每一层,我们都需计算输入中每一对词元之间的点积。 这使得在非常长的文档(例如整本小说)上计算注意力变得极其昂贵。 尽管如此,现代大型语言模型仍能有效处理数千甚至数万个词元的长上下文。
多头注意力的并行化
在多头注意力中,与自注意力类似,输入和输出的维度均为模型维度 $d$,键(Key)和查询(Query)嵌入的维度为 $d_k$,值(Value)嵌入的维度为 $d_v$(在原始 Transformer 论文中,$d_k = d_v = 64$,头数 $A = 8$,模型维度 $d = 512$)。 因此,对于每个头 $c$,我们有以下权重矩阵:
- $\mathbf{W}^Q_c$,形状为 $[d \times d_k]$,
- $\mathbf{W}^K_c$,形状为 $[d \times d_k]$,
- $\mathbf{W}^V_c$,形状为 $[d \times d_v]$。
将这些权重矩阵分别与打包成矩阵 $\mathbf{X}$ 的输入相乘,得到:
- $\mathbf{Q}$,形状为 $[N \times d_k]$,
- $\mathbf{K}$,形状为 $[N \times d_k]$,
- $\mathbf{V}$,形状为 $[N \times d_v]$。
每个头(共 $A$ 个)的输出形状均为 $[N \times d_v]$,因此整个多头注意力层的输出由 $A$ 个形状为 $[N \times d_v]$ 的矩阵组成。为了便于后续处理,这些矩阵会被拼接(concatenated)成一个单一矩阵,其维度为 $[N \times A d_v]$。
最后,我们使用一个最终的线性投影矩阵 $\mathbf{W}_\mathbf{O}$,其形状为 $[A d_v \times d]$,将拼接后的结果重新映射回原始的模型维度 $d$。 具体而言,将拼接后的 $[N \times A d_v]$ 矩阵与 $\mathbf{W}_\mathbf{O}$(形状 $[A d_v \times d]$)相乘,即可得到最终的自注意力输出,其形状为 $[N \times d]$。 对应的计算公式如下:
$$ \begin{align*} \mathbf{Q}^i &= \mathbf{X} \mathbf{W}_{Q_i}, \\ \mathbf{K}^i &= \mathbf{X} \mathbf{W}_{K_i}, \\ \mathbf{V}^i &= \mathbf{X} \mathbf{W}_{V_i} \tag{8.35} \end{align*} $$$$ \begin{align*} \text{head}_i &= \text{SelfAttention}(\mathbf{Q}^i, \mathbf{K}^i, \mathbf{V}^i) \\ &= \text{softmax}\left( \frac{\mathbf{Q}^i (\mathbf{K}^i)^\top}{\sqrt{d_k}} \right) \mathbf{V}^i \tag{8.36} \end{align*} $$$$ \text{MultiHeadAttention}(\mathbf{X}) = \left( \mathbf{head}_1 \oplus \mathbf{head}_2 \oplus \cdots \oplus \mathbf{head}_A \right) \mathbf{W}^O \tag{8.37} $$使用并行输入矩阵 $\mathbf{X}$ 整合全部计算
对整个输入序列(共 $N$ 个词元)并行执行一个完整 Transformer 层的计算,可以简洁地表示为以下两个公式:
$$ \begin{align*} \mathbf{O} &= \mathbf{X} + \text{MultiHeadAttention}\big(\text{LayerNorm}(\mathbf{X})\big) \tag{8.38} \\ \mathbf{H} &= \mathbf{O} + \text{FFN}\big(\text{LayerNorm}(\mathbf{O})\big) \tag{8.39} \end{align*} $$注意,在公式 (8.38) 中,我们用 $\mathbf{X}$ 表示该层的输入,无论其来源如何。 对于第一层,如我们将在下一节看到的,输入是初始的词嵌入与位置编码之和,即我们一直用 $\mathbf{X}$ 表示的矩阵。 对于第 $k$ 层($k > 1$),输入则是前一层的输出 $\mathbf{H}^{k-1}$。 我们也可以将 Transformer 层内的计算进一步拆解,为每个子操作写出独立方程。 这里使用 $\mathbf{T}$(形状为 $[N \times d]$)表示层内中间状态,并用上标标明各计算阶段。 同样,$\mathbf{X}$ 表示来自前一层(或初始嵌入)的输入:
$$ \begin{align*} \mathbf{T}^1 &= \text{LayerNorm}(\mathbf{X}) \tag{8.40} \\ \mathbf{T}^2 &= \text{MultiHeadAttention}(\mathbf{T}^1) \tag{8.41} \\ \mathbf{T}^3 &= \mathbf{T}^2 + \mathbf{X} \tag{8.42} \\ \mathbf{T}^4 &= \text{LayerNorm}(\mathbf{T}^3) \tag{8.43} \\ \mathbf{T}^5 &= \text{FFN}(\mathbf{T}^4) \tag{8.44} \\ \mathbf{H} &= \mathbf{T}^5 + \mathbf{T}^3 \tag{8.45} \end{align*} $$此处,当我们写作 $\text{FFN}(\mathbf{T}^3)$ 时,意味着同一个前馈网络(FFN)被并行地应用于窗口中全部 $N$ 个嵌入向量; 同样,LayerNorm 也是对全部 $N$ 个词元的向量并行执行归一化。 最关键的是,Transformer 块的输入与输出维度完全匹配,因此可以堆叠多个层。 由于每个输入词元 $\mathbf{x}_i$ 的维度为 $[1 \times d]$,整个输入矩阵 $\mathbf{X}$ 和输出矩阵 $\mathbf{H}$ 的形状均为 $[N \times d]$。