自注意力计算是所谓 Transformer 块(transformer block)的核心。除了自注意力层外,一个 Transformer 块还包含另外三种类型的层: (1) 前馈网络层(feedforward layer), (2) 残差连接(residual connections), (3) 归一化层(通常称为“层归一化”,layer norm)。
图 8.6 展示了一个 Transformer 块的结构,并采用了一种被称为 残差流(residual stream)的常见视角来理解该模块(Elhage 等,2021)。 在残差流视角下,我们将单个词元 $i$ 在 Transformer 块中的处理过程视为一条针对位置 $i$ 的、维度为 $d$ 的表示流。 这条残差流始于原始输入向量,各个组件从流中读取输入,并将其输出加回到流中。
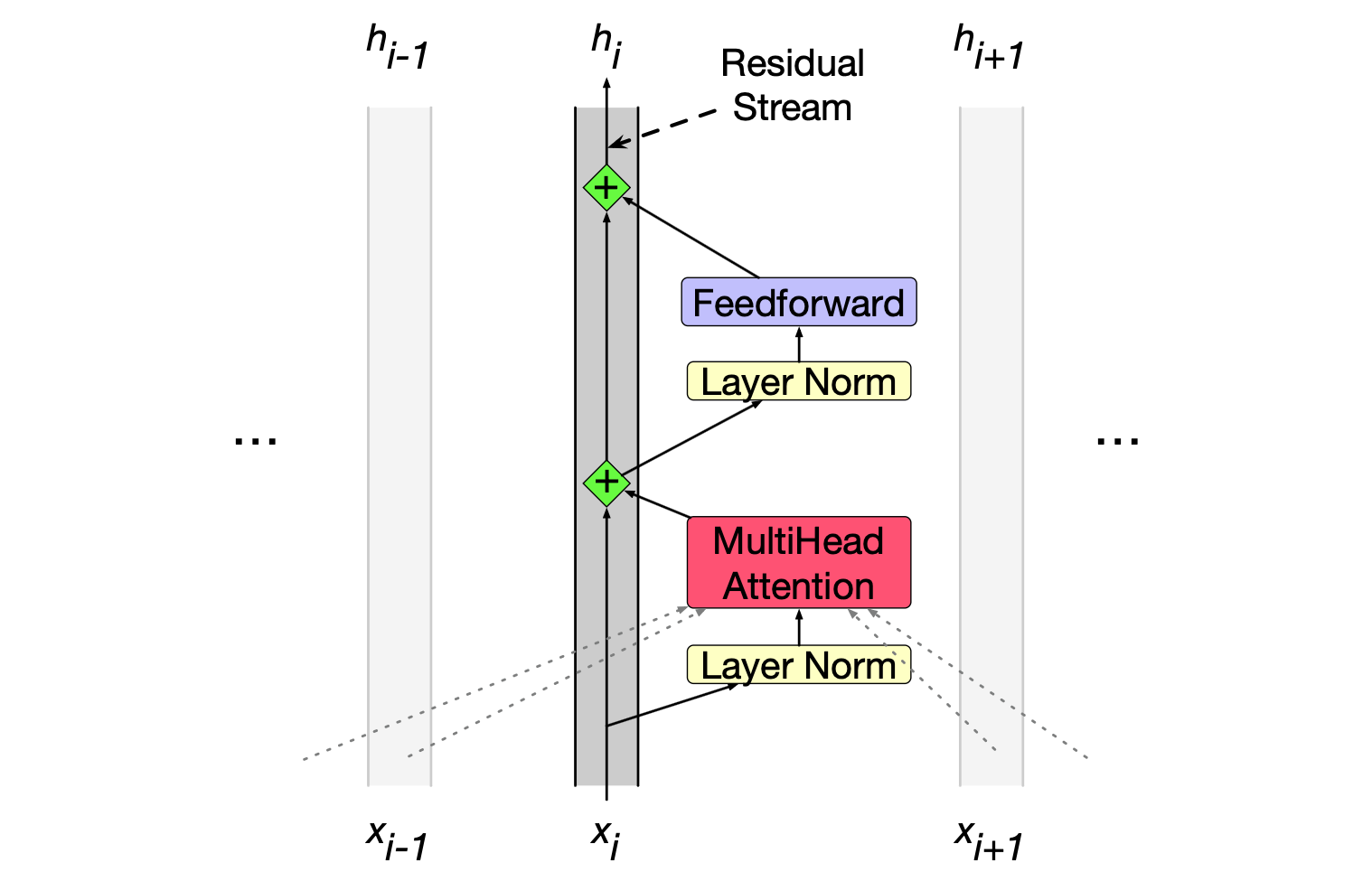
图 8.6 Transformer 块的架构,展示了 残差流。 本图展示的是 前置归一化(prenorm)版本的架构,即层归一化发生在注意力层和前馈层之前,而非之后。
流底部的输入是一个词元的嵌入向量,维度为 $d$。 该初始嵌入通过残差连接向上传递,并被 Transformer 的其他组件逐步更新:我们已介绍过的注意力层,以及即将引入的前馈层。 在注意力层和前馈层之前,会先执行一种称为层归一化(layer norm)的计算。
初始向量首先经过一层归一化和注意力层,其结果被加回到残差流中——在此处,是加到原始输入向量 $\mathbf{x}_i$ 上。 随后,这个求和后的向量再次经过另一层归一化和一个前馈层,其输出又被加回到残差流中。 我们将最终得到的输出记为 $\mathbf{h}_i$,表示词元 $i$ 经过整个 Transformer 块后的结果。 (早期描述常将这一机制比喻为残差连接——即将某个组件的输入与其输出相加。但残差流这一视角能更清晰地展现 Transformer 的信息流动方式。)
我们已经了解了注意力层,现在介绍在处理位置 $i$ 的单个输入 $\mathbf{x}_i$ 时,前馈层和层归一化的计算方式。
前馈层(Feedforward Layer)
前馈层是一个全连接的两层网络(即含一个隐藏层,两个权重矩阵),如第 6 章所述。 所有词元位置 $i$ 共享相同的权重(即权重与位置无关);但不同 Transformer 层之间的前馈权重彼此不同。 通常,前馈网络隐藏层的维度 $d_{ff}$ 会大于模型维度 $d$。 (例如,在原始 Transformer 模型中,$d = 512$,而 $d_{ff} = 2048$。)
$$ \text{FFN}(\mathbf{x}_i) = \text{ReLU}(\mathbf{x}_i \mathbf{W}_1 + \mathbf{b}_1) \mathbf{W}_2 + \mathbf{b}_2 \tag{8.21} $$层归一化(Layer Norm)
在 Transformer 块的两个阶段,我们会对向量进行归一化(Ba 等,2016)。 这一过程称为层归一化(layer normalization),是深度神经网络中用于提升训练性能的多种归一化方法之一。它通过将隐藏层的值保持在利于基于梯度优化的范围内,来稳定训练过程。
层归一化本质上是统计学中 z-score 的一种变体,但应用于隐藏层中的单个向量。 注意:“层归一化”这一名称容易引起误解——它并非作用于整个 Transformer 层,而是仅作用于单个词元的嵌入向量。 因此,层归一化的输入是一个维度为 $d$ 的向量,输出是归一化后的同维度向量。 层归一化的第一步是计算待归一化向量各元素的均值 $\mu$ 和标准差 $\sigma$。 给定一个维度为 $d$ 的嵌入向量 $\mathbf{x}$,其计算方式如下:
$$ \begin{align*} \mu &= \frac{1}{d} \sum_{i=1}^{d} \mathbf{x}_i \tag{8.22} \\ \sigma &= \sqrt{ \frac{1}{d} \sum_{i=1}^{d} (\mathbf{x}_i - \mu)^2 } \tag{8.23} \end{align*} $$接着,对向量每个分量减去均值并除以标准差,得到一个均值为 0、标准差为 1 的新向量:
$$ \hat{\mathbf{x}} = \frac{(\mathbf{x} - \mu)}{\sigma} \tag{8.24} $$最后,在标准实现中,会引入两个可学习参数 $\gamma$(增益)和 $\beta$(偏移),以恢复网络的表达能力:
$$ \text{LayerNorm}(\mathbf{x}) = \gamma \cdot \frac{(\mathbf{x} - \mu)}{\sigma} + \beta \tag{8.25} $$整合所有组件
一个 Transformer 块所实现的函数,可以通过将每个子计算步骤拆解为独立方程来表达。我们用 $\mathbf{t}$(形状为 $[1 \times d]$)表示该块内部的中间表示,并用上标标明块内各阶段的计算:
$$ \begin{align*} \mathbf{t}^1_i &= \text{LayerNorm}(\mathbf{x}_i) \tag{8.26} \\ \mathbf{t}^2_i &= \text{MultiHeadAttention}\big(\mathbf{t}^1_i,\, [\mathbf{x}^1_1, \dots, \mathbf{x}^1_N]\big) \tag{8.27} \\ \mathbf{t}^3_i &= \mathbf{t}^2_i + \mathbf{x}_i \tag{8.28} \\ \mathbf{t}^4_i &= \text{LayerNorm}(\mathbf{t}^3_i) \tag{8.29} \\ \mathbf{t}^5_i &= \text{FFN}(\mathbf{t}^4_i) \tag{8.30} \\ \mathbf{h}_i &= \mathbf{t}^5_i + \mathbf{t}^3_i \tag{8.31} \end{align*} $$注意:唯一接收来自其他词元信息(即其他残差流)的是多头注意力机制。如公式 (8.27) 所示,它会查看上下文中的所有邻近词元。 然而,注意力的输出随后会被加回到当前词元自身的嵌入流中。 事实上,Elhage 等人(2021)指出,我们可以将注意力头理解为直接从邻近词元的残差流中“搬运”信息到当前词元的残差流中。 因此,每个位置的高维嵌入空间既包含当前词元的信息,也包含邻近词元的信息——尽管这些信息分布在向量空间的不同子空间中。 图 8.7 直观地展示了这种信息流动。
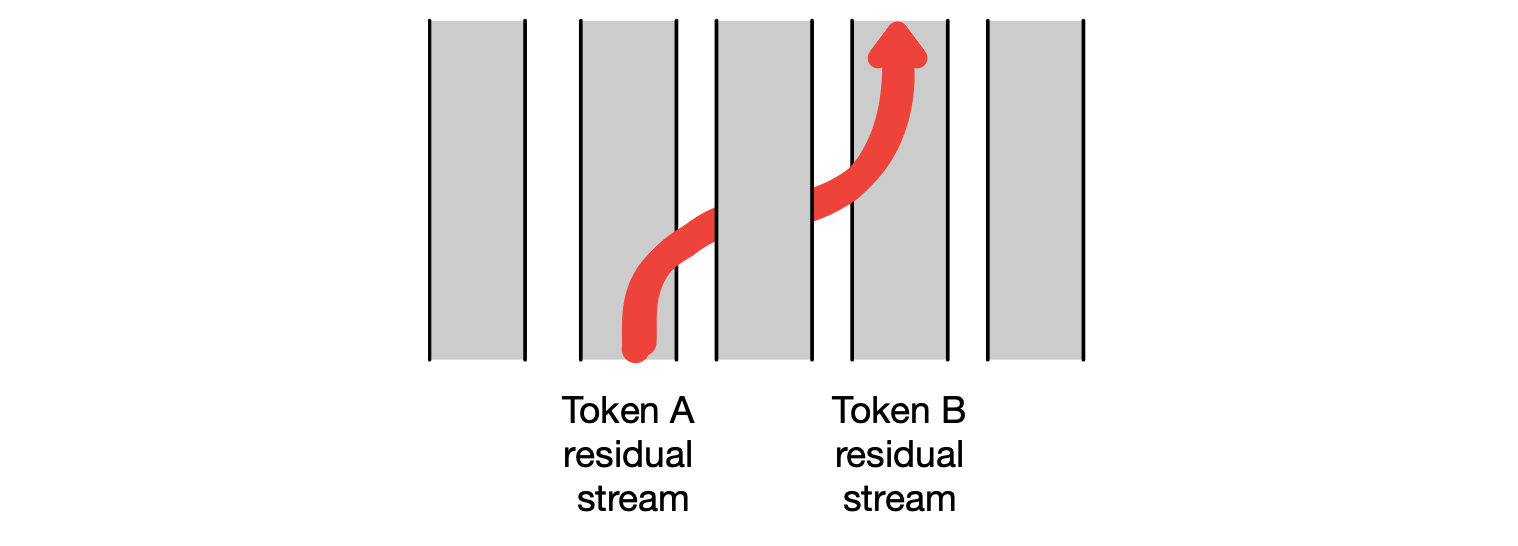
图 8.7 一个注意力头可以将词元 A 的残差流中的信息“移动”到词元 B 的残差流中。
至关重要的是,Transformer 块的输入与输出维度保持一致,从而支持堆叠多个块。 每个输入词元向量 $\mathbf{x}_i$ 的维度为 $d$,输出 $\mathbf{h}_i$ 的维度同样为 $d$。 大型语言模型中的 Transformer 通常堆叠大量这样的块,例如 T5 或 GPT-3-small 使用 12 层,GPT-3 large 使用 96 层,更近期的模型甚至使用更多层。 我们稍后还会回到堆叠结构这一话题。
需要强调的是,公式 (8.26) 及后续仅描述单个 Transformer 块。但“残差流”这一隐喻贯穿整个模型的所有层——从第 1 层一直到第 12 层(以 12 层模型为例)。 在较浅层的 Transformer 块中,残差流主要表示当前词元。 而在最顶层的块中,残差流通常已编码了下一个词元的信息,因为模型最终的目标就是预测序列中的下一个词元。
当堆叠多个块后,还有一个额外要求:在最后一个(最高层)Transformer 块的末端,会对每个词元流的最终输出 $\mathbf{h}_i$ 再施加一层额外的层归一化(位于我们即将定义的语言模型头部之下)1。
注意,我们这里采用的是当前最主流的 Transformer 架构,称为 前置归一化(prenorm)架构。 Vaswani 等人(2017)最初提出的 Transformer 使用的是另一种称为 后置归一化(postnorm)的架构——其中层归一化位于注意力层和前馈层之后。 后来发现,将层归一化移至前面效果更好,但这也要求在网络最末端额外添加一层归一化。 ↩︎