回顾第 5 章的内容,在 word2vec 和其他静态词嵌入方法中,一个词的语义表示始终是同一个向量,与上下文无关:例如,单词 chicken 总是由同一个固定的向量表示。
因此,代词 it 的静态向量可能只能编码“这是一个用于动物或无生命事物的代词”这一信息。
但在实际语境中,它的含义要丰富得多。请考虑以下两个句子中的 it:
(8.1) The chicken didn’t cross the road because it was too tired.
(8.2) The chicken didn’t cross the road because it was too wide.
在句子 (8.1) 中,it 指的是 chicken(即读者知道是鸡太累了),而在句子 (8.2) 中,it 指的是 road(即读者知道路太宽了)1。
也就是说,如果我们想要计算整个句子的含义,就必须让 it 在第一个句子中与 the chicken 关联,在第二个句子中与 the road 关联,这种关联是依赖于上下文的。
此外,设想我们像一个因果语言模型那样从左到右阅读,处理到单词 it 为止:
(8.3) The chicken didn’t cross the road because it
此时,我们尚不清楚 it 最终会指代什么!
因此,在这个时刻,对 it 的表示可能同时包含 chicken 和 road 的某些特征,因为模型正在尝试预测接下来会发生什么。
这种词语之间存在丰富语言关系、且这些相关词可能相距甚远的现象,在语言中极为普遍。 再看两个例子:
(8.4) The keys to the cabinet are on the table.
(8.5) I walked along the pond, and noticed one of the trees along the bank.
在 (8.4) 中,短语 The keys 是句子的主语,在英语(以及许多语言)中,它必须与动词 are 在语法数上保持一致;本例中两者均为复数。
在英语中,我们不能对像 keys 这样的复数主语使用单数动词 is(我们将在第 18 章更详细地讨论一致性问题)。
在 8.5 中,我们知道 bank 指的是池塘或河流的岸边,而不是金融机构,这得益于上下文,尤其是像 pond 这样的词。(我们将在第 10 章更深入地讨论词义问题。)
所有这些例子的核心在于:那些帮助我们计算词语在上下文中含义的“上下文词”,可能在句子或段落中距离很远。 Transformer 能够通过整合这些关键上下文词的语义信息,构建出词语的上下文相关表示,即上下文嵌入(contextual embeddings)。 在 Transformer 中,我们逐层地构建输入词元语义的、越来越丰富的上下文化表示。 在每一层,我们都将上一层中关于词元 $i$ 的信息与其邻近词元的信息结合起来,为每个位置上的每个词生成一个上下文化后的表示。
注意力(Attention)正是 Transformer 中的机制,它通过为上下文中的其他词元(来自第 $k$ 层的表示)分配权重并进行组合,从而构建第 $k+1$ 层词元的表示。
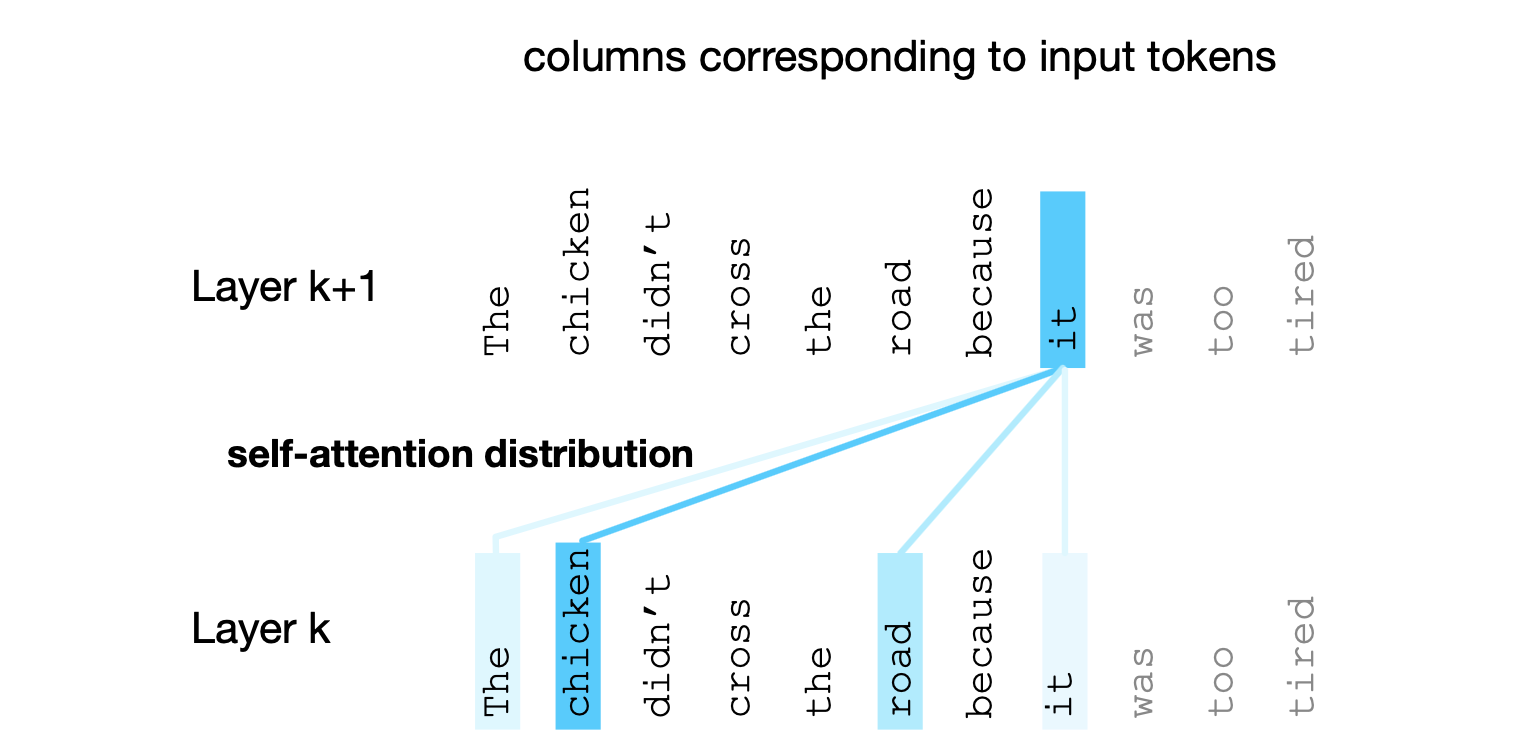
图 8.2 展示了在第 $k+1$ 层计算代词 it 的表示时所涉及的自注意力权重分布 $\alpha$。
在计算 it 的表示时,模型对第 $k$ 层的各个词赋予不同的注意力,颜色越深表示自注意力值越高。
请注意,模型对对应 chicken 和 road 两个词元的列赋予了很高的注意力,这是一个合理的结果,因为在出现 it 的位置,它都有可能与 chicken 或 road 共指,因此我们希望 it 的表示能够借鉴这两个先前词元的表示。
该图改编自 Uszkoreit (2017)。
图8.2 展示了一个来自 Transformer 的简化示意图(Uszkoreit, 2017)。
该图描述了当前词元为 it 时,在 Transformer 的第 $k+1$ 层为其计算上下文表示的情景,此时需要参考此前所有词元在第 $k$ 层的表示。
图中用颜色深浅来表示对各个上下文词的注意力分布:chicken 和 road 两个词元都具有较高的注意力权重,这意味着在计算 it 的表示时,我们将主要借鉴 chicken 和 road 的表示。
这有助于最终构建出 it 的表示,因为 it 最终将与 chicken 或 road 之一形成共指关系。
接下来,我们将讨论这种注意力分布是如何表示和计算的。
8.1.1 注意力机制的形式化描述
如前所述,注意力计算是一种方法。它用于在 Transformer 的某一层中,为某个词元(token)生成向量表示。该方法通过有选择地关注并整合前一层中先前词元的信息来实现。 具体来说,注意力机制接收两个输入:当前位置 $i$ 处词元对应的输入表示 $\mathbf{x}_i$;一个上下文窗口,包含此前所有位置的输入 $\mathbf{x}_1, \dots, \mathbf{x}_{i-1}$。它输出一个向量 $\mathbf{a}_i$。
在因果型(causal)、从左到右的语言模型中,上下文指的是所有先前的词。 也就是说,在处理 $\mathbf{x}_i$ 时,模型可以访问 $\mathbf{x}_i$ 本身,以及上下文窗口中所有先前词元的表示(上下文窗口通常包含数千个词元),但不能访问位置 $i$ 之后的任何词元。 (相比之下,第 10 章将推广注意力机制,使其也能“向前看”,即访问未来的词。)
图 8.3 展示了整个因果自注意力层中的信息流动。在该层中,每个位置 $i$ 都并行执行相同的注意力计算。 因此,一个自注意力层将输入序列 $(\mathbf{x}_1, \dots, \mathbf{x}_n)$ 映射为长度相同的输出序列 $(\mathbf{a}_1, \dots, \mathbf{a}_n)$。
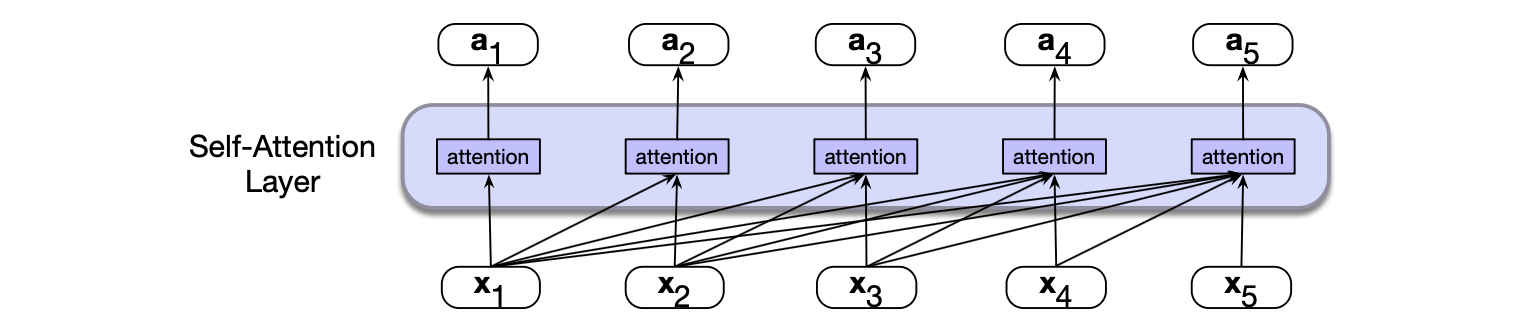
图 8.3 因果自注意力中的信息流动。 处理每个输入 $\mathbf{x}_i$ 时,模型会关注从 $\mathbf{x}_1$ 到 $\mathbf{x}_i$(含)的所有输入。
注意力的简化版本
本质上,注意力只是对上下文向量进行加权求和。复杂之处在于权重如何计算,以及哪些内容被求和。 为了便于教学,我们先介绍一种简化的注意力原理:在位置 $i$ 处的注意力输出 $\mathbf{a}_i$,就是对所有满足 $j \leq i$ 的表示 $\mathbf{x}_j$ 进行加权求和。 我们用 $\alpha_{ij}$ 表示 $\mathbf{x}_j$ 对 $\mathbf{a}_i$ 的贡献程度:
$$ \text{简化版:} \quad \mathbf{a}_i = \sum_{j \leq i} \alpha_{ij} \times \mathbf{x}_j \tag{8.6} $$每个 $\alpha_{ij}$ 是一个标量,用于在计算 $\mathbf{a}_i$ 时对输入 $\mathbf{x}_j$ 赋予权重。 那么,如何计算这个权重 $\alpha_{ij}$ 呢? 在注意力机制中,我们根据先前嵌入与当前词元 $i$ 的相似度来成比例地分配权重。 因此,注意力的输出是先前词元嵌入的加权和,权重由它们与当前词元嵌入的相似度决定。 我们使用点积(dot product)来计算相似度得分。点积将两个向量映射为一个标量,取值范围为 $(-\infty, +\infty)$。 得分越高,说明两个向量越相似。 接着,我们对这些得分应用 softmax 函数,将其归一化为权重向量 $\alpha_{ij}$(其中 $j \leq i$):
$$ \begin{align*} \text{简化版:} \quad \text{score}(\mathbf{x}_i, \mathbf{x}_j) &= \mathbf{x}_i \cdot \mathbf{x}_j \tag{8.7} \\ \alpha_{ij} &= \text{softmax}(\text{score}(\mathbf{x}_i, \mathbf{x}_j)) \quad \forall j \leq i \tag{8.8} \end{align*} $$因此,在图 8.3 中,要计算 $\mathbf{a}_3$,需先计算三个得分: $\mathbf{x}_3 \cdot \mathbf{x}_1$、$\mathbf{x}_3 \cdot \mathbf{x}_2$ 和 $\mathbf{x}_3 \cdot \mathbf{x}_3$。 然后,对这三个得分做 softmax 归一化,得到的概率值即为各输入相对当前位置 i 的相关性权重。 显然,$\mathbf{x}_i$ 与自身最相似,点积得分最高,因此 softmax 后其权重通常最大。 但其他上下文词若与当前位置 i 相似,也会获得一定权重。 最后,将这些权重作为式 (8.6) 中的 $\alpha_{ij}$,计算加权和,得到 $\mathbf{a}_3$。
式 (8.6)–(8.8) 所示的简化注意力机制,体现了基于注意力计算 $\mathbf{a}_i$ 的基本思路: 将 $\mathbf{x}_i$ 与先前向量比较,将比较得分归一化为概率分布,并以此作为权重对先前向量求和。 接下来,我们将去掉这些简化假设,介绍完整的注意力机制。
使用查询、键和值矩阵的单头注意力
在了解了注意力机制的简化思想之后,我们现在引入实际使用的注意力头(attention head),这是 Transformer 中采用的注意力形式。(“头”(head)一词在 Transformer 中常用来指代具有特定结构的层。) 每个输入嵌入在注意力过程中扮演着三种不同角色,注意力头允许我们清晰地区分它们的作用:
- 作为当前元素,用于与先前的输入进行比较。我们将这一角色称为 查询(query)。
- 作为先前输入,用于与当前元素比较以确定相似度权重。我们将这一角色称为 键(key)。
- 最后,作为先前元素的值(value),该值将被加权并求和,用于计算当前元素的输出。
为了体现这三种不同角色,Transformer 引入了三个权重矩阵:$\mathbf{W^Q}$、$\mathbf{W^K}$ 和 $\mathbf{W^V}$。 这些权重矩阵将每个输入向量 $\mathbf{x}_i$ 投影为它在查询、键或值角色下的表示:
$$ \begin{align*} \mathbf{q}_i &= \mathbf{x}_i \mathbf{W}^{\mathbf{Q}}; \\ \mathbf{k}_i &= \mathbf{x}_i \mathbf{W}^{K}; \\ \mathbf{v}_i &= \mathbf{x}_i \mathbf{W}^{V} \tag{8.9} \end{align*} $$有了这些投影后,在计算当前元素 $\mathbf{x}_i$ 与某个先前元素 $\mathbf{x}_j$ 的相似度时,我们使用当前元素的查询向量 $\mathbf{q}_i$ 与先前元素的键向量 $\mathbf{k}_j$ 的点积。 此外,点积的结果可能是一个任意大的正值或负值。在训练过程中,对大数值取指数(如 softmax 所需)可能导致数值不稳定,并造成梯度消失。 为避免这一问题,我们对点积进行缩放:将其除以查询向量和键向量维度 $d_k$ 的平方根。 因此,我们用以下公式(8.11)替代之前的简化公式(8.7)。 随后的 softmax 计算(得到 $\alpha_{ij}$)保持不变,但输出 $\mathbf{head}_i$ 现在基于对值向量 $\mathbf{v}$ 的加权求和(见公式 8.13)。
以下是计算单个自注意力输出向量 $\mathbf{a}_i$ 的完整公式集。 该版本通过加权求和先前元素的值来计算 $\mathbf{a}_i$,权重由当前元素的查询与各先前元素的键之间的相似度决定:
$$ \begin{align*} \mathbf{q}_i = \mathbf{x}_i \mathbf{W^Q}; \mathbf{k}_j &= \mathbf{x}_j \mathbf{W^K}; \mathbf{v}_j = \mathbf{x}_j \mathbf{W^V} \tag{8.10} \\ \mathrm{score}(\mathbf{x}_i, \mathbf{x}_j) &= \frac{\mathbf{q}_i \cdot \mathbf{k}_j}{\sqrt{d_k}} \tag{8.11} \\ \alpha_{ij} &= \text{softmax}(\text{score}(\mathbf{x}_i, \mathbf{x}_j)) \quad \forall j \leq i \tag{8.12} \\ \mathbf{head}_i &= \sum_{j \leq i} \alpha_{ij} \mathbf{v}_j \tag{8.13} \\ \mathbf{a}_i &= \mathbf{head}_i \mathbf{W}^{\mathbf{O}} \tag{8.14} \end{align*} $$图 8.4 展示了在序列中计算第三个输出 $\mathbf{a}_3$ 的过程。
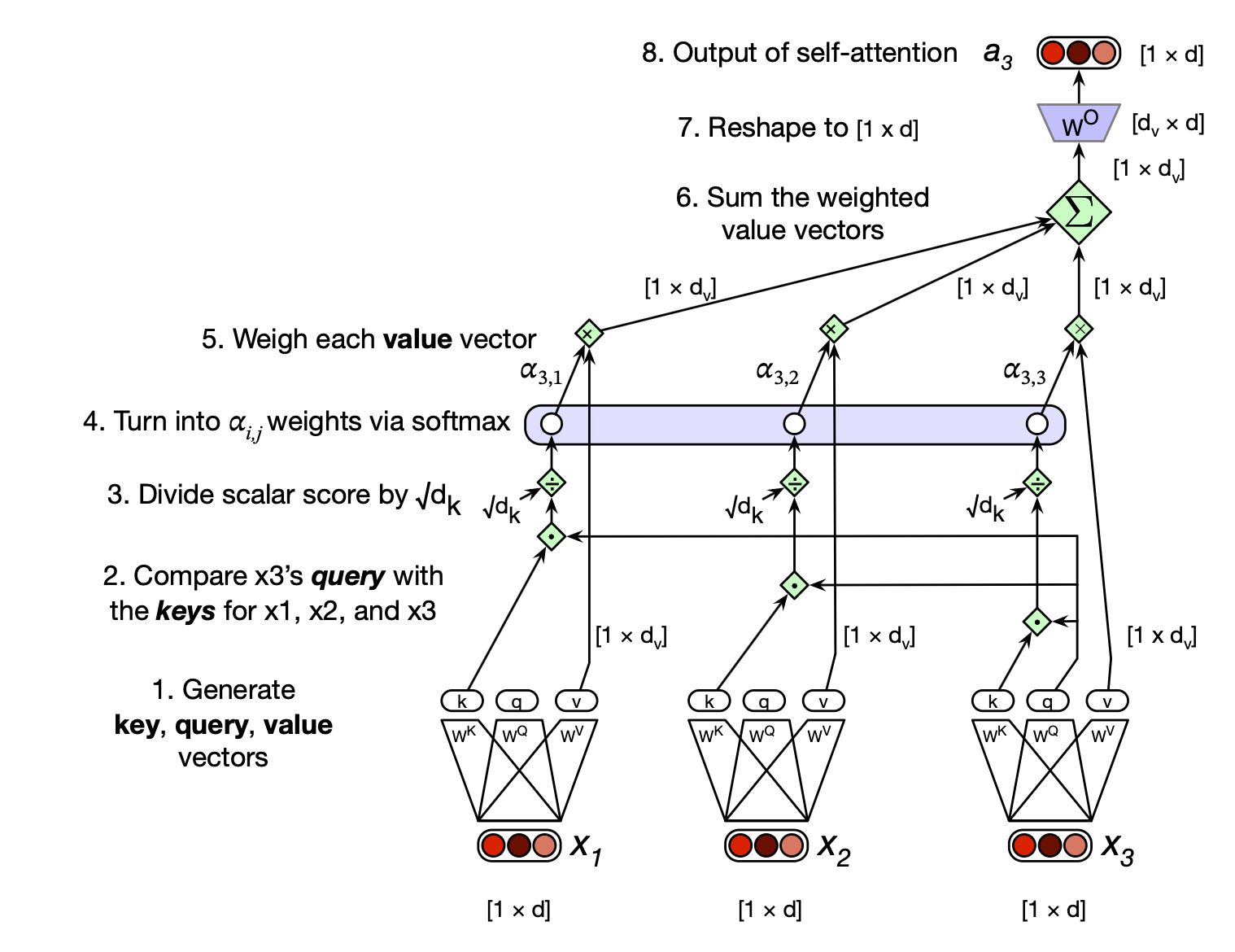
图 8.4 使用因果型(从左到右)自注意力计算序列中第三个元素 $\mathbf{a}_3$ 的值。
注意,我们还引入了另一个矩阵 $\mathbf{W^O}$,它被右乘于注意力头的输出。 这是为了调整注意力头输出的形状。 输入 $\mathbf{x}_i$ 与输出 $\mathbf{a}_i$ 具有相同的维度 $[1 \times d]$。 我们通常称 $d$ 为模型维度(model dimensionality)。正如第 8.2 节将讨论的那样,每个 Transformer 块的输出 $\mathbf{h}_i$ 以及块内部的中间向量也都具有相同的维度 $[1 \times d]$。 这种统一的维度设计使 Transformer 架构高度模块化。
下面我们具体分析各部分的张量形状。 如何从输入的 $[1 \times d]$ 得到输出的 $[1 \times d]$? 我们逐一看内部各部分的维度。 查询向量和键向量的维度均为 $[1 \times d_k]$,因此它们的点积 $\mathbf{q}_i \cdot \mathbf{k}_j$ 是一个标量。 值向量的维度为 $[1 \times d_v]$。 投影矩阵的形状如下:
- $\mathbf{W}^{\mathbf{Q}}$:$[d \times d_k]$
- $\mathbf{W}^{K}$:$[d \times d_k]$
- $\mathbf{W}^{V}$:$[d \times d_v]$
因此,公式 (8.13) 中 $\mathbf{head}_i$ 的输出维度为 $[1 \times d_v]$。 为了得到目标输出维度 $[1 \times d]$,我们需要对注意力头的输出进行重塑,故输出投影矩阵 $\mathbf{W}^{\mathbf{O}}$ 的形状为 $[d_v \times d]$。 在原始 Transformer 论文(Vaswani 等,2017)中,$d = 512$,而 $d_k$ 与 $d_v$ 均为 64。
多头注意力(Multi-head Attention)
公式 (8.11)–(8.13) 描述的是一个单注意力头。但实际上,Transformer 使用多个注意力头。 其核心思想是:每个头可以出于不同目的关注上下文。例如,某些头可能专门捕捉上下文元素与当前词元之间的特定语言学关系,或在上下文中寻找特定类型的模式。
因此,在多头注意力中,模型在同一深度并行放置 $h$ 个独立的注意力头。每个头拥有自己的一组参数,从而能够建模输入之间关系的不同方面。 于是,在自注意力层中,每个头 $c$ 都有自己独立的键、查询和值矩阵:$\mathbf{W^{Qi}}$、$\mathbf{W^{Ki}}$ 和 $\mathbf{W^{Vc}}$。 这些矩阵用于将输入分别投影为该头专用的键、值和查询嵌入。
使用多头时,输入和输出仍保持模型维度 $d$。查询和键嵌入的维度为 $d_k$,值嵌入的维度为 $d_v$。 (再次说明:在原始 Transformer 论文中,$d_k = d_v = 64$,头数 $h = 8$,模型维度 $d = 512$。) 因此,对于每个头 $c$,我们有 $\mathbf{W^{Qi}}$,形状为 $[d \times d_k]$;$\mathbf{W^{Ki}}$,形状为 $[d \times d_k]$; $\mathbf{W^{Vi}}$,形状为 $[d \times d_v]$
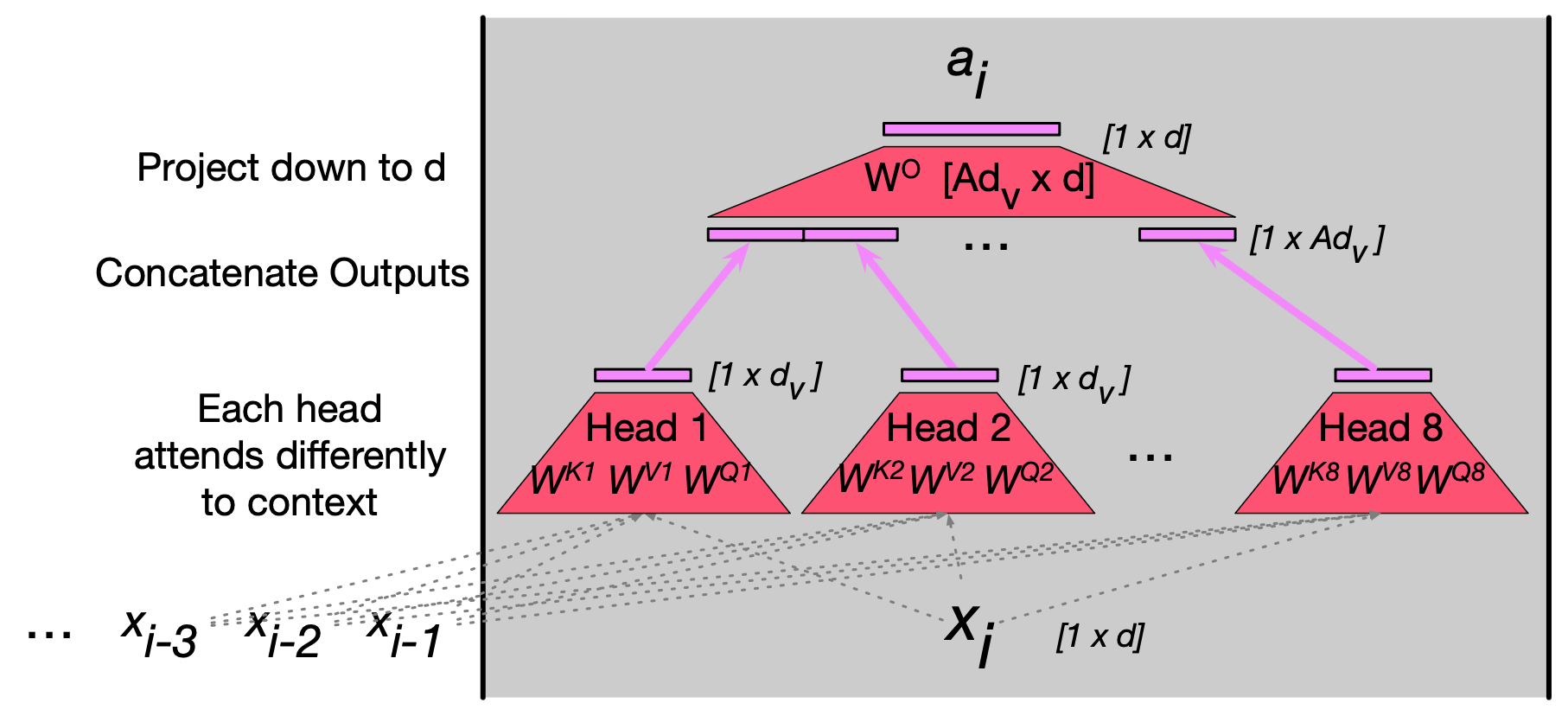
图 8.5 对输入 $\mathbf{x}_i$ 执行多头注意力计算,生成输出 $\mathbf{a}_i$。 一个多头注意力层包含 $A$ 个头,每个头拥有自己的查询、键和值权重矩阵。 各头的输出被拼接起来,再通过一个线性投影降至维度 $d$,从而得到与输入相同尺寸的输出。
以下是引入多头机制后的完整注意力公式;图 8.5 给出了直观示意图:
$$ \begin{align*} \mathbf{q}^c_i = \mathbf{x}_i \mathbf{W^Qc}; \mathbf{k}^c_j = \mathbf{x}_j \mathbf{W_Kc}; \mathbf{v}^c_j &= \mathbf{x}_j \mathbf{W_Vc}; \quad \forall\, 1 \leq c \leq h \tag{8.15} \\ \mathrm{score}^c(\mathbf{x}_i, \mathbf{x}_j) &= \frac{\mathbf{q}^c_i \cdot \mathbf{k}^c_j}{\sqrt{d_k}} \tag{8.16} \\ \alpha^c_{ij} &= \text{softmax}\big(\text{score}^c(\mathbf{x}_i, \mathbf{x}_j)\big) \quad \forall j \leq i \tag{8.17} \\ \text{head}^c_i &= \sum_{j \leq i} \alpha^c_{ij} \mathbf{v}^c_j \tag{8.18} \\ \mathbf{a}_i &= \big( \text{head}^1_i \oplus \text{head}^2_i \oplus \cdots \oplus \text{head}^A_i \big) \mathbf{W}^{O} \tag{8.19} \\ \mathrm{MultiHeadAttention}\big(\mathbf{x}_i, [\mathbf{x}_1, \dots, \mathbf{x}_N]\big) &= \mathbf{a}_i \tag{8.20} \end{align*} $$注意,在公式 (8.20) 中,MultiHeadAttention 是当前输入 $\mathbf{x}_i$ 以及所有其他输入的函数。
在本章使用的因果型(从左到右)注意力中,“其他输入”仅指左侧的词元。
但在第 10 章,我们将看到另一种注意力形式:它同时依赖右侧的词元。
关于因果输入的这一思想,我们将在引入右上下文掩码(masking the right context)时,于公式 (8.34) 再次讨论。
每个头的输出维度为 $[1 \times d_v]$,因此 $A$ 个头的输出共形成 $A$ 个 $[1 \times d_v]$ 向量。 这些向量被拼接(concatenated)成一个维度为 $[1 \times A d_v]$ 的向量。 随后,我们再通过一个线性投影矩阵 $\mathbf{W}^{O} \in \mathbb{R}^{A d_v \times d}$ 将其重塑,最终得到多头注意力输出向量 $\mathbf{a}_i$,其维度为 $[1 \times d]$,与输入一致。
我们称在第一个例子中
it与chicken共指(corefer),在第二个例子中与road共指;我们将在第 23 章再次讨论这一现象。 ↩︎