“真正的记忆艺术在于专注。”
塞缪尔·约翰逊,《闲者》第74篇,1759年9月
本章将介绍 Transformer,这是构建大语言模型的标准架构。 正如上一章所言,基于 Transformer 的大语言模型彻底改变了语音与语言处理领域。 事实上,本书后续每一章都将用到这一技术。 和上一章一样,本章我们主要关注从左到右(有时也称为因果式或自回归)的语言建模方式,即给定一个输入词元(token)序列,模型根据先前的上下文逐个预测下一个输出词元。
Transformer 是一种具有特定结构的神经网络,其核心机制被称为自注意力(self-attention)或多头注意力(multi-head attention)1。 注意力机制可以理解为一种方法,通过“关注”并整合周围词元的信息,来构建某个词元在上下文中的语义表示,从而帮助模型学习长距离内词元之间的关联。
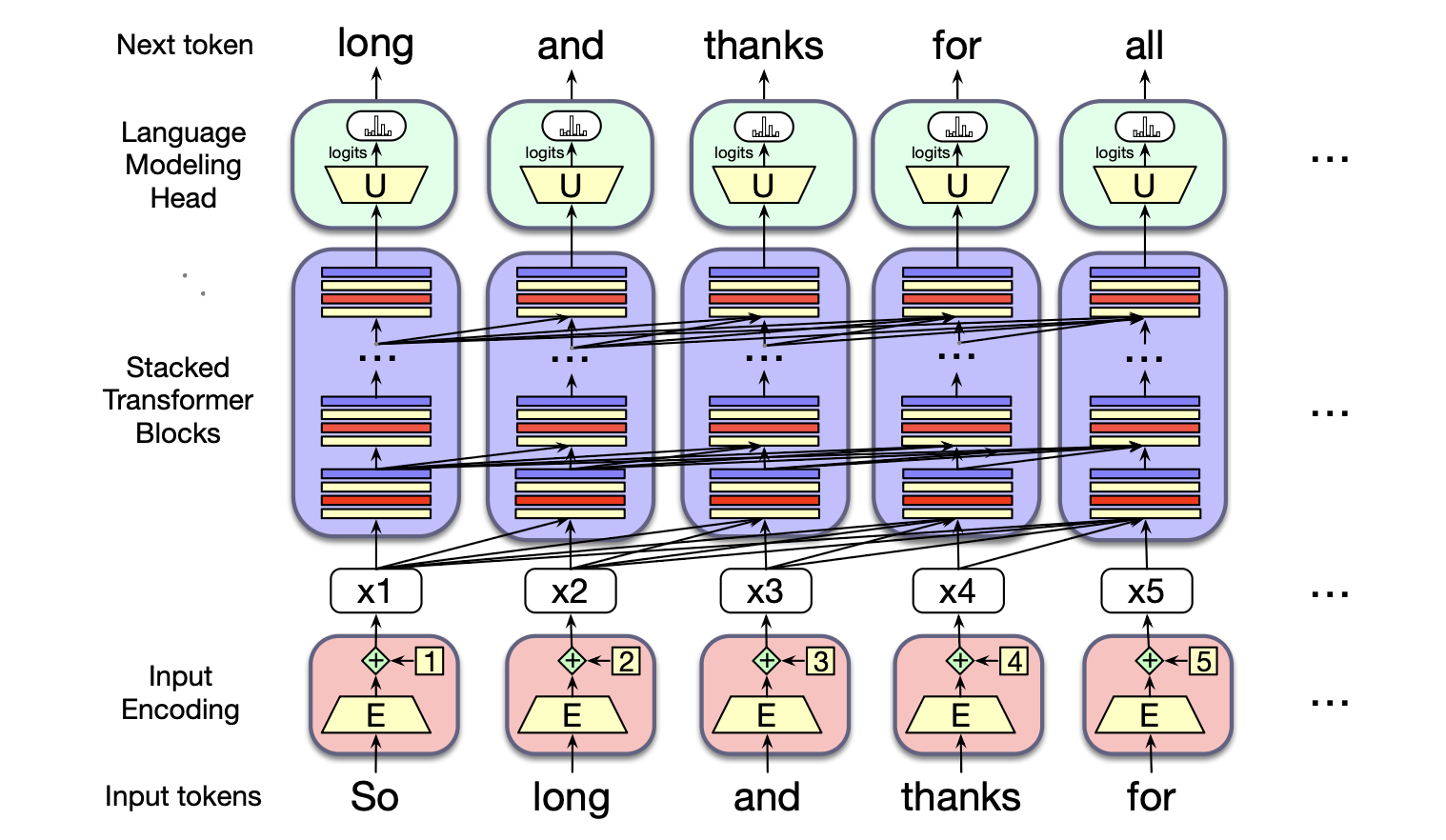
图 8.1 展示了一个(从左到右的)Transformer 架构,说明了每个输入词元如何被编码,经过一系列堆叠的 Transformer 模块(block),最终由语言模型头部预测下一个词元。
图8.1 概述了 Transformer 的基本结构。 一个完整的 Transformer 模型包含三个主要组成部分。 居于核心的是若干列堆叠的 Transformer 模块(blocks)。 每个模块是一个多层网络,包含一个多头注意力层、前馈网络以及层归一化(layer normalization)等操作,它将第 $i$ 列的输入向量 $\mathbf{x}_i$(对应第 $i$ 个输入词元)映射为输出向量 $\mathbf{h}_i$。 整组 $n$ 个模块共同将一个长度为 $n$ 的上下文窗口内的输入向量序列($\mathbf{x}_1,...,\mathbf{x}_n$)映射为一个等长的输出向量序列($\mathbf{h}_1,...,\mathbf{h}_n$)。 每个“列”通常包含 12 到 96 个甚至更多堆叠的模块。
在模块列之前是输入编码(input encoding)组件,它负责将一个输入词元(例如单词 “thanks”)处理成一个具有上下文意义的向量表示,这通常通过一个嵌入矩阵 $\mathbf{E}$(embedding matrix $\mathbf{E}$)以及一种对词元位置进行编码的机制来实现。 在模块列之后是语言模型头(language modeling head),它接收最后一个 Transformer 模块输出的嵌入表示,将其通过一个解嵌入矩阵 $\mathbf{U}$(unembedding matrix $\mathbf{U}$),再经过一个针对整个词汇表的 softmax 函数,最终为该位置生成一个预测词元。
基于 Transformer 的语言模型结构复杂,其细节将在接下来的几章中逐步展开。 第 7 章已经介绍了如何预训练模型,如何通过采样(sampling)生成词元。 在本章接下来的几节中,我们将介绍多头注意力机制、Transformer 模块的其余部分,以及输入编码和语言模型头部等组件。 第 10 章将介绍掩码语言建模(masked language modeling)以及基于双向 Transformer 编码器的 BERT 系列模型。 第 9 章将展示如何通过提供指令和示例来提示(prompt)大语言模型,使其执行各类自然语言处理任务,以及如何通过对齐(align)技术使模型的输出符合人类偏好。 第 12 章将介绍使用编码器-解码器(encoder-decoder)架构进行机器翻译的方法。
尽管多头注意力机制在历史上源于循环神经网络中的注意力机制(见第8章),但为了照顾尚未阅读第8章的读者,我们将在本章从头开始定义注意力机制。 ↩︎