我们如何训练一个语言模型?使用什么算法?在什么数据上进行训练?
大语言模型的训练通常分为三个阶段,如图 7.12 所示:
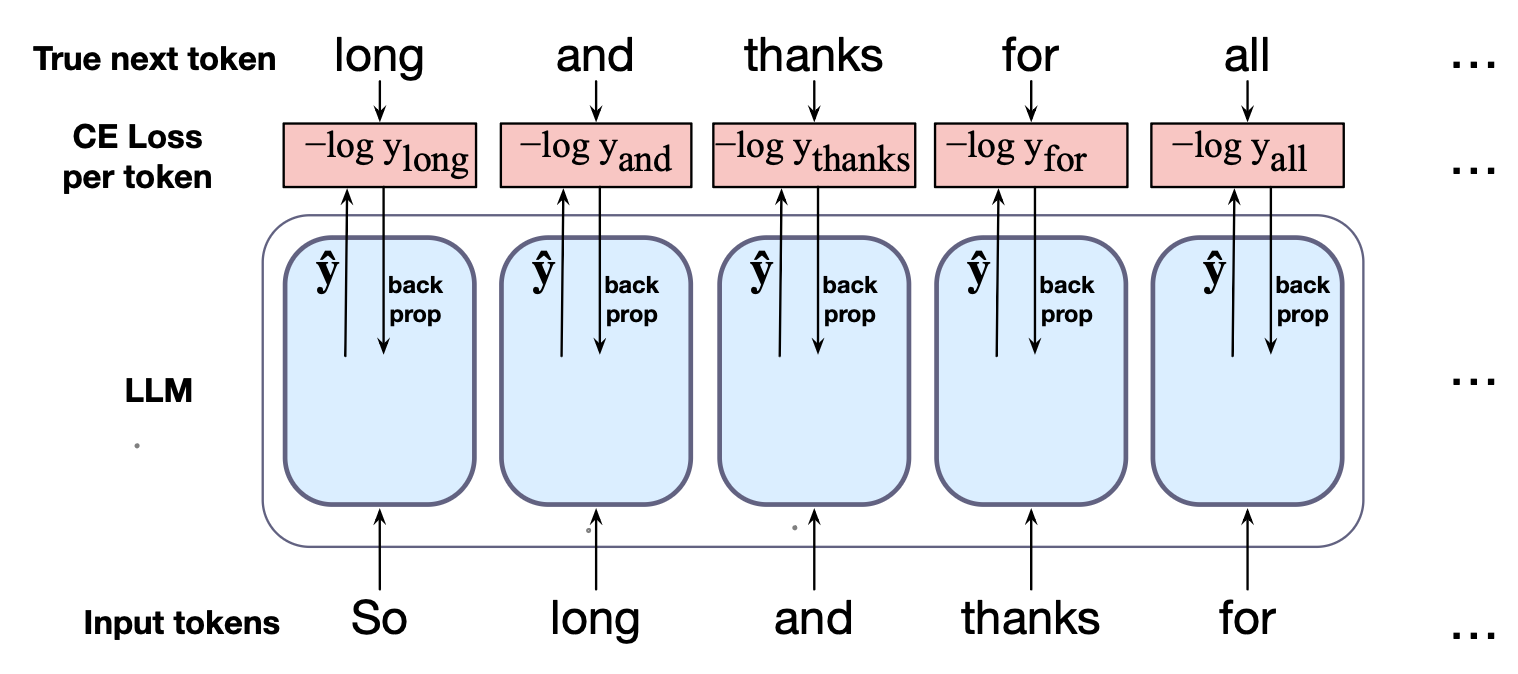
图 7.12 大语言模型训练的三个阶段:预训练(pretraining)、指令微调(instruction tuning)和偏好对齐(preference alignment)。
预训练(pretraining):
在第一阶段,模型在海量文本语料库上进行训练,目标是逐步预测下一个词。 训练采用交叉熵损失(有时称为语言建模损失),并通过反向传播将该损失信号贯穿整个网络。 训练数据通常来源于对互联网文本的大规模清洗与处理。 经过此阶段,模型具备了强大的词预测能力,并能生成连贯的文本。指令微调(instruction tuning),也称为监督微调(supervised finetuning, SFT):
在第二阶段,模型继续使用交叉熵损失进行训练,但目标变为遵循人类指令——例如回答问题、生成摘要、编写代码、翻译句子等。 为此,模型在一个专门构建的数据集上训练,该数据集包含大量“指令-正确响应”对。对齐(alignment),也称为偏好对齐(preference alignment):
在最后阶段,模型被进一步优化,以使其输出更有帮助且危害更小。 此时,模型接收的是偏好数据(preference data):每条数据包含一个上下文以及两个可能的后续生成结果,由人工(或其他方式)标注为“可接受”(accepted)或“应拒绝”(rejected)。 模型随后通过强化学习(reinforcement learning)或其他基于奖励的算法进行训练,目标是更倾向于生成被接受的续写,而非被拒绝的续写。
接下来我们将介绍预训练阶段,而指令微调与偏好对齐将在第 9 章详细讨论。
7.5.1 预训练的自监督训练算法
大语言模型预训练的核心思想,与我们在第 5 章学习词向量(如 word2vec)时所介绍的自训练(self-training)或自监督学习(self-supervision)是一致的。 在语言建模的自监督训练中,我们以一段文本语料作为训练材料,在每个时间步 $t$ 要求模型预测下一个词。 起初,模型在这个任务上表现很差,但由于我们始终知道正确答案(即语料中真实的下一个词!),随着时间推移,模型会越来越擅长预测正确的后续词元。 我们称这类模型为“自监督”的,是因为无需为数据额外添加人工标注的标签——词语本身的自然顺序就提供了监督信号! 我们只需训练模型,使其在预测训练序列中下一个真实词时的误差最小化。
在实践中,训练语言模型意味着调整其底层架构的参数。 我们将在下一章介绍的 Transformer 模型包含多个权重矩阵,分别用于前馈网络和注意力机制。 和所有神经网络一样,这些参数通过误差反向传播(backpropagation)配合梯度下降进行优化。 因此,我们只需要一个可最小化的损失函数,并将其误差信号反向传递回整个网络。 语言建模所使用的损失函数,正是我们在第 4 章和第 6 章已经见过两次的交叉熵损失(cross-entropy loss)。
回顾一下,交叉熵损失衡量的是模型预测的概率分布与真实分布之间的差异。 这里的分布是针对整个词元词汇表 $V$ 的,因此损失函数形式为:
$$ L_{CE} = -\sum_{w \in V} \mathbf{y}_t[w] \log \hat{\mathbf{y}}_t[w] \tag{7.5} $$在语言建模中,真实分布 $y_t$ 来源于我们知道的下一个词。 它被表示为一个one-hot 向量:在词汇表中,真实的下一个词对应的位置为 1,其余位置均为 0。 因此,语言建模的交叉熵损失实际上只取决于模型赋予正确下一个词的概率(公式 7.5 中其他项因乘以 0 而消失)。
于是,不失一般性地,我们可以将时间步 $t$ 处的交叉熵损失简化为:模型对训练序列中下一个词 $w_{t+1}$ 所分配概率的负对数,即 $-\log p(w_{t+1})$。 更正式地,用 $\hat{\mathbf{y}}_t$ 表示语言模型输出的词元概率估计向量,则损失可写作:
$$ L_{CE} (\hat{\mathbf{y}}_t, \mathbf{y}_t ) = -\log \hat{\mathbf{y}}_t [w_{t+1}] \tag{7.6} $$因此,在输入序列的每个位置 $t$,模型以正确的词元序列 $w_{1:t}$ 为输入,计算一个关于下一个可能词元的概率分布,并据此计算对真实下一个词元 $w_{t+1}$ 的损失。 接着,我们移动到下一个位置——忽略模型此前对 $w_{t+1}$ 的预测结果,而是直接使用真实的词元序列 $w_{1:t+1}$ 作为输入,让模型预测 $w_{t+2}$ 的概率。 这种始终将真实历史序列作为输入来预测下一个词(而不是使用模型上一步的预测结果作为输入)的做法,被称为教师强制(teacher forcing)。
图 7.13 展示了通用的训练流程。 在每一步中,给定所有先前的词元,语言模型会输出一个覆盖整个词汇表的概率分布。 在训练过程中,模型对正确词元所分配的概率被用于计算序列中每个位置的交叉熵损失。 每个批次(batch)的总损失是整个序列上所有负对数概率的平均交叉熵损失,形式化表示如下:
$$ L_{CE} (\text{长度为 } T \text{ 的批次}) = \frac{1}{T}\sum_{t=1}^T -\log \hat{\mathbf{y}}_t [w_t] \tag{7.7} $$随后,通过梯度下降(参见图 4.6),利用计算图上的误差反向传播来计算梯度,以最小化该批次的平均交叉熵损失。 训练调整网络中的所有权重, 对于将在下一章介绍的 Transformer 模型而言,这些权重包括词嵌入矩阵 $\mathbf{E}$,其中存储了每个词的嵌入向量。 因此,在训练过程中,模型会学习到那些最有助于预测后续词元的词嵌入表示。
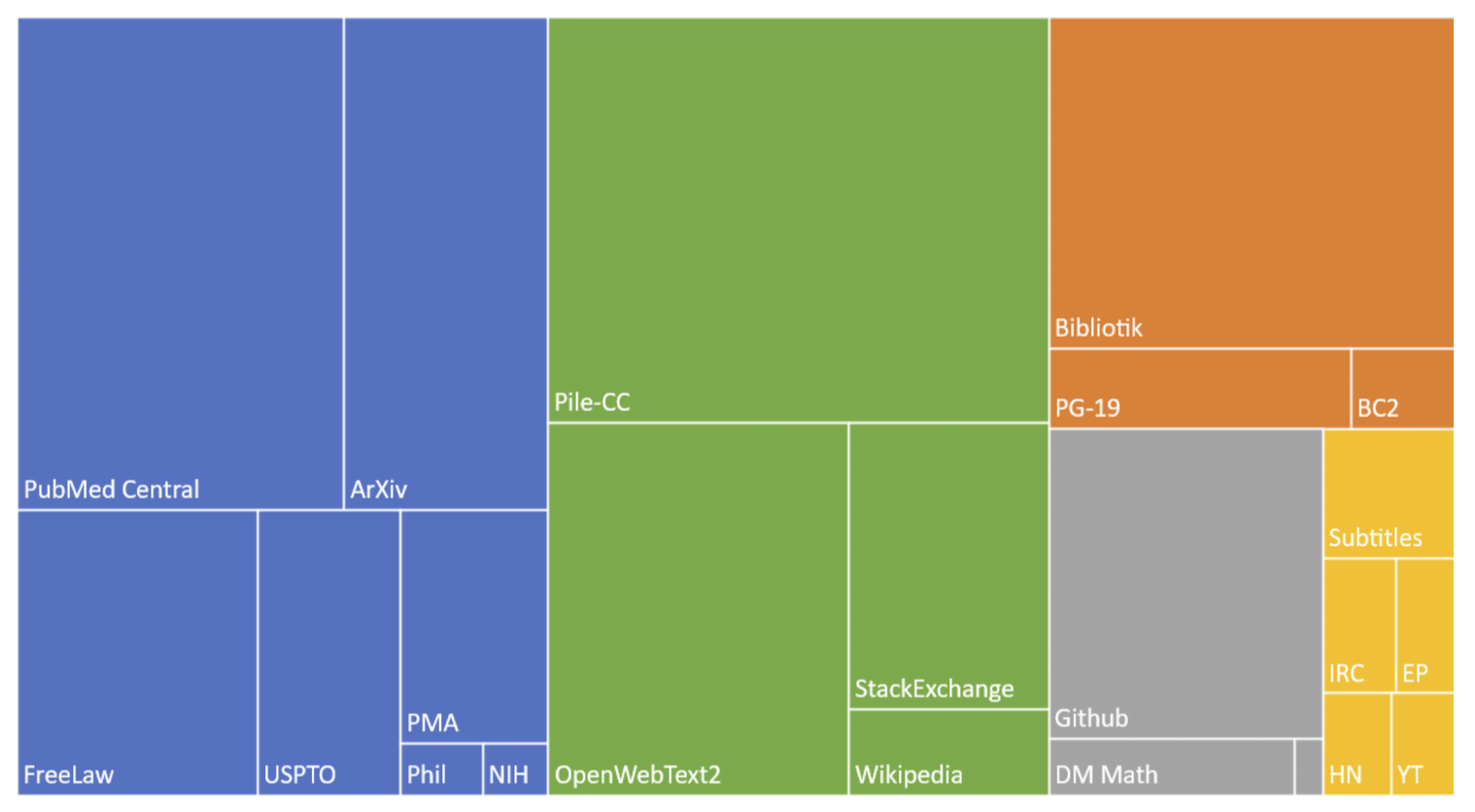
图 7.13 大语言模型(LLM)的训练过程。 在每个词元位置,模型输出 $\hat{y}$,即对所有可能下一个词的概率估计。 将模型对正确词元概率估计值取负对数,作为该位置的损失,再通过反向传播更新模型的所有参数(包括词嵌入)。 最终,一个批次中所有词元的损失会被平均,用于整体优化。
当然,训练的具体细节还取决于所采用的网络架构; 我们将在下一章专门介绍 Transformer 模型的更多训练细节。
7.5.2 大语言模型的训练语料
大语言模型主要在从网络抓取的文本上进行训练,并辅以更精心整理的数据。 由于这些训练语料规模极其庞大,其中很可能包含大量对自然语言处理任务有帮助的天然示例,例如问答对(如来自常见问题 FAQ 列表)、不同语言之间的句子翻译、文档及其摘要等。
网络文本通常来源于自动爬取的网页语料库,例如 common crawl,这是一个由非营利组织 Common Crawl(https://commoncrawl.org/)定期发布的全网快照系列,每个快照包含数十亿个网页。 Common Crawl 数据存在多个处理版本,例如 C4(Colossal Clean Crawled Corpus;Raffel et al., 2020),这是一个经过多种方式过滤的英文语料库,包含 1560 亿个词元(tokens),其过滤措施包括去重、移除非自然语言内容(如代码)、以及剔除包含屏蔽词列表中冒犯性词汇的句子。 据 Dodge 等人(2021)分析,C4 语料在很大程度上由专利文档、维基百科和新闻网站构成。
维基百科在众多语言模型的训练中扮演重要角色,书籍语料亦是如此。 The Pile(Gao et al., 2020)是一个 825 GB 的英文文本语料库,通过公开代码构建而成,同样包含大量网络爬取文本、书籍及维基百科内容;图 7.5 展示了其组成结构。 Dolma 是一个更大的开源英文语料库,使用公开工具构建,包含三万亿词元,内容涵盖网络文本、学术论文、代码、书籍、百科类资料以及社交媒体数据(Soldaini et al., 2024)。
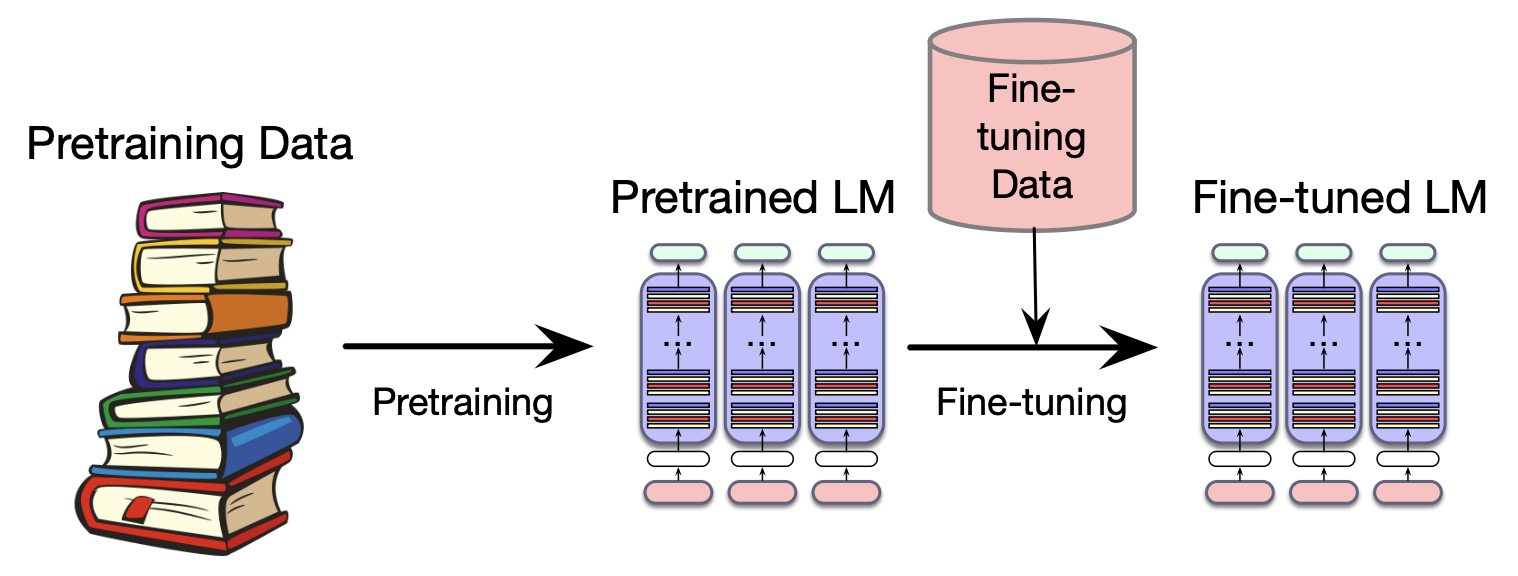
图 7.14 The Pile 语料库的组成部分及其规模,按颜色编码分类: 学术类(PubMed 与 arXiv 的论文、美国专利商标局 USPTO 的专利); 互联网类(网络文本,包括部分 Common Crawl 数据及维基百科); 散文类(大规模书籍语料); 对话类(含电影字幕与聊天数据); 其他类。 图片引自 Gao et al., 2020。
质量与安全过滤
从网络获取的预训练数据通常需经过质量与安全两方面的过滤。 质量过滤通常采用分类器为每篇文档打分。 由于“质量”本身具有主观性,不同过滤器的训练方式各异,但通常倾向于赋予维基百科、书籍及特定高质量网站更高权重,同时规避包含大量个人身份信息(PII, Personal Identifiable Information)或成人内容的网站。 此外,过滤器还会移除网络上极为常见的模板化文本(boilerplate text)。 另一种质量过滤手段是去重(deduplication),可在不同粒度上实施,例如去除重复文档、重复网页或重复文本片段。 研究表明,质量过滤通常能提升语言模型的性能(Longpre et al., 2024b;Llama Team, 2024)。
安全过滤同样涉及主观判断,通常依赖现成的毒性检测(toxicity detection)分类器来识别有害内容。 然而,这种做法效果参差不齐。 一方面,当前的毒性分类器常会误判少数群体方言(如非裔美国人英语)生成的无害文本为有毒内容(Xu et al., 2021)。 另一方面,在经毒性过滤的数据上训练出的模型,虽然自身输出的毒性略有降低,却也变得更难识别毒性内容(Longpre et al., 2024b)。 这些问题使得“如何实现更有效的安全过滤”成为一个重要的开放性难题。
使用大规模网络爬取数据训练语言模型,也引发了一系列伦理与法律争议:
版权问题:这些大型数据集中的大量文本(如小说与非虚构类书籍合集)受版权保护。在美国等国家,“合理使用”(fair use)原则可能允许将受版权保护的内容用于具有“转换性”的用途,但如果语言模型生成的文本与其训练数据在市场上形成直接竞争,则该原则是否依然适用尚不明确(Henderson et al., 2023)。
数据同意问题:网站所有者可通过
robots.txt文件或服务条款(Terms of Service)声明不希望其内容被网络爬虫抓取。近期,明确反对大语言模型开发者抓取其网站用于训练的站点数量急剧上升(Longpre et al., 2024a)。然而,这些声明在不同国家的法律效力尚不清晰,且是否具有追溯力也存在疑问,因此其对大规模预训练数据集的实际影响仍不确定。隐私问题:大型网络数据集还存在隐私隐患,因其可能包含电话号码、IP 地址等私人信息。尽管已有过滤机制试图移除可能包含大量个人信息的网站,但现有过滤措施仍显不足。在 7.7 节,我们会再次讨论隐私问题。
偏斜(Skew):训练数据大部分内容由来自美国及发达国家的作者生成,这很可能导致模型生成的内容过度偏向该群体的观点或关注的话题。
7.5.3 微调(Finetuning)
尽管大语言模型的预训练数据规模庞大、覆盖众多领域,但我们常常希望将其应用于某个新领域或新任务,而该领域或任务在预训练数据中可能并未充分出现。 例如,我们可能需要一个专门处理法律或医学文本的语言模型。 或者我们有一个支持多种语言的模型,但希望在其特定目标语言上进一步提升性能。
在这种情况下,我们可以直接在来自新领域或新语言的相关数据上继续训练该模型(Gururangan et al., 2020)。 这种在完整预训练模型基础上,使用新数据进行额外训练轮次的做法,称为微调(finetuning)。 “微调”一词指将预训练模型进一步调整其部分或全部参数以适应新数据的过程。 接下来几章,根据具体更新的参数不同,我们会看到使用“微调”的多种方式。 我们在这里描述的方法是继续训练,就像新数据放在了预训练数据后面一样,该方法有时也被称为持续预训练(continued pretraining)。 图 7.15 概括了这一范式。

图 7.6 预训练与微调。 一个预训练好的模型可被微调以适配特定领域、数据集或任务。 微调方式多种多样,取决于究竟更新哪些参数:全部参数、部分参数,或仅更新额外添加的特定模块参数,我们会在后续章节中看到。