语言模型在每一步应该生成哪个词元?
生成结果取决于每个词元的概率,所以我们先回顾一下这个概率分布的来源。 语言模型的内部网络(无论是 Transformer,还是 LSTM、状态空间模型等替代架构)会为词汇表中的每个词元生成一个称为logit 的得分(实数值)。 这个得分向量 $\mathbf{u}$ 随后通过 softmax 函数归一化,形成一个合法的概率分布——正如我们在第 4 章逻辑回归中所见。 所以,如果我们有一个形状为 $[1 \times |V|]$ 的 logit 向量 $\mathbf{u}$,其中每个元素对应一个可能的下一个词元的得分,那么将其通过 softmax 函数即可得到一个同样形状为 $[1 \times |V|]$ 的概率向量 $\mathbf{y}$,该向量为词汇表中每个词元分配一个概率,如下公式所示:
$$ \mathbf{y} = \text{softmax}(\mathbf{u}) \tag{7.1} $$图 7.7 展示了一个教学示例:为了便于说明,这里仅使用一个包含 4 个单词的简化词汇表来计算 softmax。
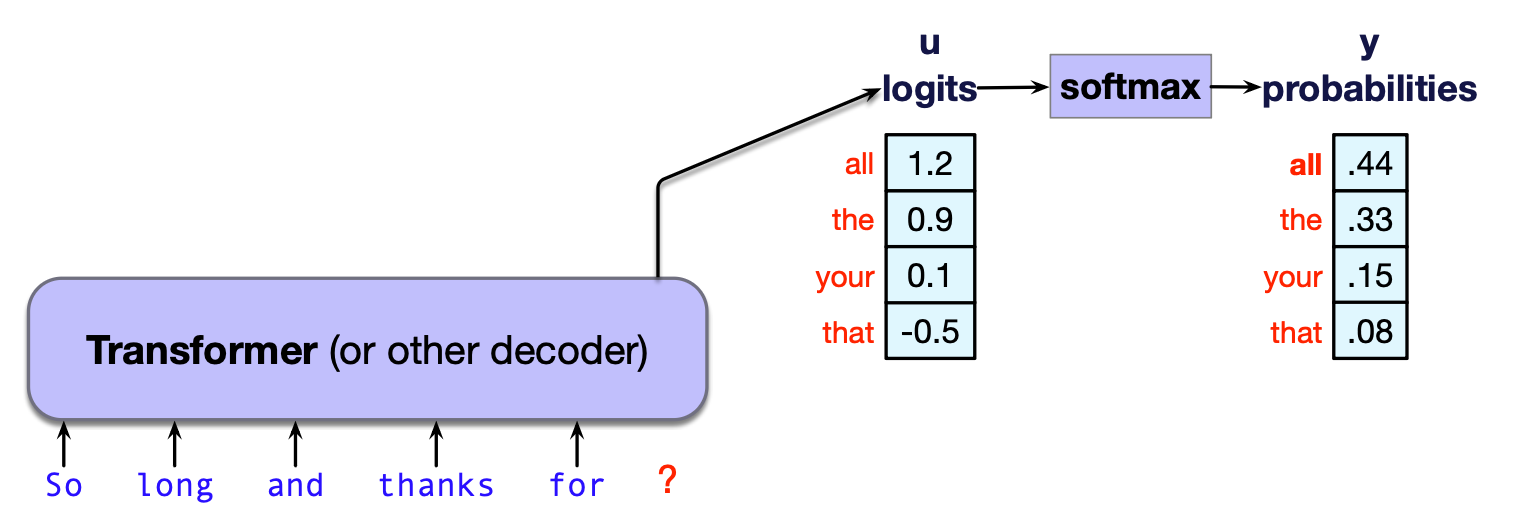
图 7.7 将 logit 向量 $\mathbf{u}$ 通过 softmax 转换为概率向量 $\mathbf{y}$。
现在,有了这个词元上的概率分布,我们需要从中选择一个词元进行生成。 这种根据模型给出的概率选择要生成的词元的过程,通常称为解码(decoding)。 如前所述,以从左到右的方式(对于阿拉伯语等从右向左书写的语言则是从右到左)进行解码,并在每一步基于之前已选词元不断选择下一个词元,这种生成方式被称为自回归生成(autoregressive generation)。1
7.4.1 贪心解码(Greedy decoding)
生成词元最简单的方法是:在每一步始终选择当前上下文中概率最高的词元,这种方法称为贪心解码(greedy decoding)。 贪心算法(greedy algorithm)是指在每一步都做出局部最优的选择,而不考虑该选择从全局来看是否最终最优。 因此,在贪心解码中,我们在每个生成时间步将 logits 转换为词元上的概率分布,然后选择概率最高的那个词元作为输出 $\hat{w}_t$(即取 argmax):
$$ \hat{w}_t = \mathrm{argmax}_{w \in V} \, P(w \mid \mathbf{w}_{< t}) \tag{7.2} $$图 7.8 显示,在我们的示例中,模型选择生成词元 all。
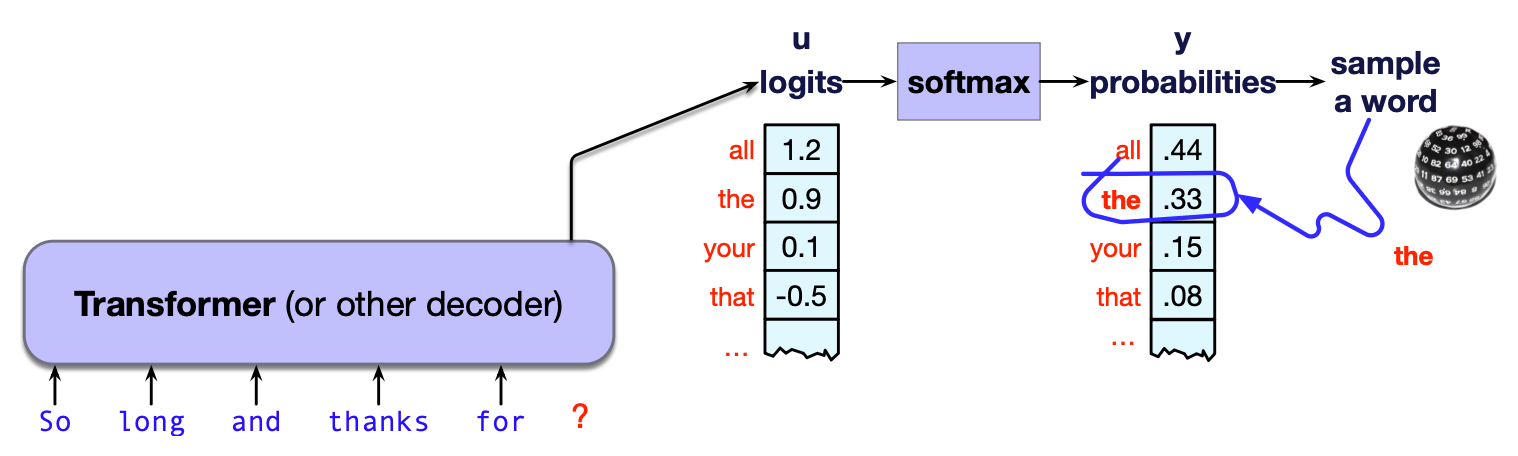
图 7.8 贪心解码:选择概率最高的词。
然而在实践中,我们通常不会在大语言模型中使用贪心解码。 贪心解码的一个主要问题是:它所选择的词元(根据定义)高度可预测,导致生成的文本往往千篇一律,甚至频繁重复。 事实上,贪心解码的可预测性如此之强,以至于它是确定性的——只要上下文相同、概率模型不变,贪心解码总会生成完全相同的字符串。
我们将在第 12 章看到,贪心解码的一种扩展方法束搜索(beam search),在机器翻译等任务中表现良好。这类任务具有很强的约束性:我们总是基于一段特定语言的输入文本,生成另一种语言的对应译文。
但在大多数其他任务中,人们更倾向于使用采样方法(sampling methods)生成的文本,因为这些方法能为输出引入更多样性和创造性。
7.4.2 随机采样(Random sampling)
因此,大语言模型中最常用的解码方法是采样(sampling)。 回想第3章的内容,从一个分布中采样意味着根据各结果的似然性随机选择。 因此,从语言模型(它表示了后续词元的概率分布)中采样,就是按照模型赋予每个词元的概率来选择下一个要生成的词元。 也就是说,模型认为概率高的词元更可能被生成,而概率低的词元则不太可能被选中。
具体而言,我们根据模型定义的上下文概率随机选择一个词元进行生成,然后重复这一过程。 可以将其想象成掷骰子,根据概率分布决定最终选中的词元,正如我们在第3章所见。 这样的模型当然更倾向于生成概率最高的词元(和贪心算法一样),但它也有可能生成任何其他词元,只是概率较低。 总体而言,模型认为概率高的词元更常出现,低概率词元则较少出现。
早在 Shannon(1948)以及 Miller 和 Selfridge(1950)的研究中,就已提出从语言模型中采样的想法。 我们在第 3 章第 48 页也看到过,如何通过不断根据 unigram 语言模型的概率随机采样词元,来生成文本,直到达到预设长度或采样到句尾标记(end-of-sentence token)为止。
对于大语言模型,我们只需对此方法稍作推广:在每一步,我们都根据此前已生成词元的条件概率来采样下一个词元,并使用大语言模型作为提供该概率的模型。
这种算法被称为随机采样(random sampling),或随机多项采样(random multinomial sampling)——因为我们是从一个跨词元的多项分布中进行采样。 我们可以将随机采样形式化如下:我们生成一个词元序列 $\{w_1, w_2, \dots, w_N\}$,直到遇到序列结束标记(EOS),其中用 $x \sim p(x)$ 表示“从分布 $p(x)$ 中采样得到 $x$”:
$$ \begin{align*} &i \gets 1 \\ &w_i \sim p(w) \\ &\textbf{while } w_i \text{ !}= \mathrm{EOS} \\ &\quad i \gets i + 1 \\ &\quad w_i \sim p(w_i \mid w_{< i}) \end{align*} $$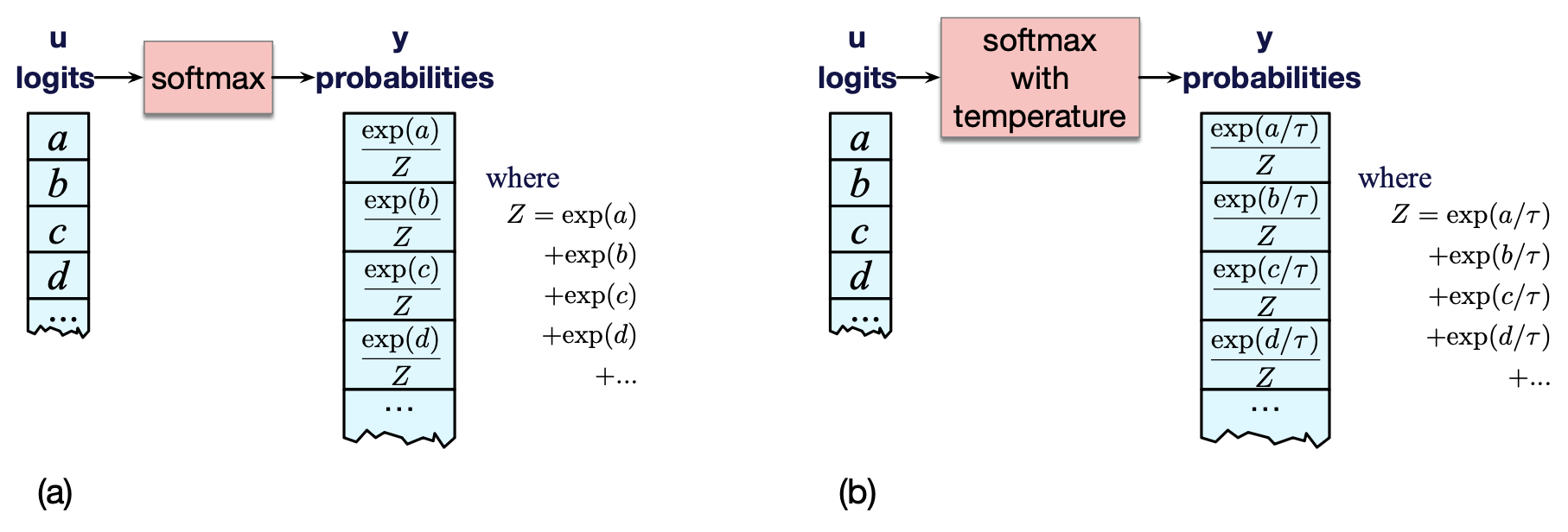
图 7.9 随机多项采样:根据词元的概率随机选择一个词。
然而遗憾的是,事实证明纯随机采样效果也不理想。 问题在于,尽管随机采样主要生成的是合理且高概率的词元,但概率分布的“长尾”中仍包含大量奇怪、低概率的词元。 虽然每个罕见词元的单独概率很低,但所有这些低概率词元加起来占据了分布中相当大的一部分,导致它们被选中的频率足以产生怪异甚至无意义的句子。
换句话说,贪心解码太乏味,而随机采样又太随意。 我们需要一种方法:既不每次都机械地选择概率最高的词元,又不会过度偏向那些极低概率的异常事件。
目前有三种标准的采样方法对随机采样进行了改进,以解决上述问题。本节将介绍最常用的一种——温度采样(temperature sampling);另外两种方法(top-k 和 top-p)将在下一章讨论。
7.4.3 温度采样(Temperature sampling)
温度采样(temperature sampling)的核心思想是:重塑概率分布,提高高概率词元的概率,同时降低低概率词元的概率。 这样做的结果是,我们更不容易生成极低概率的词元,而更倾向于生成那些相对高概率的词元。
具体实现方式非常简单:在将 logit 向量送入 softmax 进行归一化之前,先将其除以一个称为温度参数(temperature parameter)的标量 $\tau$。 在低温采样中,$\tau \in (0, 1]$。
通常,我们直接从 logit 计算词汇表上的概率分布,如以下公式所示(重复自公式 (7.3)):
$$ \mathbf{y} = \text{softmax}(\mathbf{u}) \tag{7.3} $$而在温度采样中,我们首先将 logits 除以 $\tau$,再计算概率向量 $\mathbf{y}$:
$$ \mathbf{y} = \text{softmax}(\mathbf{u}/\tau) \tag{7.4} $$也就是说,正常情况下,我们如图 7.10(a) 所示,直接对 logits 应用 softmax。 但使用温度参数时,我们先对 logits 进行缩放,如图 7.10(b) 所示。
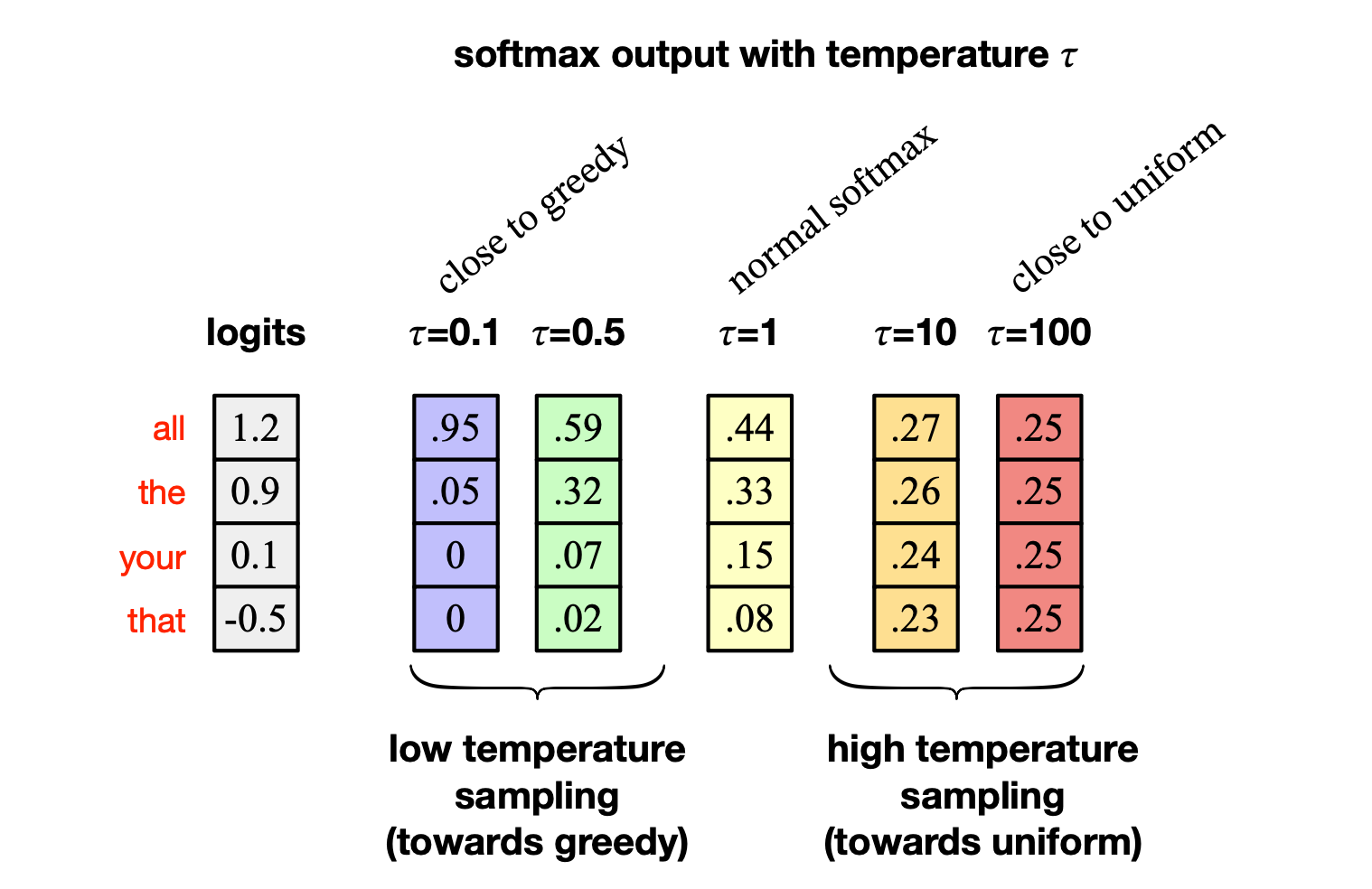
图 7.10 (a) 无温度缩放的标准 softmax;(b) 在 softmax 前先将 logits 除以温度参数 $\tau$,实现温度缩放。
为什么除以 $\tau$ 能增强高概率项、抑制低概率项? 当 $\tau = 1$ 时,我们执行的是标准 softmax,因此当 $\tau$ 接近 1 时,分布几乎不变。 但当 $\tau < 1$ 时,由于除以一个小于 1 的正数会使每个 logit 值变大,输入到 softmax 的数值就更大了。
回想一下 softmax 的一个重要性质:它会放大高值与低值之间的差距,高值更趋近于 1,低值更趋近于 0。 因此,当输入更大的数值时,softmax 输出的分布会更加“尖锐”:最高概率的词元概率进一步升高,低概率词元的概率则被进一步压缩,从而使分布更接近贪心选择。 特别地,当 $\tau \to 0$ 时,最可能词元的概率趋近于 1,此时温度采样就退化为贪心解码。
温度采样的原理来源于热力学:高温系统具有高度随机性,能探索大量可能的状态;而低温系统则倾向于停留在能量更低(即“更好”)的状态子集中。 在语言模型中,低温采样平滑地提升高概率词元的权重,同时抑制罕见词元。
图 7.11 展示了一个示意性例子(仍简化为仅含 4 个词元的词汇表:all、the、your、that),说明不同温度值如何影响从初始 logits 计算出的概率。 当 $\tau = 1$ 时,即为标准 softmax; 当 $\tau = 0.5$ 时,最高候选词的概率从 0.55 提升至 0.59; 当 $\tau = 0.1$ 时,其概率进一步大幅上升,使生成行为接近贪心解码。
图 7.11 不同 $\tau$ 值如何改变温度采样中由初始 logits 得到的最终概率。 本简化示例中,词汇表仅包含 4 个词元。
此外,图 7.11 也展示了另一种需求场景:有时我们希望压平(flatten)词元概率分布,而非使其更集中。 温度采样同样适用于这种情况,只需采用高温采样(high-temperature sampling),即令 $\tau > 1$。此时,概率分布会变得更均匀,模型输出更具随机性和多样性。
严格来说,自回归(autoregressive)模型是指在时间 $t$ 的预测值基于时间 $t-1, t-2, \dots$ 的值的线性函数。 尽管语言模型并非线性模型(因为如我们将在后续看到的,它们包含多层非线性变换),但我们仍宽泛地将这种生成方式称为“自回归”,因为在每一步生成的词元都依赖于网络在前一步所选择的词元。 正如我们将在第 10 章看到的,像 BERT 这类掩码语言模型属于非因果模型(non-causal),因为它们可以同时利用前后文信息来预测被遮盖的词元。 ↩︎