我们在上文描述的那种从左到右(或称自回归)的语言模型架构,也就是本章将要定义的架构,实际上只是三种常见语言模型架构之一。
这三种架构分别是:编码器(encoder)、解码器(decoder)和编码器-解码器(encoder-decoder)。 图 7.3 示意了这三种架构。
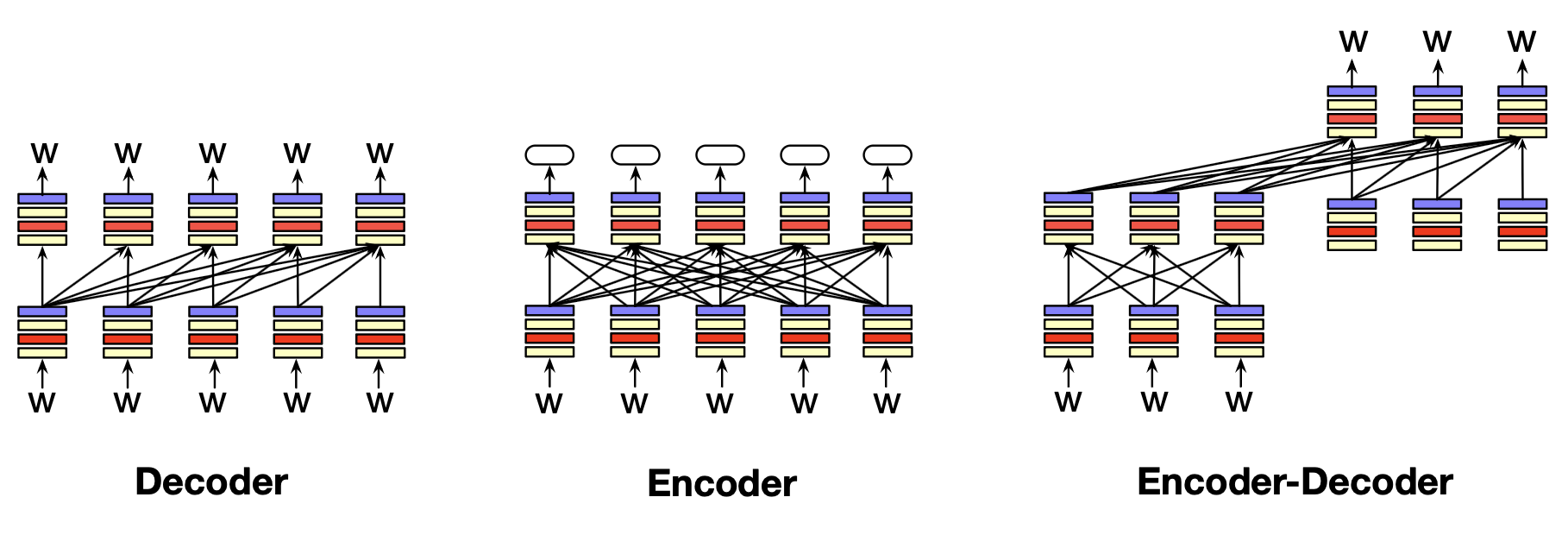
图 7.3 语言模型的三种架构:解码器、编码器和编码器-解码器。 箭头表示三种架构中的信息流向。 解码器:输入词元,输出词元。 编码器:输入词元,输出每个词元的向量表示(编码)。 编码器-解码器:输入词元,输出一串词元。
解码器(decoder)就是我们上面介绍的架构。 它接收一串词元作为输入,并逐个迭代地生成输出词元。 GPT、Claude、Llama 和 Mistral 等大语言模型均采用解码器架构。 解码器的信息流是从左到右的,即模型仅根据前面的词来预测下一个词。 解码器属于生成式模型,给定输入词元,它们能生成全新的输出词元。 本章剩余部分及第8章将重点讨论解码器。
编码器(encoder)接收一个词元序列作为输入,并为每个词元输出一个向量表示(即编码)。 编码器通常是掩码语言模型(masked language model),其训练方式是遮盖某个词,然后利用该词左右两侧的上下文来预测它。 BERT、RoBERTa 以及 BERT 系列的其他模型都属于编码器模型。 编码器不是生成式模型,不用于生成文本。 它们通常被用作分类器的基础,例如输入一段文本,输出一个标签(如情感倾向、主题类别等)。 这种用途通过微调(finetuning)实现(在有监督的数据上训练)。 我们将在第10章介绍编码器模型。
编码器-解码器(encoder-decoder)接收一个词元序列作为输入,并输出另一串词元。 它与纯解码器模型的关键区别在于:输入词元与输出词元之间的对应关系更松散,且常用于在不同类型词元之间进行映射。 也就是说,在编码器-解码器中,输出词元可能来自完全不同的词表,长度也可能远长于或短于输入。 例如,机器翻译就使用编码器-解码器架构:输入词元是一种语言,输出词元是另一种语言,且长度通常不同。 语音识别也采用这种架构:输入是代表语音的词元,输出是代表文本的词元。 我们将在第12章介绍用于机器翻译的编码器-解码器架构,在第15章介绍其在语音识别中的应用。
这三种架构可以用多种神经网络实现。 目前最广泛使用的网络类型是Transformer,我们将在第8章介绍。 在 Transformer 中,每个输入词元都会经过一列 Transformer 层的处理,每一层由若干不同类型的子网络组成。 第13章将介绍一种较早但仍具影响力的架构——LSTM(一种循环神经网络)。 此外,还有许多更新的架构,例如状态空间模型(state space models)。
本书大部分内容将聚焦于 Transformer,但就本章而言,我们将保持架构中立:把实现解码器功能的网络视为一个黑箱。 该黑箱的输入是一串词元,输出是一个可从中采样的词元概率分布。 我们将以与具体网络无关的方式,描述学习与解码的机制。