“在任意时刻,我们究竟知道多少?我相信,远比我们意识到自己知道的要多得多。”
——阿加莎·克里斯蒂,《移动的手指》

幻想文学中充满了被赋予说话能力的无生命物体。 从奥维德笔下皮格马利翁的雕像,到玛丽·雪莱创作的弗兰肯斯坦故事,人类不断重述着这样一类故事:创造出某物,然后与它交谈。 传说米开朗基罗完成《摩西》雕像后,觉得它栩栩如生,竟轻拍它的膝盖,命令它开口说话。 这或许并不奇怪。语言是人类智慧与意识的标志。对话是最基本的语言场景。这是我们儿时最先学会的语言形式,也是我们日常持续使用的语言方式——无论是在教学或学习、点午餐,还是与家人朋友交谈。
本章介绍大语言模型(Large Language Model,简称 LLM)——一种能与人类进行对话交互的计算智能体。 LLM 专为与人交互而设计,这一事实对其架构和应用具有深远影响。
早在60年前,一个名为 ELIZA 的计算系统(Weizenbaum, 1966)就已揭示了这些影响。 ELIZA 被设计成模拟罗杰斯学派的心理治疗师。它凸显了聊天机器人面临的若干关键问题。 例如,用户会深深投入情感,进行极为私密的对话,甚至有人要求 Weizenbaum 在他们打字时离开房间。 这种情感投入与隐私问题提醒我们:必须审慎部署语言模型,并认真考虑其对交互者的影响。
本章首先介绍 LLM 的计算原理;下一章将讨论其在 Transformer 架构中的具体实现。 使 LLM 成为可能的核心新思想是预训练(pretraining)。因此,我们先从“从文本中学习”这一基本思路入手,这也是 LLM 训练的基本方式。
流畅使用语言的人,在理解和产出过程中会调动海量知识。 这些知识表现为多种形式,其中最显而易见的便是词汇,即我们对词语及其意义与用法所构建的丰富表征。 正因如此,词汇成为一个有效视角,来探索人类与机器如何从文本中获取知识。
对成年人词汇量的估计,在不同语言内部及跨语言之间差异巨大。 例如,据估计,讲美国英语的年轻人,词汇量介于3万到10万之间,差异取决于所采用的资源,以及对“掌握一个词”的定义不同。 由此可简单推知:儿童必须每天学习约7到10个新词,日复一日,才能在20岁时达到观测到的词汇水平。 事实上,从小学高年级到高中阶段的实证研究也证实了这一增长速率。 儿童是如何实现如此高速的词汇增长的? 研究表明,大部分词汇知识是在阅读过程中附带习得的。 阅读是一种丰富的语境处理过程。我们并非孤立地逐个学习单词。 事实上,在某些学习阶段,词汇增长的速度甚至超过了新词出现的频率! 这表明,每次阅读一个词时,我们也在强化对与之相关其他词的理解。
这些事实与第5章提出的分布假设(distributional hypothesis)一致。该假设认为,意义的某些方面仅凭我们一生所接触的文本即可习得,其依据是词语与其共现词之间的复杂关联(以及这些共现词自身的共现关系)。 分布假设指出:我们能从文本中获取大量知识,且这些知识可在初次习得很久之后仍被有效调用。 当然,结合现实世界的交互或其他模态信息,可以构建更强大的模型。但即便仅使用文本,效果也已非常显著。
现代自然语言处理革命之所以成为可能,正是因为大语言模型能够通过在(非常)大规模文本语料中反复根据上下文预测下一个词,从而习得关于语言、语境乃至世界的全部知识。 在本章及下一章中,我们将形式化这一思想,并称之为预训练——即通过在海量文本中迭代预测词元(token),来学习语言与世界知识。经此过程得到的模型,称为大语言模型。 正因预训练所获得的知识,大语言模型在各类自然语言任务上展现出卓越性能。
语言模型能从词语预测中学到什么? 请看下面的例子。 你认为模型在学习预测下划线处应填入哪个词时(正确答案以蓝色标出),可能学到哪些类型的知识? 在继续阅读下一段之前,请先针对每个例子思考一下:
With roses, dahlias, and peonies, I was surrounded by ____ flowers
(玫瑰、大丽花和牡丹环绕着我,我被____花朵包围了)The room wasn’t just big it was ____ enormous
(这个房间不只是大,而是____巨大)The square root of 4 is ____ 2
(4 的平方根是____ 2)The author of “A Room of One’s Own” is ____ Virginia Woolf
(《一间自己的房间》的作者是____ 弗吉尼亚·伍尔夫)The professor said that ____ he
(教授说____他)
从第一句中,模型可以学到本体论知识,比如玫瑰、大丽花和牡丹都属于花朵。 从第二句,模型可能理解“enormous”与“big”属于同一尺度,但程度更强。 第三句能让系统学到数学知识;第四句则传递关于世界和历史人物的事实。 最后一句则带来一个警示:如果模型反复接触这类句子,可能会将“教授”仅与男性代词关联,从而习得可能导致对不同人群不公平对待的偏见性关联。
什么是大语言模型? 如第3章所述,语言模型本质上是一个能根据前面的词预测下一个词的计算系统。 也就是说,给定一段上下文(或前缀),语言模型会为所有可能的后续词分配一个概率分布。 图7.1示意了这一思想。
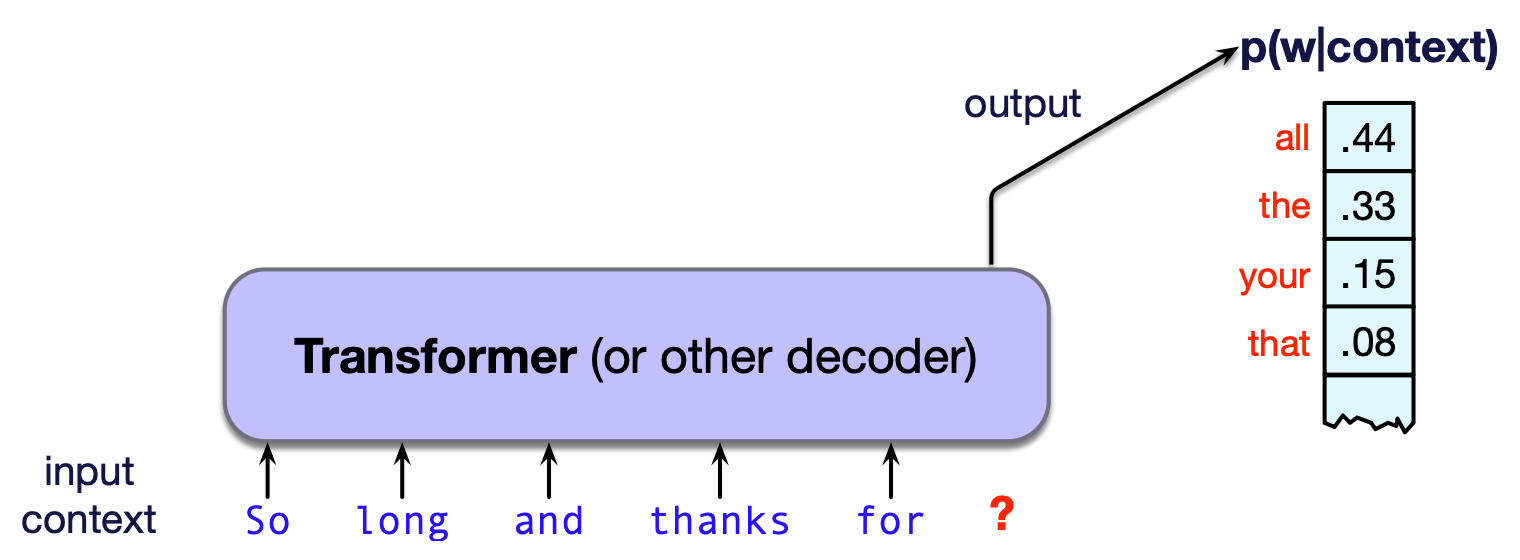
图 7.1 大语言模型是一种神经网络,输入一段上下文(或前缀),输出一个关于可能下一个词的概率分布。
当然,我们此前已经接触过语言模型!第3章介绍了 n-gram 语言模型,第6章简要提及了用于语言建模的前馈神经网络。 大语言模型只是这些模型的(大幅)扩展版本。 例如,第3章中的 bigram 和三元 trigram 模型只能基于前一个或少数几个词进行预测。 而大语言模型则能利用数千甚至数万个词的上下文来预测下一个词!
语言模型的基本原理是,一个能够预测文本(即为后续词分配概率分布)的模型,也可以通过采样(sampling)该分布来生成文本。 正如第 3 章所述,“采样”是指从概率分布中随机选择一个词。
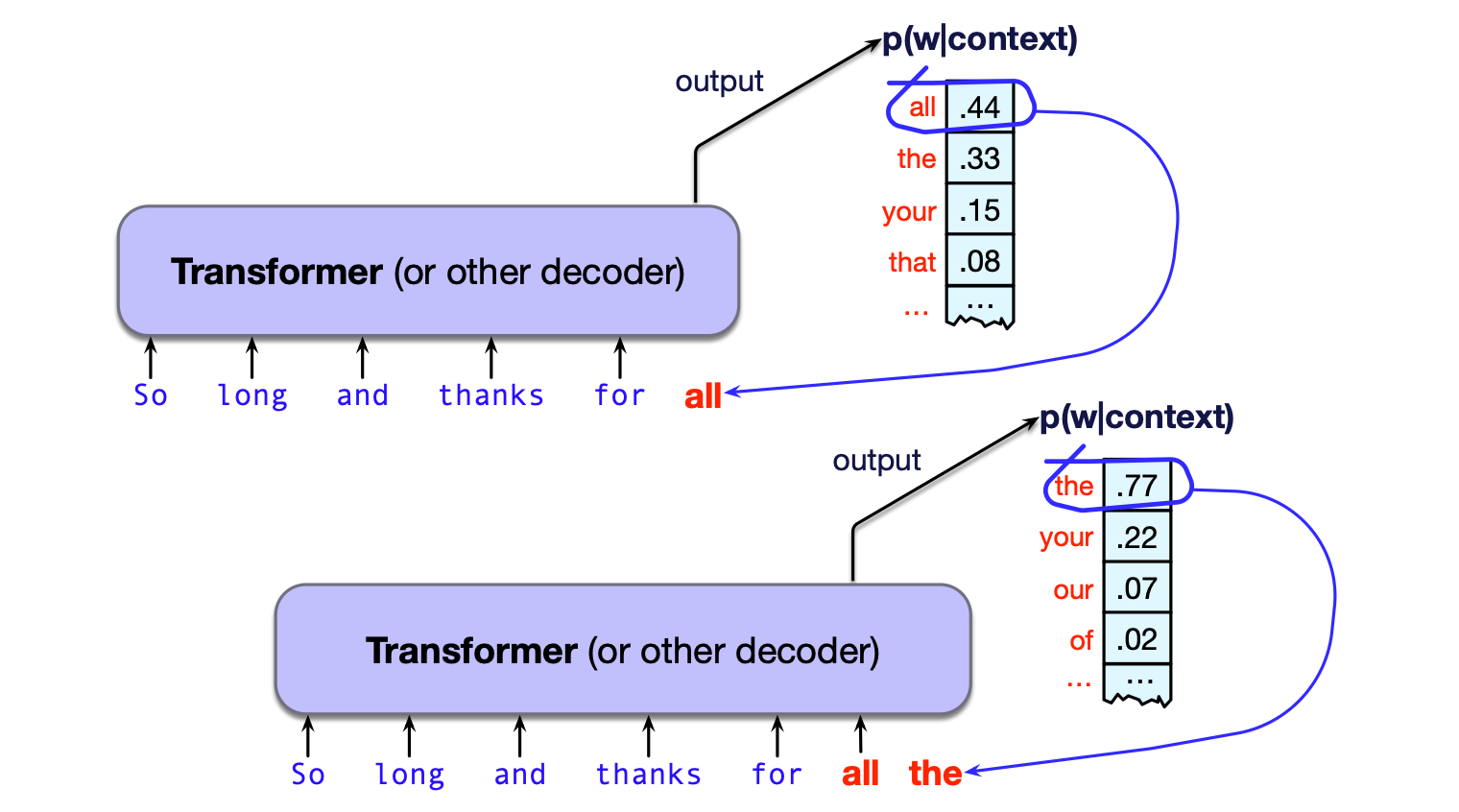
图 7.2 将一个给出下一词概率分布的预测模型,通过反复采样转化为生成模型。 结果是一种从左到右(也称为自回归)的语言模型。 每生成一个词元(token),就将其添加到上下文中,作为生成下一个词元的前缀。
图 7.2 展示了与图 7.1 相同的例子:语言模型接收一段文本前缀,并生成一个可能的补全文本。
模型首先选出单词 all,将其加入上下文;然后用更新后的上下文获得新的预测分布;再从中采样出下一个词(如 the)并生成,依此类推。
注意,模型的预测不仅依赖于初始提示(priming context),还依赖于它自己先前生成的内容。
这种从左到右、基于已生成词逐步预测并生成新词的方式,通常被称为因果语言模型(causal language model)或自回归语言模型(autoregressive language model)。 (我们将在第10章介绍非自回归模型,如 BERT 等掩码语言模型——它们利用左右两侧的信息来预测被遮盖的词。)
利用计算模型生成文本,以及代码、语音和图像,构成了一个重要的新领域——生成式人工智能(generative AI)。 将 LLM 应用于文本生成,极大地拓展了自然语言处理(NLP)的范畴。传统 NLP 更侧重于解析或理解文本的算法,而非生成文本。
在本章剩余部分,我们将看到:只要采用恰当的方式,几乎任何 NLP 任务都可以被建模为大语言模型中的词语预测问题。 我们将引入并阐释提示(prompting)语言模型的思想。 我们还会介绍具体的文本生成算法,如贪心解码(greedy decoding)和采样(sampling)。 我们会详细说明预训练(pretraining)——即语言模型如何通过不断学习从前文预测下一个词来自我训练。 此外,我们还将概述语言模型训练的另外两个阶段:指令微调(instruction tuning,也称监督微调,SFT)和对齐(alignment)——这些概念将在第9章深入讨论。 最后,我们也会探讨如何评估这些模型。 不过,在此之前,让我们先谈谈不同类型的语言模型。