前馈神经网络属于监督式机器学习的一种:对于每个输入样本 $\mathbf{x}$,我们已知其对应的真实输出 $\mathbf{y}$。
系统通过公式 6.13 生成的是预测输出 $\hat{\mathbf{y}}$,即模型对真实标签 $\mathbf{y}$ 的估计。
训练的目标,就是为每一层 $i$ 学习到合适的参数 $\mathbf{W}^{[i]}$ 和 $\mathbf{b}^{[i]}$,使得对每个训练样本,模型的预测 $\hat{\mathbf{y}}$ 尽可能接近真实值 $\mathbf{y}$。
总体而言,我们采用第 5 章介绍的逻辑回归训练方法来实现这一目标,因此读者在继续阅读之前应已熟悉该章内容。 我们将探索简单通用网络的算法,而不是专门针对情感或语言建模设计的网络。
首先,我们损失函数(Loss Function)来衡量模型输出与真实标签之间差距,通常采用逻辑回归中使用的交叉熵损失(cross-entropy loss)作为损失函数。
其次,为了找到使损失函数最小化的参数,我们使用第 5 章介绍的梯度下降(gradient descent)算法。
第三,梯度下降要求我们知道损失函数关于所有参数的梯度——即一个包含损失函数对每个参数偏导数的向量。 在逻辑回归中,我们可以直接计算损失函数对某个权重 $w$ 或偏置 $b$ 的导数。 但在神经网络中,模型往往包含数百万个分布在多层中的参数,这就带来了一个难题:当损失是在网络末端计算的,我们如何求出第一层中某个权重对最终损失的偏导数? 换言之,如何将损失“分配”回所有中间层? 解决这一问题的算法就是著名的误差反向传播(error backpropagation),也称为反向自动微分(backward differentiation)。
6.6.1 损失函数
神经网络中使用的交叉熵损失(cross-entropy loss)与我们在逻辑回归中见到的完全相同。 如果神经网络被用作二分类器(即输出层使用 sigmoid 激活函数),其损失函数就与公式 (4.23) 中的逻辑回归损失一致:
$$ \begin{align*} L_{\text{CE}}(\hat{y}, y) &= -\log p(y \mid \mathbf{x}) \\ = -\big[ y \log \hat{y} + (1 - y) \log(1 - \hat{y}) \big] \tag{6.25} \end{align*} $$如果网络用于三类或更多类别的分类任务,则损失函数与第 5 章第 80 页介绍的多项逻辑回归(multinomial regression)损失完全相同。为方便起见,我们在此简要回顾其要点。 当类别数超过两类时,我们需要将真实标签 $\mathbf{y}$ 和预测结果 $\hat{\mathbf{y}}$ 都表示为向量。 假设我们执行的是硬分类(hard classification),即每个样本仅属于一个正确类别。 此时,真实标签 $\mathbf{y}$ 是向量,有 $K$ 个元素,每个元度对应一个类别,其中若正确类别为 $c$,则 $\mathbf{y}_c = 1$,其余元素均为 0。 回忆一下,这种仅有一个元素为 1、其余为 0 的向量称为 one-hot 向量(独热向量)。 -分类器输出的预测向量 $\hat{\mathbf{y}}$ 同样包含 $K$ 个元素,每个元素 $\hat{y}_k$ 表示模型估计的条件概率 $p(\mathbf{y}_k = 1 \mid \mathbf{x})$。
对于单个样本 $\mathbf{x}$,其交叉熵损失定义为:对所有 $K$ 个输出类别的对数概率加权求和,权重即为真实标签中的 one-hot 值,再取负号:
$$ L_{\text{CE}}(\hat{\mathbf{y}}, \mathbf{y}) = -\sum_{k=1}^{K} \mathbf{y}_k \log \hat{\mathbf{y}}_k \tag{6.26} $$我们可以进一步简化该式。引入指示函数 $\mathds{1}\{\cdot\}$,当括号内条件成立时值为 1,否则为 0。 这样重写后,显然,在公式 6.26 的求和项中,只有对应真实类别 $c$(即 $y_c = 1$)的那一项非零,其余均为 0:
$$ L_{\text{CE}}(\hat{\mathbf{y}}, \mathbf{y}) = -\sum_{k=1}^{K} \mathds{1}\{\mathbf{y}_k = 1\} \log \hat{\mathbf{y}}_k $$因此,交叉熵损失实际上就是正确类别所对应预测概率的负对数,也因此被称为 负对数似然损失(negative log likelihood loss):
$$ L_{\text{CE}}(\hat{\mathbf{y}}, \mathbf{y}) = -\log \hat{\mathbf{y}}_c \quad \text{(其中 } c \text{ 为正确类别)} \tag{6.27} $$将第 6.9 式中的 softmax 公式代入,可得:
$$ L_{\text{CE}}(\hat{\mathbf{y}}, \mathbf{y}) = -\log \frac{\exp(\mathbf{z}_c)}{\sum_{j=1}^{K} \exp(\mathbf{z}_j)} \quad \text{(其中 } c \text{ 为正确类别)} \tag{6.28} $$让我们思考一下为何“负对数概率”是一个理想的损失函数: 一个完美分类器会为正确类别分配概率 1,为所有错误类别分配概率 0。 因此,正确类别的预测概率 $\hat{y}_c$ 越高(越接近 1),模型表现越好;越低(越接近 0),表现越差。 负对数函数恰好具备理想的性质:当 $\hat{y}_c = 1$ 时,$-\log(1) = 0$(无损失);当 $\hat{y}_c \to 0$ 时,$-\log(\hat{y}_c) \to \infty$(损失趋于无穷大)。 此外,这个损失函数还保证了,最大化正确类别的概率必然导致所有错误类别的概率最小化,这是由于 softmax 输出的概率总和为 1,因此,正确类别的概率增大,错误类别必然概率降低。
输出向量 $\hat{\mathbf{y}}$ 的类别数 $K$ 可大可小。 假设我们的任务是三分类情感分析,类别可以是“正面”、“负面”、“中性”。 若任务是词性标注(判断一个词是名词、动词还是形容词等),则 $K$ 等于标注集中的词性标签数量(例如第 17 章定义的标注集包含 17 种词性)。 如果任务是语言建模(预测下一个词),则类别集合就是整个词汇表,$K$ 可能达到 5 万甚至 10 万。
6.6.2 梯度的计算
我们该如何计算这个损失函数的梯度呢? 计算梯度需要求出损失函数对每个参数的偏导数。 对于仅含一个权重层并采用 sigmoid 输出的网络(也就是逻辑回归),我们可以直接使用第 6.29 式中用于逻辑回归的损失函数导数(该导数已在第 4.15 节中推导过):
$$ \begin{align*} \frac{\partial L_{CE} (\hat{\mathbf{y}},\mathbf{y})}{\partial w_j} &= (\hat{y} - y)\mathbf{x}_j \\ &= (\sigma(\mathbf{w} \cdot \mathbf{x} + b) - y)\mathbf{x}_j \tag{6.29} \end{align*} $$或者,对于仅含一个权重层并采用 softmax 输出的网络(即多项逻辑回归),我们可以使用第 5.48 式中的 softmax 损失函数导数。以下展示了针对某个特定权重 $w_{k,i}$ 和输入 $\mathbf{x}_i$ 的形式:
$$ \begin{align*} \frac{\partial L_{CE}(\hat{\mathbf{y}},\mathbf{y})}{\partial w_{k,i}} &= -(\mathbf{y}_k - \hat{\mathbf{y}}_k)\mathbf{x}_i \\ &= -(\mathbf{y}_k - p(\mathbf{y}_k = 1|\mathbf{x}))\mathbf{x}_i \\ &= -\left(\mathbf{y}_k - \frac{\exp(\mathbf{w}_k \cdot \mathbf{x} + b_k)}{\sum^K_{j=1} \exp(\mathbf{w}_j \cdot \mathbf{x} + b_j)}\right) \mathbf{x}_i \tag{6.30} \end{align*} $$然而,这些导数仅适用于单一层权重的情况——而且只能正确更新最后一层的权重! 对于深度网络而言,计算每个权重的梯度要复杂得多,因为我们需要对那些出现在网络非常靠前层中的权重参数求导,而损失函数却只在网络最末端进行计算。
解决这一梯度计算问题的算法被称为 误差反向传播(error backpropagation),简称 反向传播(backprop)(Rumelhart 等,1986)。 虽然反向传播最初是专门为神经网络设计的,但后来发现它实际上等同于一种更通用的方法——反向微分(backward differentiation),而该方法依赖于计算图(computation graphs)的概念。 我们将在下一小节中具体介绍其工作原理。
6.6.3 计算图
计算图(computation graph)是一种表示数学表达式计算过程的结构,它将整个计算分解为若干独立的基本运算,每个运算在图中被建模为一个节点。
考虑计算函数 $L(a,b,c) = c(a + 2b)$。 如果我们显式地写出其中每一步加法和乘法操作,并为中间结果引入变量名(例如 $d$ 和 $e$),那么整个计算过程可表示为:
$$ \begin{align*} d &= 2 \cdot b \\ e &= a + d \\ L &= c \cdot e \end{align*} $$现在,我们可以将这一过程表示为一张有向图:每个运算对应一个节点,节点之间的有向边表示前一个运算的输出作为后一个运算的输入,如图 6.15 所示。 计算图最简单的用途是:给定具体输入值,计算函数的输出结果。 在图中,我们假设输入为 $a = 3$、$b = 1$、$c = -2$,并展示了前向传播(forward pass)的过程,最终得到结果 $L(3,1,-2) = -10$。 在计算图的前向传播中,我们从左到右依次执行每个运算,并将每个节点的输出传递给后续节点作为输入。
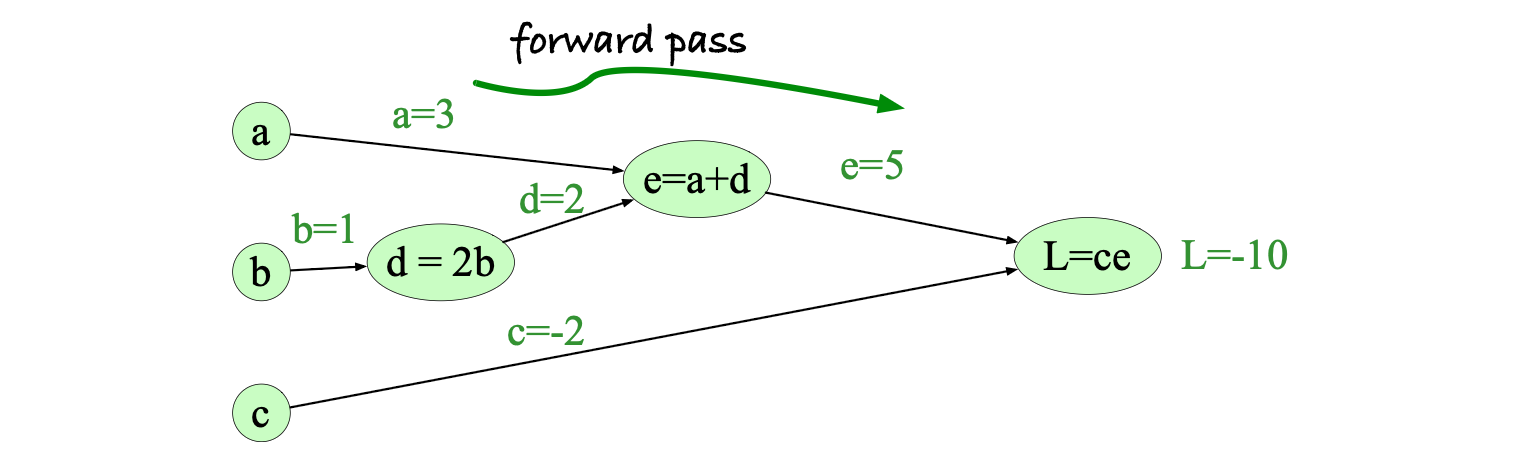
图 6.15 函数 $L(a,b,c) = c(a + 2b)$ 的计算图。图中给出了输入节点的取值 $a = 3$、$b = 1$、$c = -2$,并展示了前向传播计算 $L$ 的过程。
6.6.4 计算图上的反向微分
计算图的重要性主要体现在反向传播(backward pass)过程中,该过程用于计算我们在权重更新时所需的导数。 在本例中,我们的目标是计算输出函数 $L$ 对每个输入变量的偏导数,即 $\frac{\partial L}{\partial a}$、$\frac{\partial L}{\partial b}$ 和 $\frac{\partial L}{\partial c}$。 其中,导数 $\frac{\partial L}{\partial a}$ 告诉我们:当 $a$ 发生微小变化时,$L$ 会受到多大影响。
反向微分利用了微积分中的链式法则(chain rule),让我们先回顾一下该法则。 假设我们要计算复合函数 $f(x) = u(v(x))$ 的导数。 $f(x)$ 的导数等于外层函数 $u$ 对内层函数 $v$ 的导数,乘以内层函数 $v$ 对 $x$ 的导数:
$$ \frac{df}{dx} = \frac{du}{dv} \cdot \frac{dv}{dx} \tag{6.31} $$链式法则可推广到两个以上的函数。例如,若 $f(x) = u(v(w(x)))$,则其导数为:
$$ \frac{df}{dx} = \frac{du}{dv} \cdot \frac{dv}{dw} \cdot \frac{dw}{dx} \tag{6.32} $$反向微分的核心思想是:将梯度从最终输出节点向后传递至图中的所有节点。 图 6.16 展示了在某个节点 $e$ 处的部分反向计算过程。 每个节点接收来自其右侧父节点传入的“上游梯度”(upstream gradient),然后针对自身的每个输入,计算一个“局部梯度”(local gradient,即该节点输出对其输入的偏导数),再利用链式法则将上游梯度与局部梯度相乘,从而得到要传递给前一个(更早)节点的“下游梯度”(downstream gradient)。
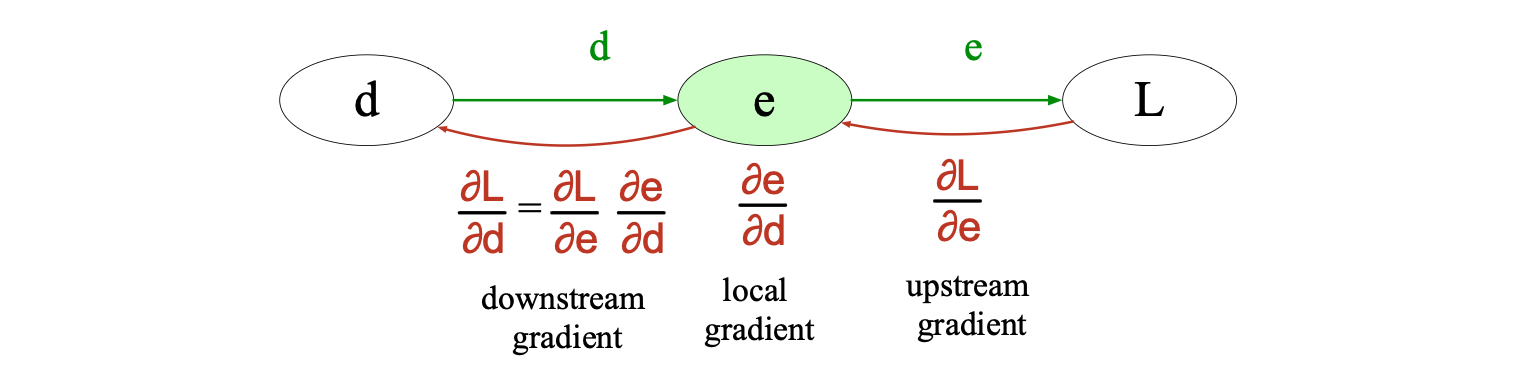
图 6.16 每个节点(例如此处的 $e$)接收一个上游梯度,将其与局部梯度(即该节点输出对其输入的导数)相乘,并通过链式法则计算出要传递给前序节点的下游梯度。 如果一个节点有多个输入,它就可能对应多个局部梯度。
现在,我们来具体计算所需的三个导数。 由于在计算图中有 $L = c e$,我们可以直接求出:
$$ \frac{\partial L}{\partial c} = e \tag{6.33} $$而对于另外两个导数,则需要使用链式法则:
$$ \begin{align*} \frac{\partial L}{\partial a} &= \frac{\partial L}{\partial e} \cdot \frac{\partial e}{\partial a} \\ \frac{\partial L}{\partial b} &= \frac{\partial L}{\partial e} \cdot \frac{\partial e}{\partial d} \cdot \frac{\partial d}{\partial b} \tag{6.34} \end{align*} $$因此,式 6.33 和 6.34 共涉及五个中间偏导数: $\frac{\partial L}{\partial e}$、$\frac{\partial L}{\partial c}$、$\frac{\partial e}{\partial a}$、$\frac{\partial e}{\partial d}$ 和 $\frac{\partial d}{\partial b}$。 利用“和的导数等于导数的和”这一性质,这些导数分别为:
$$ \begin{align*} L = c e &:\quad \frac{\partial L}{\partial e} = c,\quad \frac{\partial L}{\partial c} = e \\ e = a + d &:\quad \frac{\partial e}{\partial a} = 1,\quad \frac{\partial e}{\partial d} = 1 \\ d = 2b &:\quad \frac{\partial d}{\partial b} = 2 \end{align*} $$在反向传播过程中,我们从右向左沿着计算图的每条边,依次计算这些偏导数,并像上面那样应用链式法则。 具体来说,我们首先从节点 $L$ 开始,计算它传递给前驱节点的下游梯度:$\frac{\partial L}{\partial e}$ 和 $\frac{\partial L}{\partial c}$。 接着,在节点 $e$ 处,我们将接收到的上游梯度 $\frac{\partial L}{\partial e}$ 乘以局部梯度 $\frac{\partial e}{\partial d}$,得到要传递给节点 $d$ 的梯度 $\frac{\partial L}{\partial d}$。 如此继续,直到所有输入变量($a, b, c$)都获得对应的梯度。 值得注意的是,前向传播过程已经为我们计算并存储了所需的中间变量值(如 $d$ 和 $e$),这些值在反向计算导数时会被直接使用。 图 6.17 展示了完整的反向传播过程。
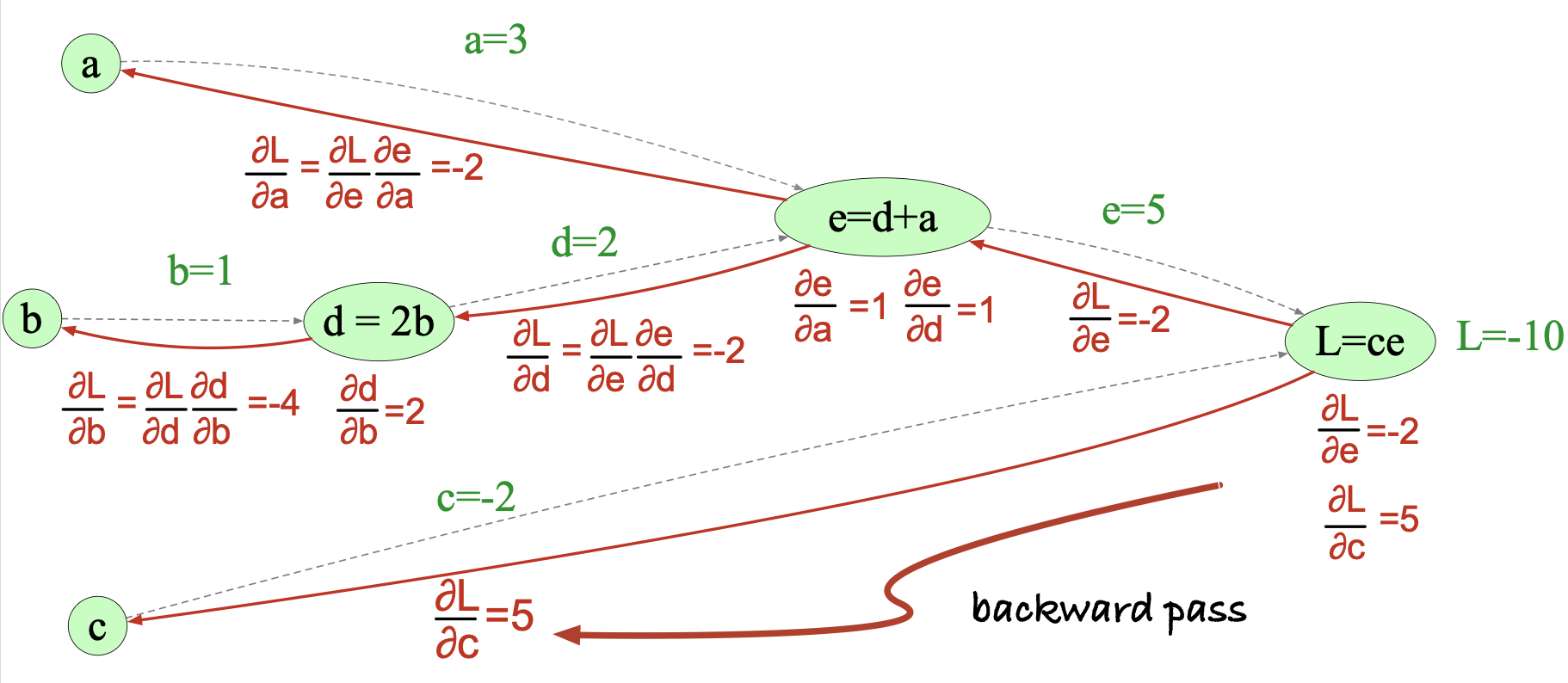
图 6.17 函数 $L(a,b,c) = c(a + 2b)$ 的计算图,展示了反向传播过程中对 $\frac{\partial L}{\partial a}$、$\frac{\partial L}{\partial b}$ 和 $\frac{\partial L}{\partial c}$ 的计算。
神经网络的反向微分
当然,实际神经网络的计算图要复杂得多。 图 6.18 展示了一个简单两层神经网络(即含一个隐藏层)的计算图示例,其中输入层维度 $n_0 = 2$,隐藏层维度 $n_1 = 2$,输出层维度 $n_2 = 1$。为简化起见,假设是二分类任务,因此输出单元采用 sigmoid 激活函数。 该计算图所表示的函数如下:
$$ \begin{align*} \mathbf{z}^{[1]} &= \mathbf{W}^{[1]}\mathbf{x} + \mathbf{b}^{[1]} \\ \mathbf{a}^{[1]} &= \mathrm{ReLU}(\mathbf{z}^{[1]}) \\ z^{[2]} &= \mathbf{W}^{[2]}\mathbf{a}^{[1]} + b^{[2]} \\ a^{[2]} &= \sigma(z^{[2]}) \\ \hat{y} &= a^{[2]} \tag{6.35} \end{align*} $$在反向传播中,我们还需要计算损失 $L$。 根据第 6.25 式,二分类 sigmoid 输出对应的交叉熵损失函数为:
$$ L_{CE} (\hat{y}, y) = -\big[ y \log \hat{y} + (1 - y) \log(1 - \hat{y}) \big] \tag{6.36} $$由于我们的输出 $\hat{y} = a^{[2]}$,可将上式改写为:
$$ L_{CE} (a^{[2]}, y) = -\big[ y \log a^{[2]} + (1 - y) \log(1 - a^{[2]}) \big] \tag{6.37} $$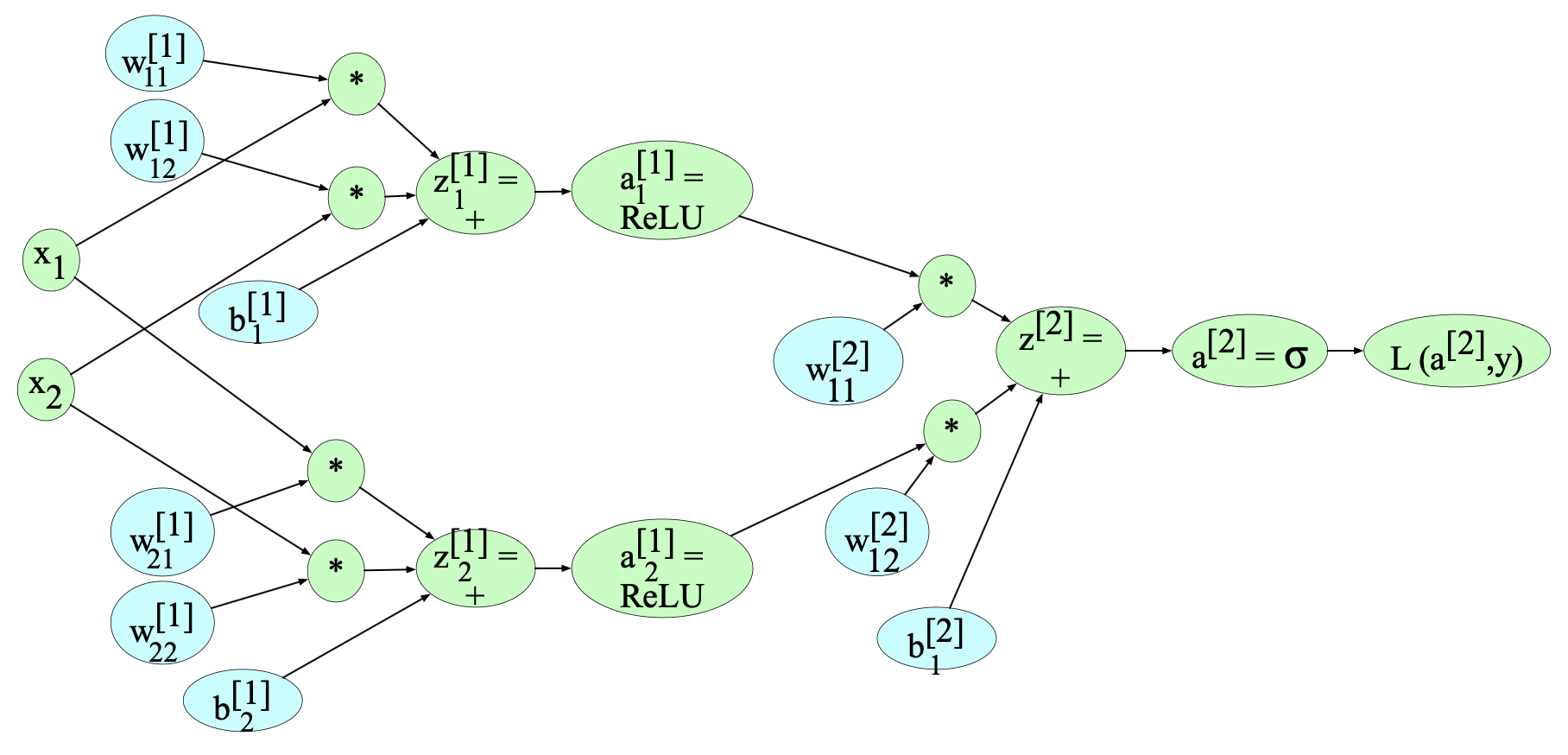
图 6.18 一个简单两层神经网络(即含一个隐藏层)的计算图示例,包含两个输入单元和两个隐藏单元。为避免节点内公式过长,图中略作记号调整:仅标明所执行的函数及生成的变量名。例如,节点 $w^{[1]}_{11}$ 右侧的 “*” 表示 $w^{[1]}_{11}$ 需与 $x_1$ 相乘;而节点 $z^{[1]} = +$ 表示 $z^{[1]}$ 的值由输入它的三个节点(两个乘积项和偏置项 $b^{[1]}_i$)相加得到。
图中以青绿色(teal)标出的是需要更新的权重(即我们需要计算损失函数对其偏导数的参数)。 为了进行反向传播,我们还需知道图中所有函数的导数。 我们在第 4.15 节已见过 sigmoid 函数 $\sigma$ 的导数:
$$ \frac{d\sigma(z)}{dz} = \sigma(z)(1 - \sigma(z)) \tag{6.38} $$此外,我们还需要其他激活函数的导数。 tanh 函数的导数为:
$$ \frac{d\,\tanh(z)}{dz} = 1 - \tanh^2(z) \tag{6.39} $$ReLU 函数的导数为1:
$$ \frac{d\,\text{ReLU}(z)}{dz} = \begin{cases} 0 & \text{若 } z < 0 \\ 1 & \text{若 } z \geq 0 \end{cases} \tag{6.40} $$下面我们给出反向计算的开头部分:计算损失函数 $L$ 对 $z^{[2]}$ 的偏导数 $\frac{\partial L}{\partial z^{[2]}}$(其余计算留作读者练习)。 根据链式法则:
$$ \frac{\partial L}{\partial z^{[2]}} = \frac{\partial L}{\partial a^{[2]}} \cdot \frac{\partial a^{[2]}}{\partial z^{[2]}} \tag{6.41} $$首先计算 $\frac{\partial L}{\partial a^{[2]}}$。对式 (6.37) 求导:
$$ \begin{align*} L_{CE}(a^{[2]}, y) &= -\big[ y \log a^{[2]} + (1 - y) \log(1 - a^{[2]}) \big] \\ \frac{\partial L}{\partial a^{[2]}} &= -\left( y \cdot \frac{\partial \log(a^{[2]})}{\partial a^{[2]}} + (1 - y) \cdot \frac{\partial \log(1 - a^{[2]})}{\partial a^{[2]}} \right) \\ &= -\left( y \cdot \frac{1}{a^{[2]}} + (1 - y) \cdot \frac{1}{1 - a^{[2]}} \cdot (-1) \right) \\ &= -\left( \frac{y}{a^{[2]}} - \frac{1 - y}{1 - a^{[2]}} \right) \\ &= -\left( \frac{y}{a^{[2]}} + \frac{y - 1}{1 - a^{[2]}} \right) \tag{6.42} \end{align*} $$接着,利用 sigmoid 的导数:
$$ \frac{\partial a^{[2]}}{\partial z^{[2]}} = a^{[2]} (1 - a^{[2]}) \tag{6.43a} $$最后,应用链式法则:
$$ \begin{align*} \frac{\partial L}{\partial z^{[2]}} &= \frac{\partial L}{\partial a^{[2]}} \cdot \frac{\partial a^{[2]}}{\partial z^{[2]}} \\ &= -\left( \frac{y}{a^{[2]}} + \frac{y - 1}{1 - a^{[2]}} \right) \cdot a^{[2]} (1 - a^{[2]}) \\ &= a^{[2]} - y \tag{6.43} \end{align*} $$接下来的反向梯度计算(例如将梯度传递给偏置 $b^{[2]}_1$、两个乘积节点,并继续向后传播至所有青绿色标记的权重节点)就留给读者作为练习了。
6.6.5 关于学习的更多细节
神经网络中的优化是一个非凸优化问题,比逻辑回归更为复杂。正因如此,以及出于其他原因,实践中已发展出许多确保成功训练的最佳实践。
在逻辑回归中,我们可以将梯度下降的初始权重和偏置全部设为 0。 但在神经网络中,必须使用小的随机数来初始化权重。 此外,对输入数据进行归一化(使其均值为 0、方差为 1)也非常有帮助。
为了防止过拟合,通常会采用多种形式的正则化(regularization)。 其中最重要的一种是 Dropout(Hinton 等,2012;Srivastava 等,2014):在训练过程中,随机“丢弃”网络中的一些神经元及其连接。 具体来说,在每次训练迭代(即使用小批量梯度下降时的每个 mini-batch)中,我们设定一个丢弃概率 $p$,然后对每一层中的每个神经元,以概率 $p$ 将其输出置为零,并对剩余神经元的输出进行重新缩放(renormalize),以保持整体激活规模稳定。
超参数(hyperparameters)的调整同样至关重要。 神经网络的参数是指权重 $\mathbf{W}$ 和偏置 $\mathbf{b}$,它们通过梯度下降进行学习。 而超参数则是由算法设计者预先设定的配置项,其最优值需在开发集(dev set)上进行调优,而非通过在训练集上的梯度下降自动学习得到。 常见的超参数包括:学习率 $\eta$;小批量大小(mini-batch size) ;模型结构(层数、每层隐藏单元数量、激活函数的选择);正则化方式(如是否使用 Dropout、L2 正则化强度等),等等。 此外,梯度下降本身也有多种改进架构,例如 Adam 优化器(Kingma and Ba, 2015)。
最后,现代绝大多数神经网络都基于计算图的形式体系构建,这种体系天然支持高效的梯度计算,并能充分利用面向向量运算的 GPU(图形处理器)进行并行加速。 目前最流行的两个深度学习框架是 PyTorch(Paszke 等,2017)和 TensorFlow(Abadi 等,2015)。 有兴趣的读者可参考专门的神经网络教材以获取更深入的细节;本章末尾提供了一些推荐读物。
严格来说,ReLU 在 $z = 0$ 处不可导,但按惯例我们将其导数视为 1。 ↩︎