虽然人工设计特征是构建分类器的传统方法,但大多数 NLP 中的神经网络应用并不使用人工构造的特征作为输入。 相反,我们利用深度学习从数据中自动学习特征的能力,将词元(token)表示为嵌入向量(embeddings)。 在本节中,我们将使用第 5 章介绍过的静态词嵌入方法(如 word2vec 或 GloVe)来表示每个词元。 所谓静态嵌入(static embedding),是指每个词元都由一个固定的向量表示——该向量在预训练阶段一次性学习完成,之后存入一个大型字典中。 每当需要引用某个词元时,我们只需从该字典中取出其对应的嵌入向量即可。
然而,当我们把神经网络模型应用于语言建模任务(如第 8 章所述)时,情况会更复杂:我们会使用一种更强大的嵌入形式,称为上下文嵌入(contextual embedding)。 上下文嵌入的特点是:同一个词在不同上下文中会有不同的嵌入表示。 此外,网络在执行词语预测任务的过程中,会学习到这些嵌入。
现在,让我们回到前一节的文本分类场景,但改用静态嵌入作为输入特征,而非人工设计的特征。 我们聚焦于推理阶段,此时所有输入词元的嵌入已经预先训练好。 每个嵌入是一个维度为 $d$ 的向量,用于表示一个输入词元。 存储这些嵌入的字典被称为嵌入矩阵(embedding matrix)$\mathbf{E}$。 嵌入矩阵 $\mathbf{E}$ 的每一行对应词汇表 $V$ 中的一个词元,表示为一个 $d$ 维的(行)向量。 词汇表中有 $|V|$ 个词元,每个词元在 $\mathbf{E}$ 中对应一行,因此 $\mathbf{E}$ 的形状为 $[|V| \times d]$。 只要在神经 NLP 系统的输入中使用嵌入,这个嵌入矩阵 $\mathbf{E}$ 就扮演核心角色,包括后续章节将介绍的基于 Transformer 的大语言模型。
给定一个输入词元序列,例如 dessert was great,我们首先将其转换为词汇表中的索引(这些索引是在最初使用 BPE 或 SentencePiece 进行词元化时生成的)。
于是,dessert was great 可能被表示为索引序列 $\mathbf{w} = [3, 9824, 226]$
接着,通过索引从嵌入矩阵 $\mathbf{E}$ 中选取对应的行(例如第 3 行、第 9824 行、第 226 行),从而得到每个词元的嵌入向量。
对于从嵌入矩阵中提取词元嵌入,另一种理解方式是:首先将输入词元表示为 one-hot 向量(独热向量),每个 one-hot 向量的形状为 $[1 \times |V|]$,即维度与词汇表大小相同。 回忆一下,在 one-hot 向量中,除对应词元索引位置的元素为 1 外,其余所有元素均为 0。 例如,若词 “dessert” 在词汇表中的索引为 3,则其 one-hot 向量中, $x_3 = 1$,$x_i = 0 \forall i \neq 3$,即:
[0 0 1 0 0 0 0 ... 0 0 0 0]
1 2 3 4 5 6 7 ... |V|
此时,将嵌入矩阵 $\mathbf{E}$ 与该 one-hot 向量相乘,由于 one-hot 向量中仅有一个非零元素 $x_i = 1$,结果就等价于选出 $\mathbf{E}$ 的第 i 行。这一过程如图 6.11 所示。
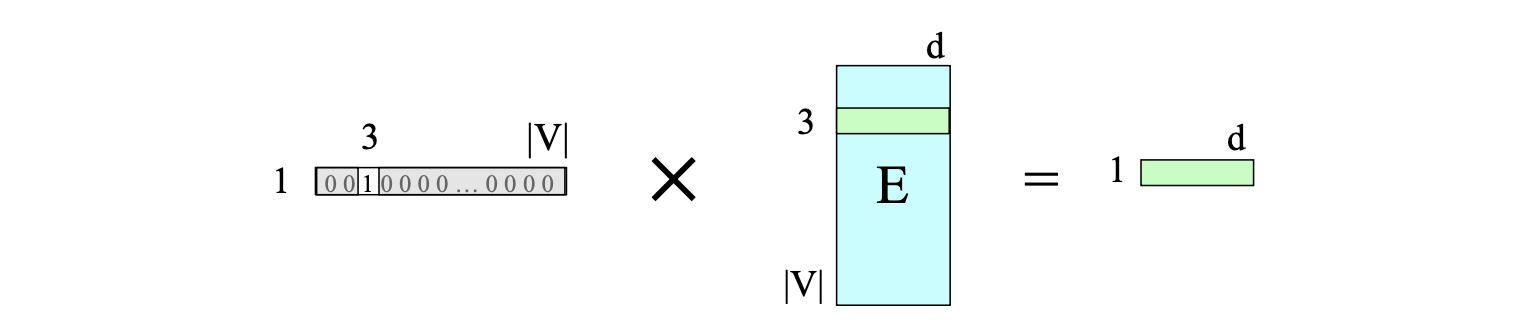
图 6.11 通过将嵌入矩阵 $\mathbf{E}$ 与在索引 3 处为 1 的 one-hot 向量相乘,选出词 $V_3$ 的嵌入向量。
我们可以将这一思想推广到整个输入序列:将长度为 $N$ 的输入词元序列表示为一个 one-hot 矩阵,其中每一行对应一个输入位置的 one-hot 向量,如图 6.12 所示。
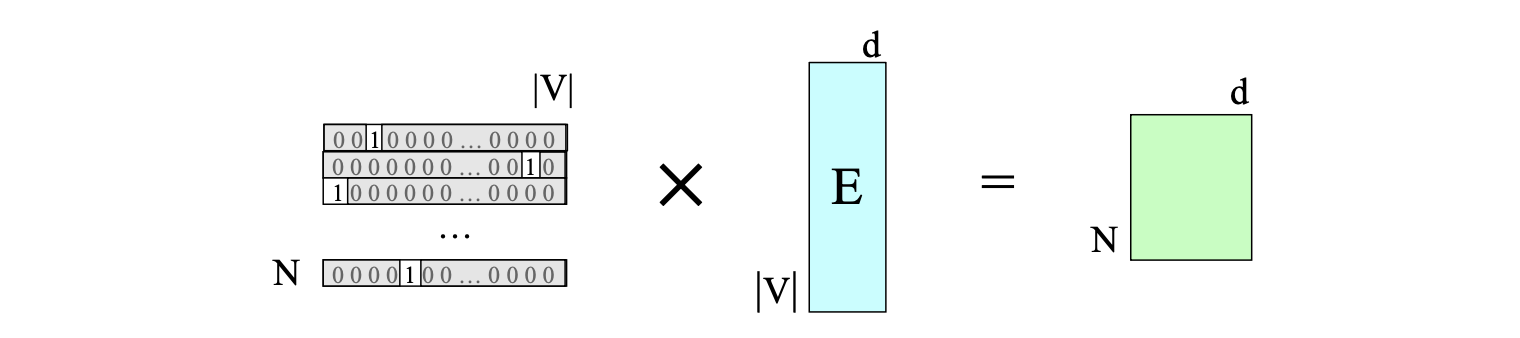
图 6.12 通过将对应词元索引序列 $\mathbf{W}$ 的 one-hot 矩阵与嵌入矩阵 $\mathbf{E}$ 相乘,一次性选出整个输入序列的嵌入矩阵。
现在,我们需要将这个由 N 个 $[1×d]$ 嵌入组成的输入(对应一个 N 词元的窗口)整体分类为单一类别(如“正面”或“负面”)。
将嵌入输入分类器有两种常见方式:拼接(concatenation)和池化(pooling,指对多个向量进行特征聚合)。 第一种方法是将形状为 $[N \times d]$ 的输入通过拼接(concatenating)所有词元的嵌入向量,重塑为一个长度为 $dN$ 的长向量(形状为 $[1 \times dN]$)。 然后将其送入分类器进行决策。 这种方法保留了丰富的信息,但代价是需要较大的网络参数量。 第二种方法是对这 $N$ 个嵌入进行池化(pooling),将其压缩为一个单一的 $d$ 维嵌入,再将该池化后的向量送入分类器。 池化会丢失部分原始嵌入中的细节信息,但其优势在于模型更小、计算更高效,尤其适用于那些对原始词序不敏感的任务。 下面我们分别举例说明:情感分析任务使用池化,语言建模任务使用拼接。
用于情感分析的输入嵌入池化
我们首先看池化如何应用于情感分类任务。 其核心原理是:在判断情感时,某个词(如 “great”)出现在第几个位置(是第一个词?第二个词?)并不如这个词本身的身份重要。
池化函数的作用是将一组嵌入向量聚合为单个嵌入向量。
例如,对于一段包含 $N$ 个词/词元 $w_1, \dots, w_N$ 的文本,我们希望将对应的 $N$ 个行向量嵌入 $\mathbf{e}(w_1), \dots, \mathbf{e}(w_N)$(每个维度为 $d$)合并成一个同样维度为 $d$ 的单一嵌入。
池化有多种方式。 最简单的是均值池化(mean-pooling):将所有嵌入向量相加后除以 $N$:
$$ \mathbf{x}_{\text{mean}} = \frac{1}{N} \sum_{i=1}^{N} \mathbf{e}(w_i) \tag{6.21} $$采用均值池化的分类器计算流程如下:
$$ \begin{align*} \mathbf{x} &= \mathrm{mean}\big( \mathbf{e}(w_1), \mathbf{e}(w_2), \dots, \mathbf{e}(w_N) \big) \\ \mathbf{h} &= \sigma(\mathbf{xW} + \mathbf{b}) \\ \mathbf{z} &= \mathbf{hU} \\ \hat{\mathbf{y}} &= \mathrm{softmax}(\mathbf{z}) \tag{6.22} \end{align*} $$该架构如图 6.13 所示,图中还标注了所有相关矩阵的形状。
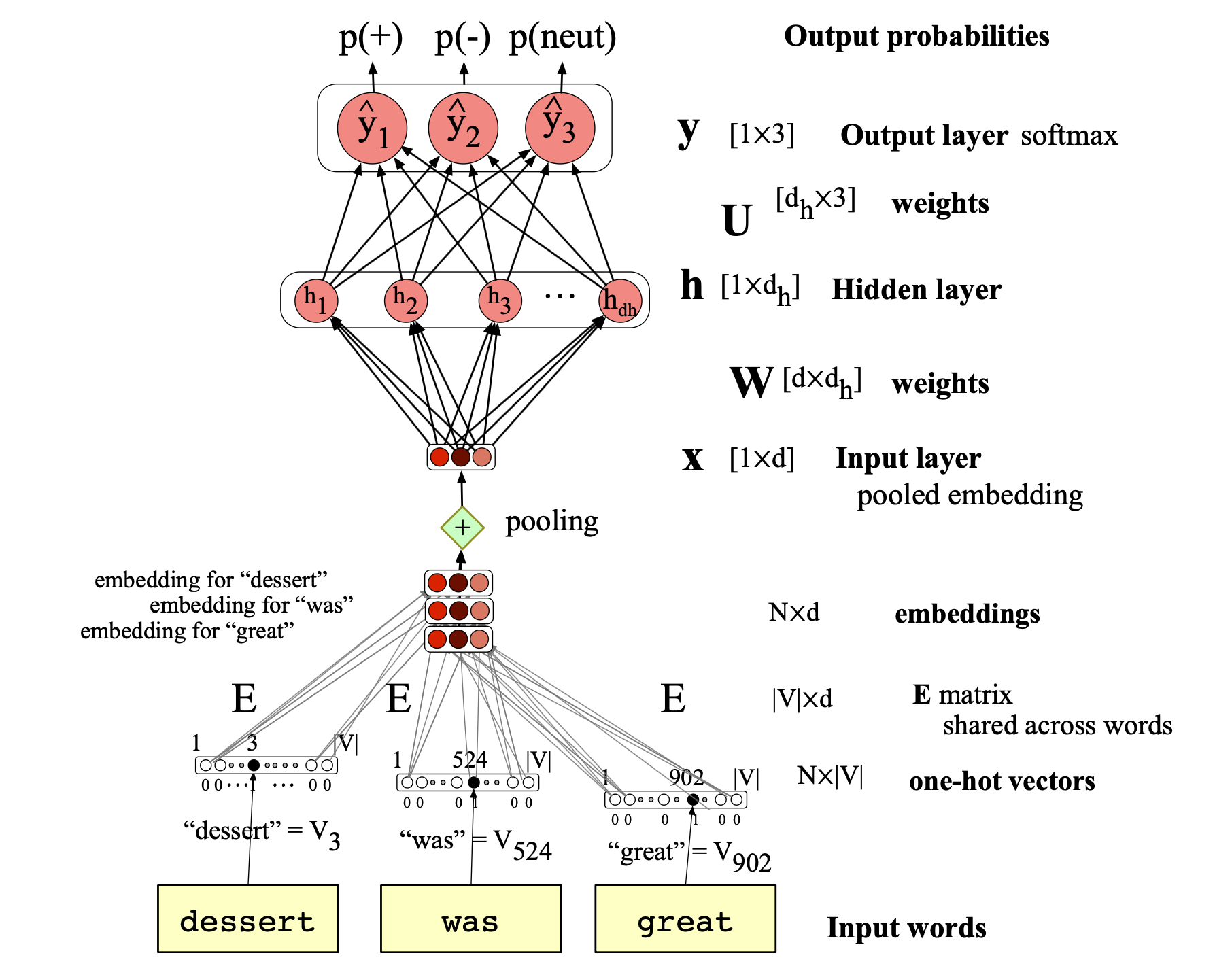
图 6.13 使用池化嵌入的前馈网络进行情感分析。 在每个时间步,网络通过将 one-hot 向量与嵌入矩阵 $\mathbf{E}$ 相乘,为上下文中的每个词计算一个 $d$ 维嵌入;随后对这 $N$ 个嵌入进行池化,得到一个代表整个上下文窗口的单一嵌入,即图中的 $\mathbf{e}$ 层。
除了均值池化,还有许多其他池化方式,例如最大池化(max-pooling):对每个维度,取所有输入向量在该维度上的最大值。 具体来说,给定 $N$ 个向量,其逐元素最大值是一个新向量,其第 $k$ 个元素等于这 $N$ 个向量在第 $k$ 维上的最大值。
用于语言建模的输入嵌入拼接
在情感分析任务中,我们看到:给定一个包含 $N$ 个输入词元的窗口,可以通过先将这些词元的嵌入池化为单个向量,再输出一个包含三个类别(正面、负面或中性)概率的预测向量。
现在我们考虑语言建模(language modeling)任务:根据前面的词预测接下来可能出现的词。
在此任务中,输入同样是 $N$ 个词元组成的窗口,但目标变为:预测紧随该窗口之后的下一个词元。
我们将简要介绍一种简单的前馈神经语言模型,其思想最早由 Bengio 等人(2003)提出。
这种前馈语言模型引入了许多关键概念,这些概念将在第 7 章和第 8 章关于大语言模型的讨论中再次出现。
与第 3 章介绍的 n-gram 语言模型相比,神经语言模型具有诸多优势。 神经语言模型能够利用更长的历史上下文;对语义相似的上下文具有更强的泛化能力;在词语预测上更加准确。 但另一方面,神经网络语言模型也存在缺点:训练速度慢、结构更复杂、训练能耗高,且可解释性不如 n-gram 模型。因此,在某些小型任务中,n-gram 模型仍然是更合适的选择。
前馈神经语言模型是一种前馈网络,它在时刻 $t$ 接收若干个先前词(如 $w_{t-1}, w_{t-2}$ 等)的表示作为输入,并输出一个覆盖所有可能后续词的概率分布。 因此,与 n-gram 语言模型类似,前馈神经语言模型也采用有限上下文假设:它用最近的 $N − 1$ 个词来近似完整历史,从而估计下一个词的条件概率 $P(w_t|w_{1:t-1})$
$$ P(w_t \mid w_1, \dots, w_{t-1}) \approx P(w_t \mid w_{t-N+1}, \dots, w_{t-1}) \tag{6.23} $$在以下示例中,我们以 4-gram 为例,即构建一个神经网络来估计概率:$P(w_t = i \mid w_{t-3}, w_{t-2}, w_{t-1})$。
神经语言模型使用词的嵌入表示(embeddings)来编码上下文中的词,而非像 n-gram 模型那样仅依赖词本身的身份标识。 这种做法使模型能更好地泛化到未见过的数据。 例如,假设训练集中出现过这句话:
I have to make sure that the cat gets fed.
但从未见过 “dog” 后接 “gets fed”。 现在测试集中有一句前缀:“I forgot to make sure that the dog gets”。 下一个词应该是什么? 若 n-gram 模型只在 “that the cat gets” 后见过 “fed”,则不会在 “that the dog gets” 后预测 “fed”。 但神经语言模型知道 “cat” 和 “dog” 的嵌入向量相近,模型能从 “cat” 的上下文泛化到 “dog”,从而仍为 “fed” 分配较高的概率。
这一预测任务要求输出一个长度为 $|V|$ 的概率向量——每个可能的后续词元对应一个概率值。 我们的词汇表大小可能包含 6 万到 30 万个词元,因此语言建模的输出向量远比情感分类的 3 维输出长得多。 此外,语言建模与情感分析还有一个关键区别:我们不再对 $N$ 个输入词元的嵌入进行池化,而是将它们拼接成一个很长的输入向量。 这是因为预测下一个词时,保留每个前序词及其顺序信息至关重要。
图 6.14 展示了语言建模任务,为便于排版,图中仅使用 $N = 3$ 的极短上下文窗口。 这三个嵌入向量被拼接后形成嵌入层 $\mathbf{e}$, 随后与权重矩阵 $\mathbf{W}$ 相乘得到隐藏层,再与另一权重矩阵 $\mathbf{U}$ 相乘得到输出层。对该输出层应用 softmax 函数,即可得到整个词汇表上的概率分布。 例如,输出节点 42 的值 $y_{42}$ 表示下一个词 $w_t$ 为词汇表中索引 42 的词(在本例中是单词 “fish”)的概率。
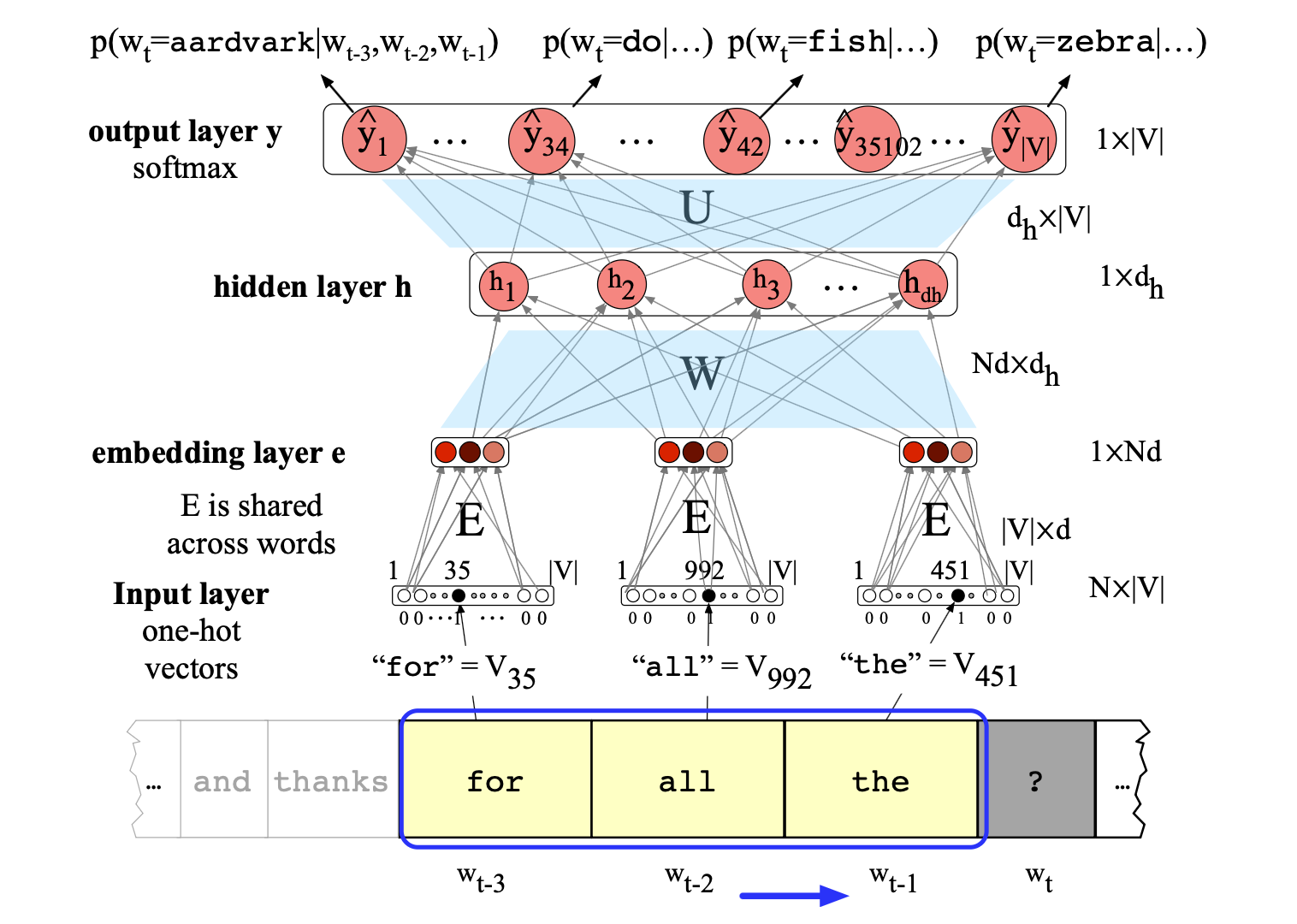
图 6.14 前馈神经语言模型中的前向推理过程。 在每个时刻 $t$,网络为 $N = 3$ 个上下文词元分别计算一个 $d$ 维嵌入(通过将 one-hot 向量与嵌入矩阵 $\mathbf{E}$ 相乘),然后将这三个嵌入拼接(concatenate)起来,得到嵌入层 $\mathbf{e}$。 该嵌入 $\mathbf{e}$ 与权重矩阵 $\mathbf{W}$ 相乘后,逐元素应用激活函数,生成隐藏层 $\mathbf{h}$;随后 $\mathbf{h}$ 再与另一个权重矩阵 $\mathbf{U}$ 相乘。 最后,通过 softmax 层,模型在每个输出节点 $i$ 上预测下一个词 $w_t$ 为词汇表中第 $i$ 个词 $V_i$ 的概率。 图中将上下文窗口大小 $N$ 设为 3 仅为排版清晰;实际上,语言建模通常需要长得多的上下文。
给定每个上下文词的 one-hot 输入向量,一个窗口大小为 3 的简单前馈神经语言模型的计算公式如下:
$$ \begin{align*} \mathbf{e} &= [\mathbf{E}\mathbf{x}_{t-3};\, \mathbf{E}\mathbf{x}_{t-2};\, \mathbf{E}\mathbf{x}_{t-1}] \\ \mathbf{h} &= \sigma(\mathbf{We} + \mathbf{b}) \\ \mathbf{z} &= \mathbf{Uh} \\ \hat{\mathbf{y}} &= \mathrm{softmax}(\mathbf{z}) \tag{6.24} \end{align*} $$注意:此处使用分号(;)表示向量拼接,即嵌入层 $\mathbf{e}$ 是由三个上下文词的嵌入向量拼接而成的长向量。
我们将在第 7 章和第 8 章再次回到使用神经网络进行语言建模这一主题,届时将介绍基于 Transformer 的语言模型。