现在我们来看如何将前馈网络应用于 NLP 分类任务。
实际上,简单的前馈网络并不是当前文本分类的主流方法;在真实应用中,我们会使用更先进的架构,例如第 10 章介绍的 BERT 等 Transformer 模型。
尽管如此,通过构建一个基于前馈网络的文本分类器,我们可以引入若干核心概念,这些概念贯穿全书,包括:嵌入矩阵(embedding matrix)、表示池化(representation pooling)和表示学习(representation learning)。
但在介绍这些概念之前,我们先从一个最简单的分类器开始——仅对第 4 章的情感分类器做最小改动。 与第 4 章一样,我们仍使用人工设计的特征,将其送入分类器,并输出类别概率。 唯一的区别是,我们将分类器从逻辑回归替换为神经网络。
6.4.1 使用人工特征的神经网络分类器
我们从一个简单的两层情感分类器入手:以第 4 章的逻辑回归分类器(对应单层网络)为基础,仅增加一个隐藏层。
输入元素 $\mathbf{x}_i$ 可以是图 4.2 中那样的标量特征,例如$\mathbf{x}_i$ = 文档中的总词数,$\mathbf{x}_2$ = 文档中积极情感词典词的出现次数,如果文档包含“no” 则 $\mathbf{x}_3$ = 1,依此类推,共 $d$ 个特征。 输出层 $\hat{y}$ 可以有两个节点(分别对应正面、负面情感),或三个节点(正面、负面、中性)。此时 $\hat{y}_1$ 表示正面情感的概率, $\hat{y}_2$ 表示负面情感的概率,$\hat{y}_3$ 表示中性情感的概率。 整个模型的计算公式与前述两层网络完全一致(如前所述,我们继续用 $\sigma$ 泛指任意非线性激活函数,无论是 Sigmoid、ReLU 还是其他):
$$ \begin{align*} \mathbf{x} &= [\mathbf{x}_i,\mathbf{x}_2,...\mathbf{x}_d ] (\text{each} \mathbf{x}_i \text{is a hand-designed feature}) \\ \mathbf{h} &= \sigma(\mathbf{Wx} + \mathbf{b}) \\ \mathbf{z} &= \mathbf{Uh} \\ \hat{\mathbf{y}} = \mathrm{softmax}(\mathbf{z}) \tag{6.19} \end{align*} $$图 6.10 展示了该架构的示意图。 如前所述,在逻辑回归分类器中加入这个隐藏层,使网络能够捕捉特征之间的非线性交互关系。 仅此一点就可能带来性能更好的情感分类器。
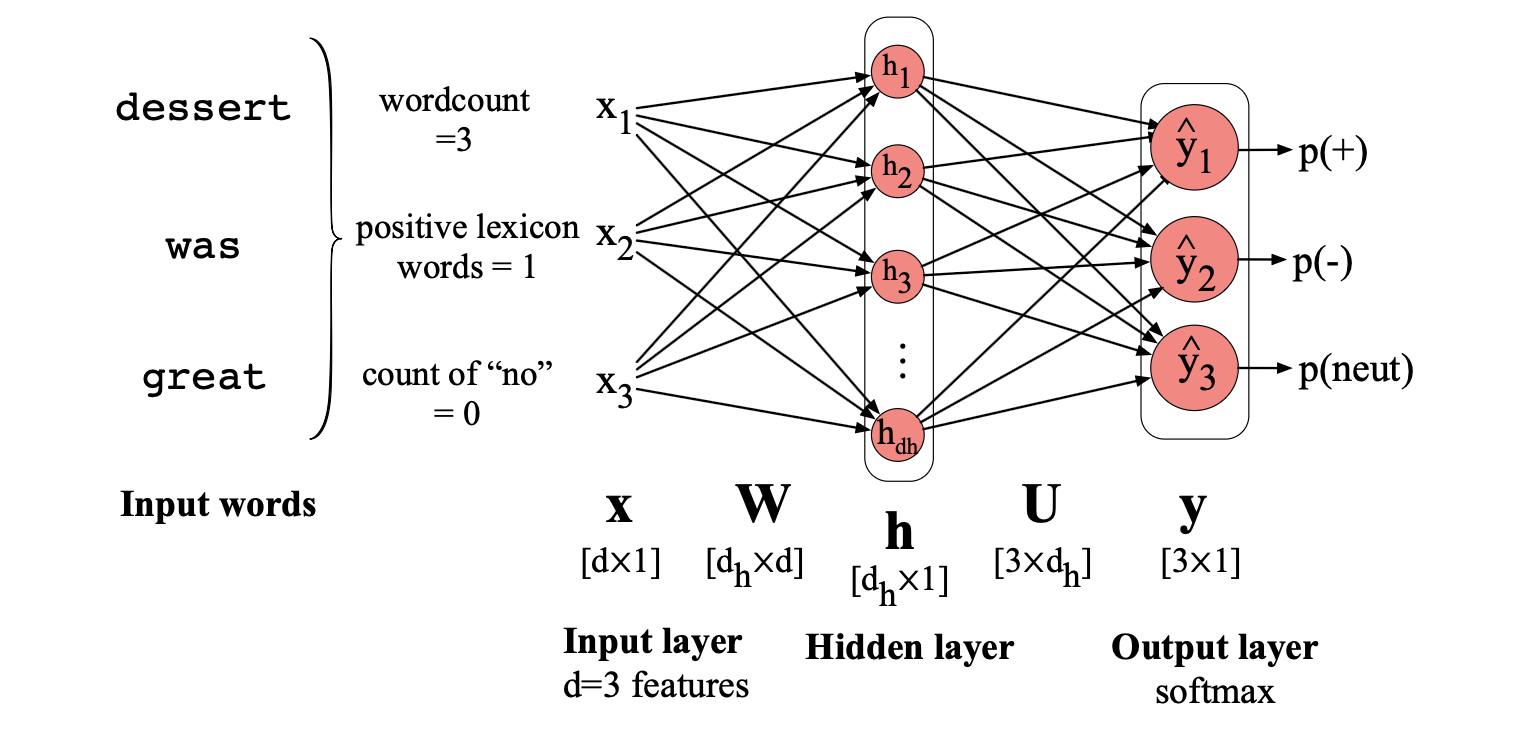
图 6.10 使用传统人工构建文本特征的前馈网络进行情感分析。
6.4.2 向量化以并行化推理
公式 6.19 描述的是对单个样本 $\mathbf{x}$ 的分类过程,在实际应用中,我们希望高效地对包含 $m$ 个样本的整个测试集进行分类。 为此,我们采用向量化(vectorizing)方法,这与逻辑回归中的做法完全一致:避免使用 for 循环逐个处理样本,而是通过矩阵运算一次性完成整个测试集的计算。 具体而言,我们将每一个输入 $x$ 的所有输入特征向量打包成一个输入矩阵 $\mathbf{X}$,其中第 $i$ 行是一个行向量,表示第 $i$ 个输入样本 $x^{(i)}$ 的特征(即 $\mathbf{x}^{(i)}$ 本身)。 若每个输入的特征维度为 $d$,则 $\mathbf{X}$ 的形状为 $[m \times d]$。
由于我们现在将每个输入表示为行向量(而非列向量),需对公式 (6.19) 稍作调整。 $\mathbf{X}$ 的形状为 $[m \times d]$,权重矩阵 $\mathbf{W}$ 的形状为 $[d_h \times d]$($d_h$ 为隐藏层维度),我们需要调整 $\mathbf{X}$ 和 $\mathbf{W}$ 乘法顺序,转置 $\mathbf{W}$,才能使矩阵乘法合法并得到形状为 $[m \times d_h]$ 的隐藏层输出矩阵 $\mathbf{H}$。1
此外,原偏置向量 $\mathbf{b}$ 的形状是 $[1 \times d_h]$),现在需被广播为形状 $[m \times d_h]$ 的矩阵。 同理,下一步计算中也需要对 $\mathbf{U}$ 转置。 最终,输出矩阵 $\hat{\mathbf{Y}}$ 的形状为 $[m \times 3]$(或更一般地 $[m \times d_o]$,其中 $d_o$ 为输出类别数),其第 $i$ 行即为第 $i$ 个样本的输出概率向量 $\hat{\mathbf{y}}^{(i)}$。 计算整个测试集输出类别分布的最终计算公式如下:
$$ \begin{align*} \mathbf{H} &= \sigma(\mathbf{XW}^T + \mathbf{b}) \\ \mathbf{Z} &= \mathbf{HU}^T \\ \hat{\mathbf{Y}} &= \mathrm{softmax}(\mathbf{Z}) \tag{6.20} \end{align*} $$在本书中,有时我们会看到矩阵乘法写成 $\mathbf{WX} + \mathbf{b}$,有时写成 $\mathbf{XW} + \mathbf{b}$。因此,在任何公式中,都要清楚权重矩阵的形状,这一点始终至关重要。
如果我们坚持将每个样本作为列向量存储(即 $\mathbf{X}$ 形状为 $[d \times m]$),则可保留原始乘法顺序 $\mathbf{W} \mathbf{X}$。但将样本作为行向量处理在神经网络中更为常见且方便。 ↩︎