现在,我们稍微正式一些介绍最简单的神经网络——前馈网络(feedforward network)。 前馈网络是一种多层网络,其单元之间的连接不含环路:每一层单元的输出仅传递给下一层的单元,不会反馈到前面更低的层。 (第 8 章将介绍包含环路的网络,即循环神经网络(recurrent neural networks)。)
出于历史原因,多层网络(尤其是前馈网络)有时被称为多层感知机(multi-layer perceptrons,简称 MLP)。 严格来说,这是一种误称,因为现代多层网络中的单元并非真正的感知机(感知机是纯线性的,而现代网络由带有非线性激活函数(如 Sigmoid)的单元构成)。但这一名称早已沿用成习。
简单的前馈网络包含三类节点:输入单元、隐藏单元和输出单元。
图 6.8 展示了这样一个网络。输入层 $\mathbf{x}$ 是一个标量值组成的向量,与图 6.2 中所示相同。
神经网络的核心是隐藏层 $\mathbf{h}$,它由若干隐藏单元 $h_i$ 构成。 每个隐藏单元都是第 6.1 节描述的神经单元:先对其输入进行加权求和,再应用一个非线性函数。 在标准架构中,各层之间是全连接(fully-connected)的,即每一层的每个单元都接收前一层所有单元的输出作为输入,相邻两层之间每一对单元都有连接。 因此,每个隐藏单元都会对所有输入单元的输出进行求和。
回想一下,单个隐藏单元的参数包括一个权重向量和一个偏置。 对于整个隐藏层,我们将每个单元 $i$ 的权重向量和偏置合并为一个权重矩阵 $\mathbf{W}$ 和一个偏置向量 $\mathbf{b}$(见图 6.8)。 权重矩阵 $\mathbf{W}$ 中的元素 $\mathbf{W}_{ji}$ 表示从第 $i$ 个输入单元 $x_i$ 到第 $j$ 个隐藏单元 $h_j$ 的连接权重。
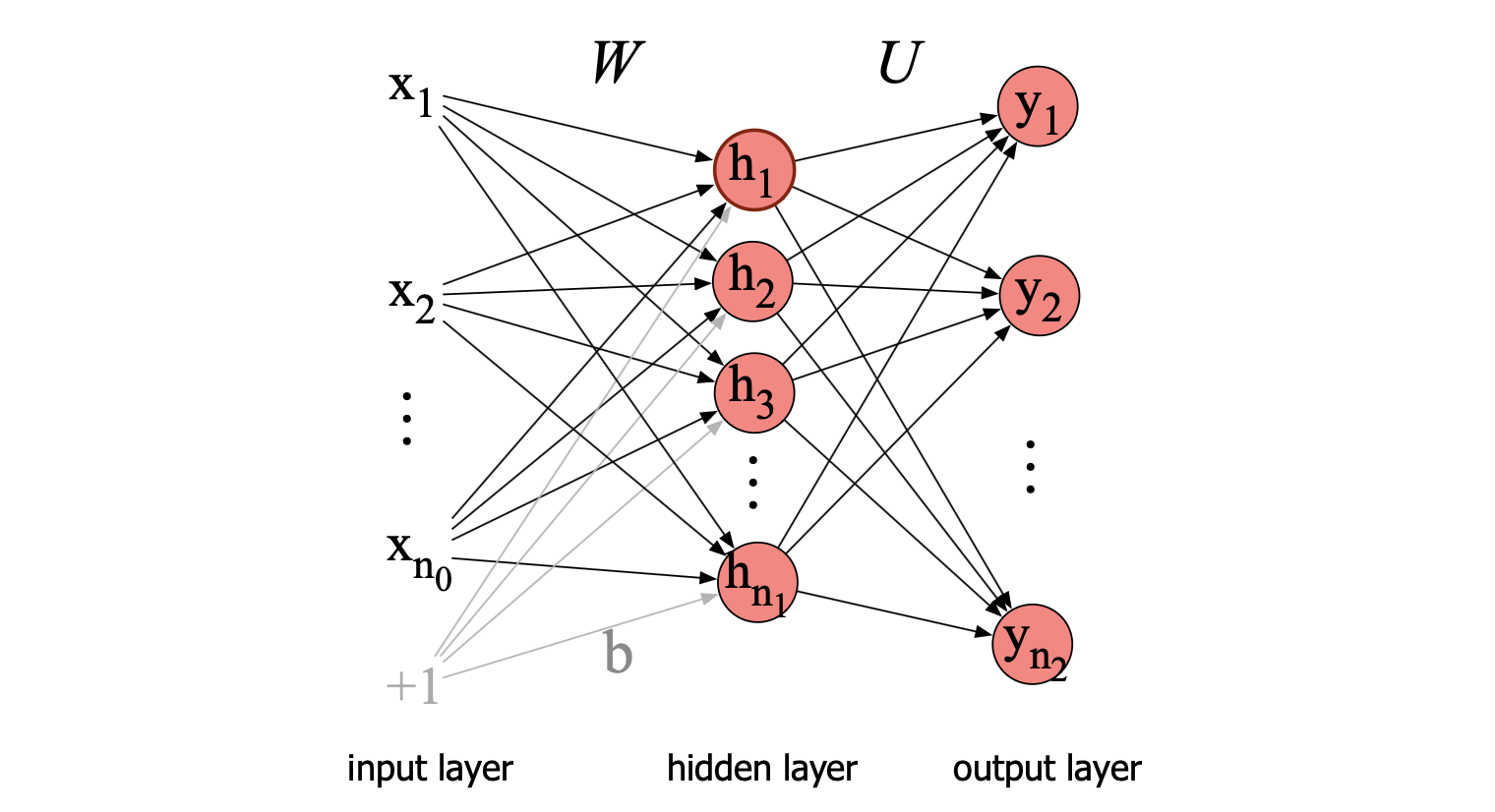
图 6.8 一个简单的两层前馈网络,包含一个输入层、一个隐藏层和一个输出层(通常在计数网络层数时,不将输入层计入)。
使用单个矩阵 $\mathbf{W}$ 表示整层权重的一大优势在于:前馈网络的隐藏层计算可通过简单的矩阵运算高效完成。 实际上,整个计算只需三步:将权重矩阵 $\mathbf{W}$ 与输入向量 $\mathbf{x}$ 相乘;加上偏置向量 $\mathbf{b}$;对结果应用激活函数 $g$(如前述的 Sigmoid、tanh 或 ReLU)。
因此,隐藏层的输出向量 $\mathbf{h}$ 可表示为(此处以 sigmoid 函数 $\sigma$ 为例):
$$ \mathbf{h} = \sigma(\mathbf{Wx} + \mathbf{b}) \tag{6.8} $$注意:此处 $\sigma$ 作用于一个向量,而公式 (6.3) 中它作用于标量。 我们约定:任何激活函数 $g(\cdot)$ 作用于向量时,均按逐元素(element-wise)方式应用,即 $g([z_1, z_2, z_3]) = [g(z_1), g(z_2), g(z_3)]$。
接下来引入一些符号来表示这些向量和矩阵的维度。 我们将输入层称为网络的第 0 层,用 $n_0$ 表示输入数量,因此输入向量 $\mathbf{x} \in \mathbb{R}^{n_0}$,即一个维度为 $[n_0, 1]$ 的列向量。 隐藏层为第 1 层,输出层为第 2 层。 隐藏层的维度为 $n_1$,故 $\mathbf{h} \in \mathbb{R}^{n_1}$,偏置向量 $\mathbf{b} \in \mathbb{R}^{n_1}$(每个隐藏单元可拥有不同的偏置值)。 权重矩阵 $\mathbf{W}$ 的维度为 $\mathbb{R}^{n_1 \times n_0}$,即形状为 $[n_1, n_0]$。
请花一点时间确认:公式 (6.8) 中的矩阵乘法确实能计算出每个 $\mathbf{h}_j$ 的值,即 $\sigma\left( \sum_{i=1}^{n_0} \mathbf{W}_{ji} x_i + \mathbf{b}_j \right)$。
正如第 6.2 节所示,所得向量 $\mathbf{h}$(“h” 既代表 hidden(隐藏),也暗含 hypothesis(假设)之意)构成了输入的一种表示(representation)。 输出层的作用,就是基于这一新表示 $\mathbf{h}$ 计算最终输出。 该输出可以是一个实数值,但在许多任务中,网络的目标是做出某种分类决策。因此,我们将重点关注分类任务。
如果我们执行的是二分类任务(例如情感分类),网络可能只有一个输出节点,其标量输出 $y$ 表示属于“正面情感”而非“负面情感”的概率。 如果执行的是多分类任务(例如词性标注),则可能为每个可能的词性标签设置一个输出节点,每个节点的输出值表示该词性的概率,且所有输出节点的值之和必须为 1。 因此,输出层是一个向量 $\mathbf{y}$,它给出了各输出类别上的概率分布。
我们来看这一过程是如何实现的。 与隐藏层类似,输出层也有一个权重矩阵(记为 $\mathbf{U}$)。不过,某些模型在输出层中不包含偏置向量 $\mathbf{b}$,因此本例中我们简化处理,省略输出层的偏置。 权重矩阵 $\mathbf{U}$ 与其输入向量(即 $\mathbf{h}$)相乘,得到中间输出 $\mathbf{z}$:
$$ \mathbf{z} = \mathbf{U h} $$设输出节点数量为 $n_2$,则 $\mathbf{z} \in \mathbb{R}^{n_2}$,权重矩阵 $\mathbf{U}$ 的维度为 $\mathbb{R}^{n_2 \times n_1}$,其中元素 $U_{ij}$ 表示从隐藏层第 $j$ 个单元到输出层第 $i$ 个单元的连接权重。
然而,$\mathbf{z}$ 不能直接作为分类器的输出,因为它是一个实数值向量,而分类任务需要的是一个概率向量。 为此,我们使用一个便捷的函数对实值向量进行归一化(normalize),转换为一个概率分布向量(各分量介于 0 到 1 之间,且总和为 1),即softmax 函数。该函数已在第 5 章第 85 页介绍过。 更一般地,对于任意维度为 $d$ 的向量 $\mathbf{z}$,softmax 定义如下:
$$ \mathrm{softmax}(\mathbf{z}_i) = \frac{\exp(\mathbf{z}_i)}{\sum_{j=1}^{d} \exp(\mathbf{z}_j)}, \quad 1 \leq i \leq d \tag{6.9} $$例如,给定向量
$$ \mathbf{z} = [0.6,\, 1.1,\, -1.5,\, 1.2,\, 3.2,\, -1.1], \tag{6.10} $$softmax 函数会将其归一化为一个概率分布(以下结果已四舍五入):
$$ \mathrm{softmax}(\mathbf{z}) = [0.055,\, 0.090,\, 0.0067,\, 0.10,\, 0.74,\, 0.010] \tag{6.11} $$你可能还记得,在第 4 章的多分类逻辑回归中,我们也曾用 softmax 将一组实数值(由权重与特征相乘后求和得到)转换为概率分布。
这意味着,我们可以将带一个隐藏层的神经网络分类器理解为:首先构建一个向量 $\mathbf{h}$,作为输入的隐藏层表示;然后在此表示上执行标准的多分类逻辑回归。 相比之下,第 5 章中的特征主要通过手工设计的特征模板构造。 因此,神经网络类似于多分类逻辑回归,但有三点关键区别: (a) 具备多层结构:深度神经网络可看作是一层层堆叠的逻辑回归分类器; (b) 中间层可使用多种激活函数:如 tanh、ReLU、Sigmoid,而不仅限于 Sigmoid(尽管为方便起见,我们仍用 $\sigma$ 泛指任意激活函数); (c) 特征表示由网络自身学习:不再依赖手工特征模板,而是由网络的前几层自动推导出特征表示。
以下是单隐藏层前馈网络的完整计算公式:该网络接收输入向量 $\mathbf{x}$,输出概率分布 $\mathbf{y}$,参数包括权重矩阵 $\mathbf{W}$、$\mathbf{U}$ 和偏置向量 $\mathbf{b}$:
以下是单隐藏层前馈网络的完整计算公式:输入向量为 $\mathbf{x}$;输出为概率分布 $\mathbf{y}$;参数包括权重矩阵 $\mathbf{W}$、$\mathbf{U}$ 和偏置向量 $\mathbf{b}$:
$$ \begin{align*} \mathbf{h} &= \sigma(\mathbf{Wx} + \mathbf{b}) \\ \mathbf{z} &= \mathbf{Uh} \\ \mathbf{y} &= \mathrm{softmax}(\mathbf{z}) \tag{6.12} \end{align*} $$最后,为便于记忆,各变量的维度如下:
- $\mathbf{x} \in \mathbb{R}^{n_0}$
- $\mathbf{h} \in \mathbb{R}^{n_1}$
- $\mathbf{b} \in \mathbb{R}^{n_1}$
- $\mathbf{W} \in \mathbb{R}^{n_1 \times n_0}$
- $\mathbf{U} \in \mathbb{R}^{n_2 \times n_1}$
- 输出向量 $\mathbf{y} \in \mathbb{R}^{n_2}$
我们称此网络为两层网络(传统上计数网络层数时不计入输入层,但计入输出层)。 依此术语,逻辑回归就是一种。
6.3.1 前馈网络的更多细节
现在我们引入一套更系统的记号,以便更清晰地描述深度超过 2 层的深层网络。 我们将使用方括号内的上标表示网络层数,从输入层开始计为第 0 层。 因此,$\mathbf{W}^{[1]}$ 表示第 1 个隐藏层的权重矩阵,$\mathbf{b}^{[1]}$ 表示第 1 个隐藏层的偏置向量。 用 $n_j$ 表示第 $j$ 层的单元数量。 我们用 $g(\cdot)$ 表示激活函数:对于中间层,通常采用 ReLU 或 tanh;对于输出层,则使用 softmax。 用 $\mathbf{a}^{[i]}$ 表示第 $i$ 层的输出,用 $\mathbf{z}^{[i]}$ 表示前一层输出、权重和偏置的线性组合:$\mathbf{z}^{[i]} = \mathbf{W}^{[i]} \mathbf{a}^{[i-1]} + \mathbf{b}^{[i]}$。 第 0 层对应输入,因此我们将输入向量 $\mathbf{x}$ 更一般地记为 $\mathbf{a}^{[0]}$。
于是,我们可以将公式 (6.12) 中的两层网络重新表示如下:
$$ \begin{align*} \mathbf{z}^{[1]} &= \mathbf{W}^{[1]} \mathbf{a}^{[0]} + \mathbf{b}^{[1]} \\ \mathbf{a}^{[1]} &= g^{[1]}(\mathbf{z}^{[1]}) \\ \mathbf{z}^{[2]} &= \mathbf{W}^{[2]} \mathbf{a}^{[1]} + \mathbf{b}^{[2]} \\ \mathbf{a}^{[2]} &= g^{[2]}(\mathbf{z}^{[2]}) \\ \hat{\mathbf{y}} &= \mathbf{a}^{[2]} \tag{6.13} \end{align*} $$注意,在这种记号下,每一层的计算形式完全一致。 因此,给定输入向量 $\mathbf{a}^{[0]}$,一个 $n$ 层前馈网络的前向传播算法可简洁地表述为:
$$ \begin{align*} &\textbf{for } i \text{ in } \ 1, \cdots,n \\ &\quad \quad \mathbf{z}^{[i]} = \mathbf{W}^{[i]} \mathbf{a}^{[i-1]} + \mathbf{b}^{[i]} \\ &\quad \quad \mathbf{a}^{[i]} = g^{[i]}(\mathbf{z}^{[i]}) \\ &\hat{\mathbf{y}} = \mathbf{a}^{[n]} \end{align*} $$在实际应用中,我们常常需要一个专门的名称来指代最终 softmax 之前的那一组未归一化输出值。 无论网络有多少层,我们都将最后一层的线性输出 $\mathbf{z}^{[n]}$ ——即 softmax 输入前的得分向量——称为 logits(参见第 4.7 节)。
非线性激活函数的必要性
我们在神经网络的每一层使用非线性激活函数的一个重要原因在于:如果不使用非线性函数,整个多层网络将完全等价于一个单层网络。 我们在神经网络的每一层使用非线性激活函数,其中一个关键原因是:如果没有非线性,多层网络将完全等价于单层网络。 下面我们说明为何如此。 设想一个仅由线性层组成的网络的前两层:
$$ \begin{align*} \mathbf{z}^{[1]} &= \mathbf{W}^{[1]}\mathbf{x} + \mathbf{b}^{[1]} \\ \mathbf{z}^{[2]} &= \mathbf{W}^{[2]}\mathbf{z}^{[1]} + \mathbf{b}^{[2]} \end{align*} $$我们可以将整个网络所计算的函数重写为:
$$ \begin{align*} \mathbf{z}^{[2]} &= \mathbf{W}^{[2]}(\mathbf{W}^{[1]}\mathbf{x} + \mathbf{b}^{[1]}) + \mathbf{b}^{[2]} \\ &= \mathbf{W}^{[2]}\mathbf{W}^{[1]}\mathbf{x} + \mathbf{W}^{[2]}\mathbf{b}^{[1]} + \mathbf{b}^{[2]} \\ &= \mathbf{W}'\mathbf{x} + \mathbf{b}' \tag{6.14} \end{align*} $$这一结论可推广至任意层数。 因此,若没有非线性激活函数,多层网络只不过是单层网络的一种记号变体——它只是用一组不同的权重和偏置实现了相同的线性变换,从而完全丧失了多层结构所带来的表达能力。
偏置单元的替代表示
在描述神经网络时,我们常采用一种稍简化的记号:不显式引入偏置项 $\mathbf{b}$。 而是在每层添加一个虚拟节点(dummy node)$a_0$,其值一个恒为 1。 例如,输入层(第 0 层)包含一个虚拟节点 $a^{[0]}_0 = 1$,第 1 层包含 $a^{[1]}_0 = 1$,以此类推。 这个虚拟节点仍然连接权重,而该权重就等价于原来的偏置值 $b$。 例如,原本我们写作:
$$ \mathbf{h} = \sigma(\mathbf{Wx} + \mathbf{b}) \tag{6.15} $$现在改写为:
$$ \mathbf{h} = \sigma(\mathbf{Wx}) \tag{6.16} $$但此时输入向量 $\mathbf{x}$ 不再只有 $n_0$ 个元素 $(\mathbf{x}_1, \dots, \mathbf{x}_{n_0})$,而是扩展为 $n_0 + 1$ 个元素,新增第 0 位为常数 1:$\mathbf{x} = [x_0, x_1, \dots, x_{n_0}], \quad \text{其中 } x_0 = 1$。 相应地,每个隐藏单元 $h_j$ 的计算从:
$$ h_j = \sigma\left( \sum_{i=1}^{n_0} \mathbf{W}_{ji} x_i + b_j \right), \tag{6.17} $$变为:
$$ h_j = \sigma\left( \sum_{i=0}^{n_0} \mathbf{W}_{ji} x_i \right), \tag{6.18} $$其中权重 $\mathbf{W}_{j0}$ 现在就扮演了原来偏置 $b_j$ 的角色。 图 6.9 展示了这种转换。
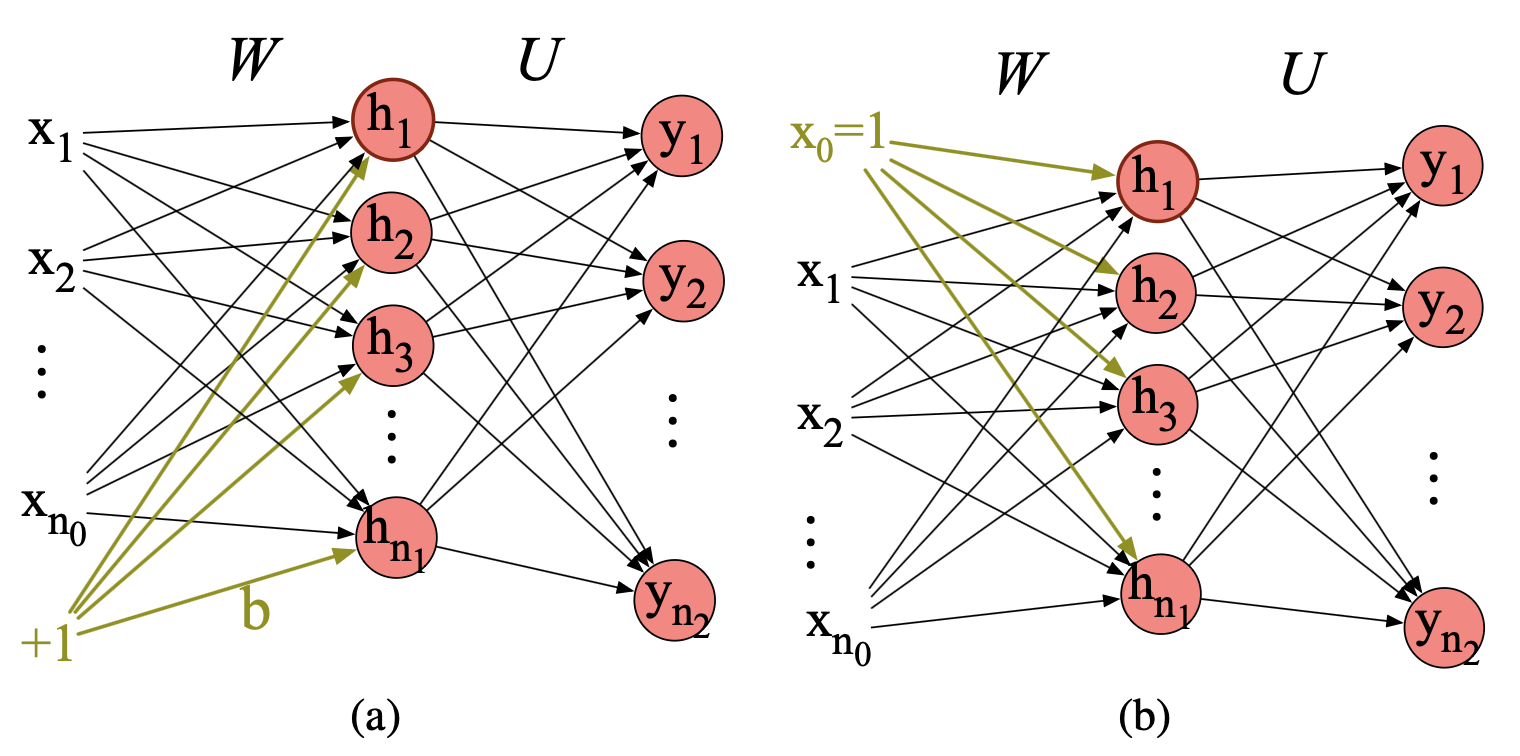
图 6.9 偏置节点的两种表示方式:(a) 显式偏置节点;(b) 用 $x_0 = 1$ 替代。
在第 6.6 节介绍学习算法时,我们仍会暂时保留显式的偏置项 $\mathbf{b}$ 以便清晰说明。但从本书后续内容开始,我们将统一采用这种不含显式偏置项的简化记号。 在第 6.6 节介绍学习算法时,我们仍会保留偏置符号 $b$ ;但从本书后续内容开始,大部分图表和公式中,我们将采用这种不含显式偏置项的简化记号。