在神经网络发展早期,人们就意识到:神经网络的强大能力——正如启发它的生物神经元一样——来自于将多个单元组合成更大的网络。
对多层网络必要性的一个经典证明,来自明斯基(Minsky)和帕佩特(Papert)于1969年提出的结果:单个神经单元无法计算某些非常简单的输入函数。 考虑用两个二值输入计算基本逻辑函数的任务,例如 AND、OR 和 XOR。 作为回顾,下表列出了这些函数的真值表:
| x1 | x2 | AND | OR | XOR |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 0 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
这个例子最初是针对感知机(perceptron)提出的。感知机是一种非常简单的神经单元,其输出为二值(0 或 1),并且不包含非线性激活函数。 感知机的输出 $y$ 按如下方式计算(使用与公式 (6.2) 相同的权重 $\mathbf{w}$、输入 $\mathbf{x}$ 和偏置 $b$):
$$ y = \begin{cases} 0, & \text{若 } \mathbf{w} \cdot \mathbf{x} + b \leq 0 \\ 1, & \text{若 } \mathbf{w} \cdot \mathbf{x} + b > 0 \end{cases} \tag{6.7} $$构建一个能计算 AND 或 OR 逻辑函数的感知机非常容易;图 6.4 展示了所需的权重。
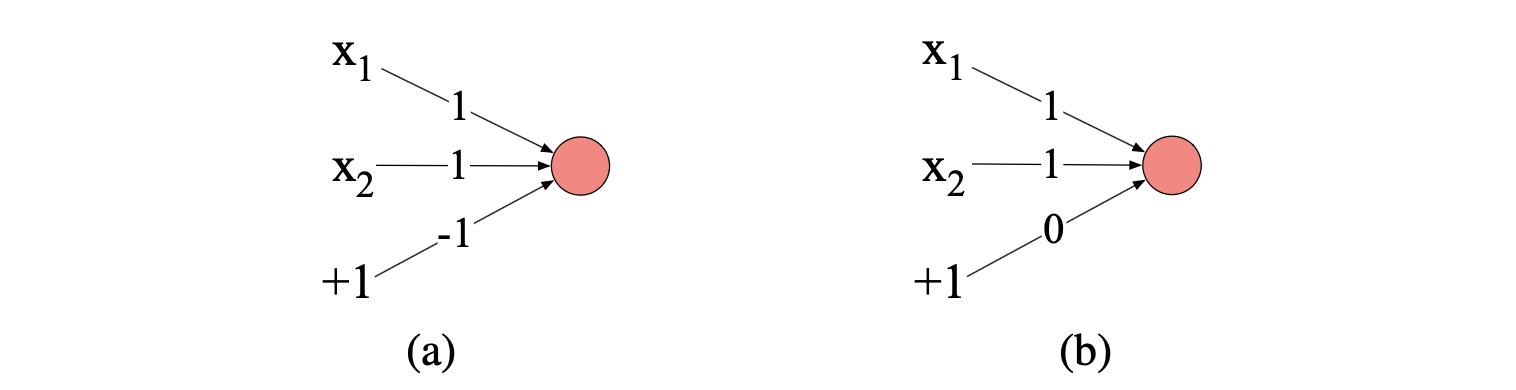
图 6.4 用于计算逻辑函数的感知机权重 $w$ 与偏置 $b$。 输入表示为 $x_1$ 和 $x_2$,偏置则表示为一个恒为 +1 的特殊节点,其与偏置权重 $b$ 相乘。 (a)逻辑 AND:权重 $w_1 = 1$、$w_2 = 1$,偏置权重 $b = -1$。 (b)逻辑 OR:权重 $w_1 = 1$、$w_2 = 1$,偏置权重 $b = 0$。 实现该函数的权重和偏置有无穷多组,图中所示只是其中一组。
然而,事实证明:无法构建一个感知机能计算逻辑 XOR 函数!(不妨花点时间亲自尝试一下!)
这一重要结论背后的根本原理是,感知机是一种线性分类器。 对于二维输入 $x_1$ 和 $x_2$,感知机的决策方程 $w_1 x_1 + w_2 x_2 + b = 0$ 表示一条直线。 (我们可将其改写为标准线性形式:$x_2 = (-w_1 / w_2) x_1 + (-b / w_2)$,从而看出这一点。) 这条直线在二维空间中构成一个决策边界(decision boundary):位于直线一侧的所有输入被分类为 0,另一侧则被分类为 1。 若输入维度超过 2,该边界就变为一个超平面(hyperplane),但基本思想不变——将空间划分为两类。
图 6.5 展示了所有可能的逻辑输入(00、01、10、11),以及 AND 和 OR 分类器某组参数所对应的决策直线。
注意:不存在任何一条直线能够将 XOR 的正例(01 和 10)与负例(00 和 11)正确分开。
我们称 XOR 不是一个线性可分(linearly separable)的函数。
当然,我们可以用曲线或其他非线性边界来划分,但无法用单一直线实现。
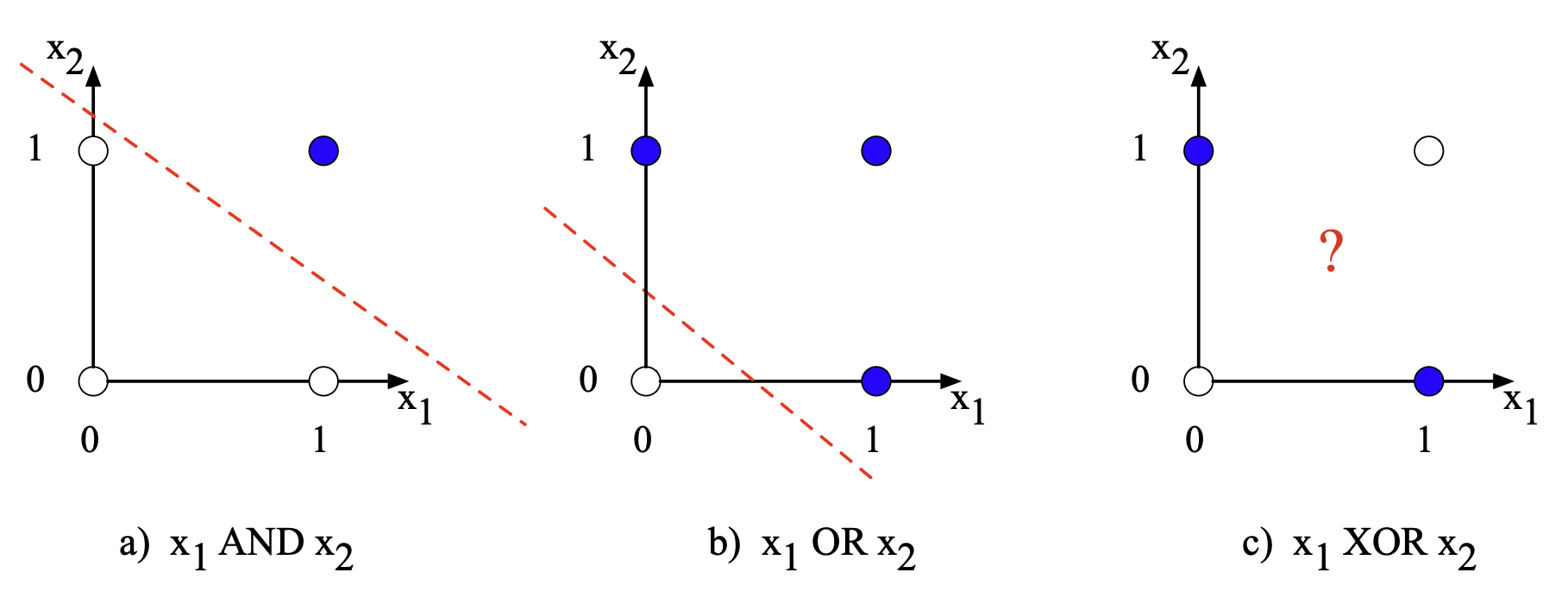
图 6.5 AND、OR 与 XOR 函数,横轴为输入 $x_1$,纵轴为输入 $x_2$。 实心圆点代表感知机输出为 1,空心圆点代表输出为 0。 XOR 无法用任何直线正确分离两类样本。 本图风格参考 Russell 与 Norvig(2002)。
6.2.1 解决方案:神经网络
虽然 XOR 函数无法由单个感知机计算,但可以通过多层感知机单元组成的网络来实现。 不过,我们不使用简单的感知机构建网络,而是参考 Goodfellow 等人(2016)的方法,展示如何用两层基于 ReLU 的单元计算 XOR。 图 6.6 展示了一个由两层神经单元处理输入的结构。 中间层(称为 $h$)包含两个单元,输出层(称为 $y$)包含一个单元。 图中给出了一组权重和偏置,使该网络能够正确计算 XOR 函数。
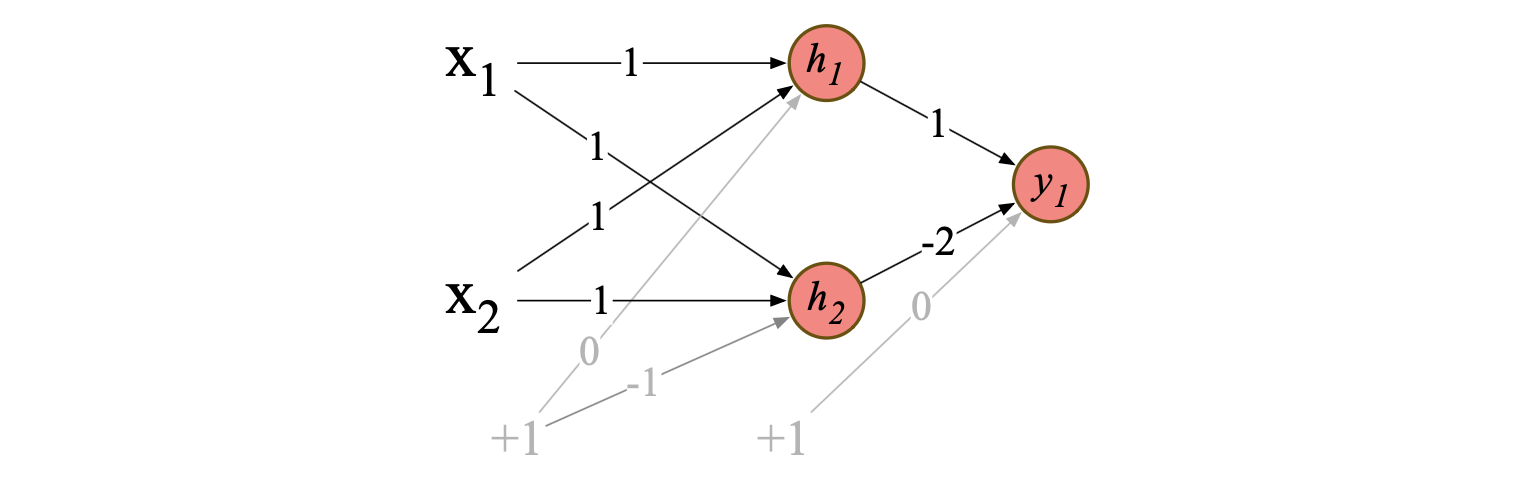
图 6.6 基于 Goodfellow 等人(2016)的 XOR 解决方案。 网络包含三个 ReLU 单元,分属两层;我们将其命名为 $h_1$、$h_2$(“h” 表示隐藏层)和 $y_1$。 箭头上的数字表示各单元的权重 $w$,偏置 $b$ 则表示为连接到一个恒为 +1 的输入节点的权重(图中以灰色显示偏置权重及对应的输入节点)。
我们逐步看一下输入 $\mathbf{x} = [0, 0]$ 时的计算过程。 首先,将每个输入值乘以对应的权重,求和后加上偏置 $b$,得到中间向量 $[0, -1]$。 接着,对这个向量应用修正线性(ReLU)变换,得到隐藏层 $h$ 的输出为 $[0, 0]$。 然后,再次将该结果与下一层的权重相乘、求和,并加上偏置(此处为 0),最终输出值为 0。 读者可自行验证其余三组输入:输入 $[0, 1]$ 和 $[1, 0]$ 时,输出 $y = 1$;输入 $[0, 0]$ 和 $[1, 1]$ 时,输出 $y = 0$。
观察中间结果——即两个隐藏节点 $h_1$ 和 $h_2$ 的输出——也很有启发性。
前文已说明,当输入 $\mathbf{x} = [0, 0]$ 时,隐藏层输出向量为 [0, 0]。
图 6.7b 展示了全部四组输入对应的隐藏层输出 $\mathbf{h}$。
注意:XOR 输出为 1 的两个输入点 $\mathbf{x} = [0, 1]$ 和 $\mathbf{x} = [1, 0]$,在隐藏层中被映射到了同一个点 $\mathbf{h} = [1, 0]$。
这种“合并”使得 XOR 的正例和负例变得线性可分。
换句话说,我们可以将隐藏层视为对输入的一种新表示(representation)。
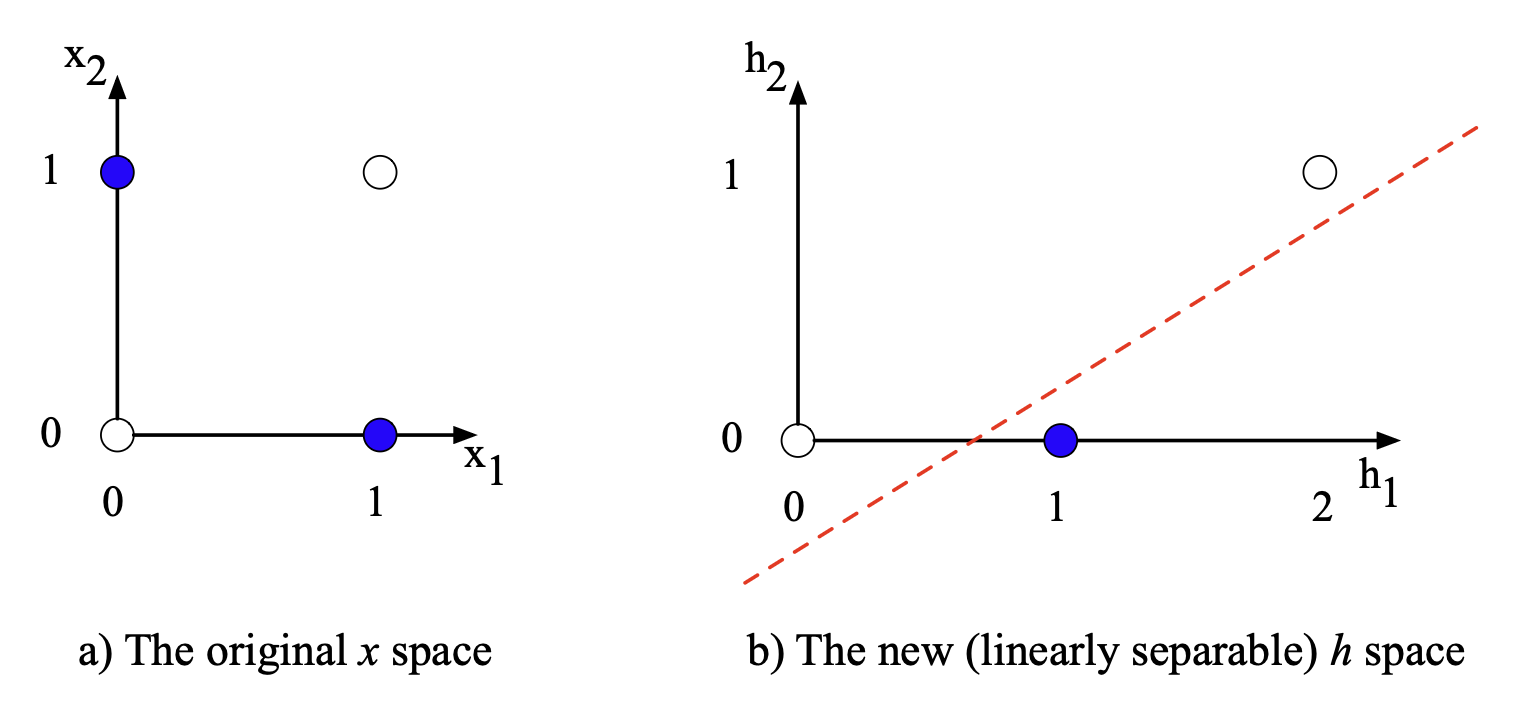
图 6.7 隐藏层为输入构建了新表示。 (a)为原始输入表示 $\mathbf{x}$,(b)为隐藏层表示 $\mathbf{h}$。 注意,输入点 $[0, 1]$ 与 $[1, 0]$ 在隐藏空间中被压缩到同一点,从而使 XOR 的正负样本可被一条直线分开。 改编自 Goodfellow 等人(2016)。
在本例中,我们直接指定了图 7.6 中的权重值。 但在实际应用中,神经网络的权重是通过误差反向传播算法(error backpropagation algorithm)自动学习得到的,该算法将在第 7.5 节详细介绍。 这意味着隐藏层能够自动学习到对任务有用的输入表示。 这种能力——即神经网络可以自动学习有效的输入表示——正是其核心优势之一,也是我们在后续章节中将反复强调的关键思想。
在本例中,我们直接给出了图 6.6 中的权重。 但在实际应用中,神经网络的权重是通过误差反向传播算法(error backpropagation algorithm)自动学习得到的,该算法将在第 6.6 节介绍。 这意味着隐藏层会自动学习到有用的输入表示。 神经网络能够自动学习有用的输入表示,正是其核心优势之一,也是我们在后续章节中将反复强调的关键思想。