神经网络的基本构建单元是一个单一的计算单元。 该单元接收一组实数值作为输入,对这些输入进行某种计算,并产生一个输出。
本质上,一个神经单元对其输入进行加权求和,并在求和结果中加入一个额外的项,称为偏置项(bias term)。 给定一组输入 $x_1, \dots, x_n$,该单元对应有一组权重 $w_1, \dots, w_n$ 和一个偏置 $b$,因此加权和 $z$ 可表示为:
$$ z = b + \sum_i w_i x_i \tag{6.1} $$通常,用向量记号来表达这个加权和更为方便.回忆线性代数中的定义,向量本质上就是一个数字列表或数组。 因此,我们我们可以用权重向量 $w$、标量偏置 $b$ 和输入向量 $x$ 来表示 $z$,并将求和运算替换为简洁的点积(dot product):
$$ z = \mathbf{w} \cdot \mathbf{x} + b \tag{6.2} $$如公式 (6.2) 所定义,$z$ 仅是一个实数值。
然而,神经单元并不会直接将 $z$(即 $x$ 的线性函数)作为输出,而是对 $z$ 应用一个非线性函数 $f$。 我们将该函数的输出称为该单元的激活值(activation),记作 $a$。 由于我们目前只建模单个单元,该节点的激活值实际上就是整个网络的最终输出,通常将其记为 $y$。 因此,$y$ 定义如下:
$$ y = a = f(z) $$下面将介绍三种常用的非线性函数:Sigmoid 函数、tanh 函数和修正线性单元(ReLU)。出于教学目的,我们先从 Sigmoid 函数 开始,因为它已在第 4 章中出现过:
$$ y = \sigma(z) = \frac{1}{1 + e^{-z}} \tag{6.3} $$Sigmoid 函数(见图 6.1)具有若干优点:它将输出映射到区间 (0,1) 内,有助于将异常值压缩至接近 0 或 1; 同时它是可微的,正如第 4.15 节所述,这一点对学习过程非常关键。
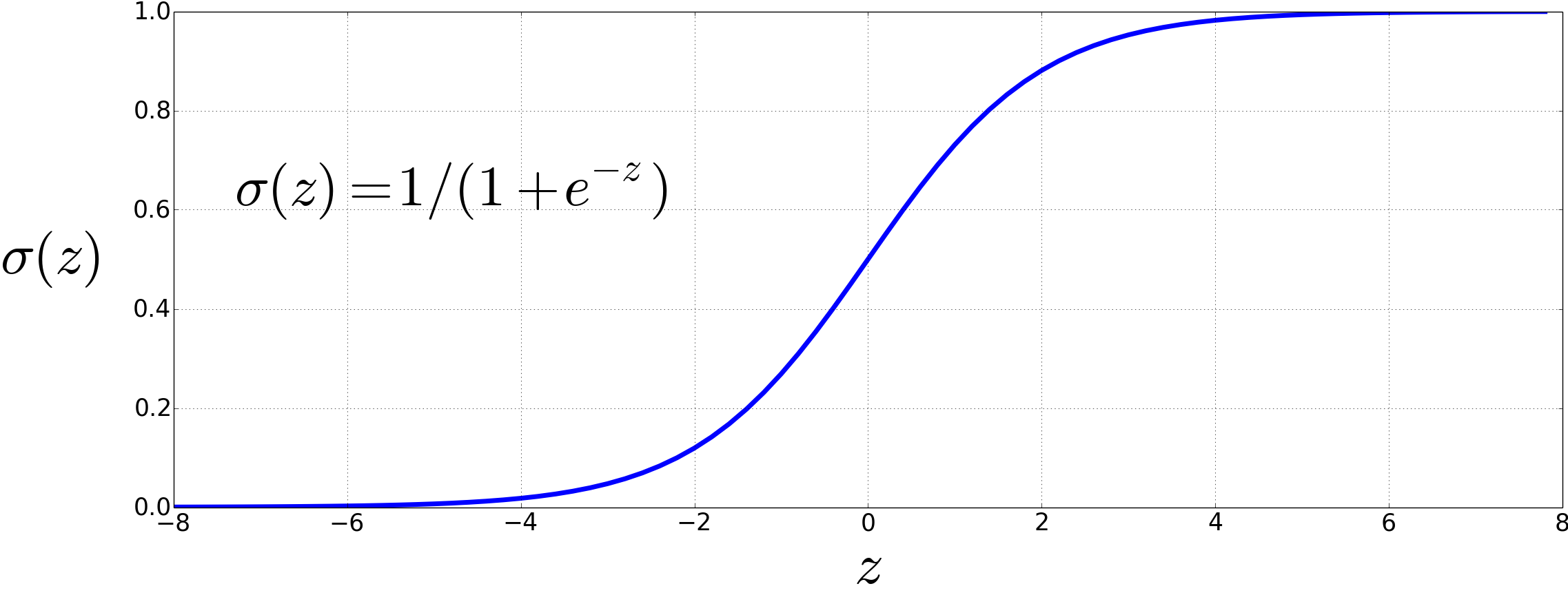
图 6.1 Sigmoid 函数将一个实数值映射到 (0,1) 区间。它在 0 附近近似线性,而远离 0 的值则被压缩趋近于 0 或 1。
将公式 (6.2) 代入公式 (6.3),即可得到一个神经单元的完整输出表达式:
$$ \begin{align*} y &= \sigma(\mathbf{w} \cdot \mathbf{x} + b) \\ &= \frac{1}{1 + \exp\big(-(\mathbf{w} \cdot \mathbf{x} + b)\big)} \tag{6.4} \end{align*} $$图 6.2 展示了一个基本神经单元的最终示意图。 在该示例中,该单元接收三个输入值 $x_1$、$x_2$ 和 $x_3$,对每个输入分别乘以对应的权重 $w_1$、$w_2$、$w_3$,计算加权和,再加上一个偏置项 $b$,然后将所得结果送入 Sigmoid 函数,最终输出一个介于 0 到 1 之间的数值。
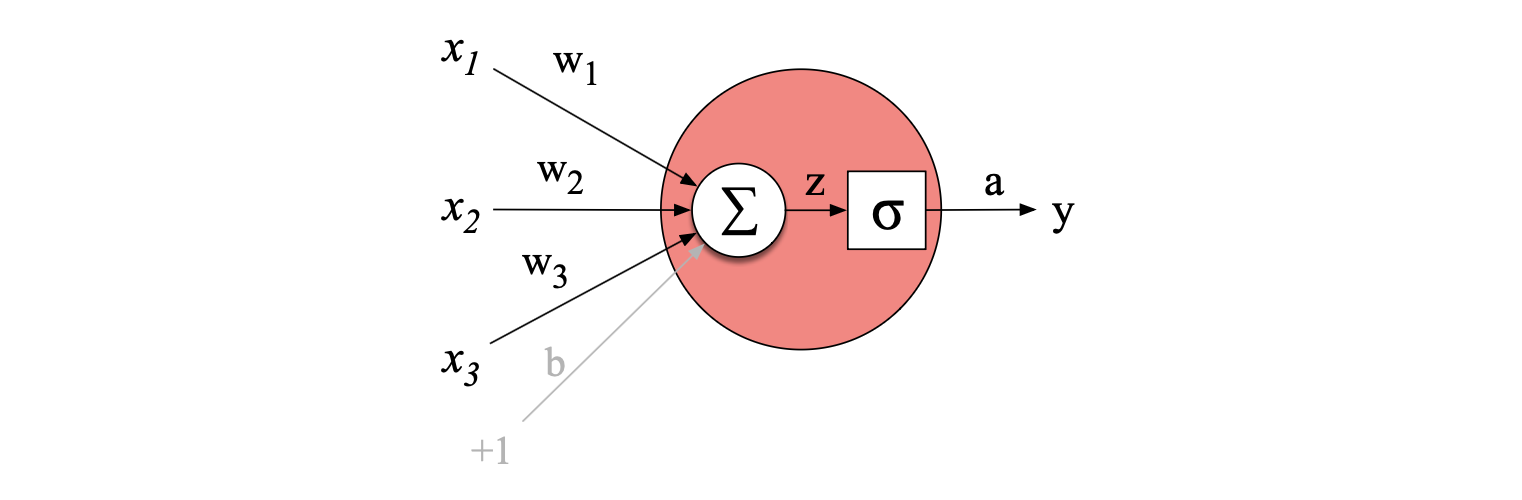
图 6.2 一个神经单元,接收三个输入 $x_1$、$x_2$ 和 $x_3$(以及一个偏置 $b$,我们将其表示为对应于一个恒为 +1 的输入的权重),并产生输出 $y$。 图中还标出了一些便于理解的中间变量:求和结果 $z$ 和 Sigmoid 函数的输出 $a$。 在此例中,单元的输出 $y$ 等于 $a$;但在更深的网络中,我们会保留 $y$ 表示整个网络的最终输出,而用 $a$ 表示单个节点的激活值。
我们通过一个具体例子来建立直观理解。 假设某单元的权重向量和偏置如下:
$$ \begin{align*} \mathbf{w} &= [0.2,\, 0.3,\, 0.9] \\ b &= 0.5 \end{align*} $$向该单元输入以下向量:
$$ \mathbf{x} = [0.5,\, 0.6,\, 0.1] $$输出 $y$ 为:
$$ \begin{align*} y &= \sigma(\mathbf{w} \cdot \mathbf{x} + b) \\ &= \frac{1}{1 + e^{-(\mathbf{w} \cdot \mathbf{x} + b)}} \\ &= \frac{1}{1 + e^{-(0.5 \times 0.2 + 0.6 \times 0.3 + 0.1 \times 0.9 + 0.5)}} \\ &= \frac{1}{1 + e^{-0.87}} \\ &\approx 0.70 \end{align*} $$在实际应用中,sigmoid 函数如今已较少被用作激活函数。 一种与之非常相似但几乎总是表现更优的函数是 tanh(双曲正切)函数,如图 7.3a 所示;tanh 是 sigmoid 的一种变体,其输出范围为 $[-1, +1]$: 在实际应用中,Sigmoid 函数已较少被用作激活函数。 一种与之非常相似但几乎总是表现更优的函数是 tanh(双曲正切)函数,如图 6.3a 所示。 tanh 是 Sigmoid 的一种变体,其输出范围为 -1 到 +1:
$$ y = \tanh(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}} \tag{6.5} $$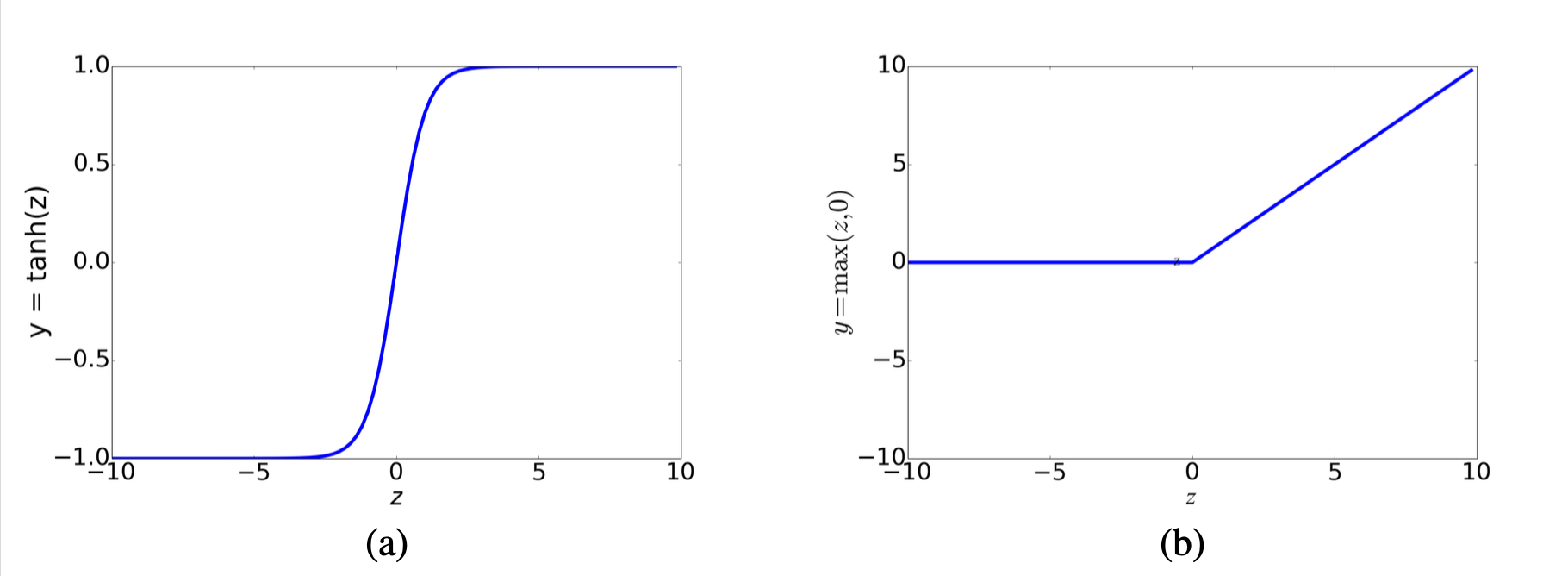
图 6.3 tanh 与 ReLU 激活函数。
最简单、或许也是目前最常用的激活函数是修正线性单元(Rectified Linear Unit),简称 ReLU,如图 6.3b 所示。 它的定义非常直接:当 $z$ 为正时,输出等于 $z$;否则输出为 0:
$$ y = \mathrm{ReLU}(z) = \max(z, 0) \tag{6.6} $$这些激活函数具有不同的特性,适用于不同的语言处理任务或网络架构。 例如,tanh 函数光滑可微,并能将异常值压缩至均值附近。 而 ReLU 的优势则源于其高度接近线性的特性。 在 Sigmoid 或 tanh 函数中,当 $z$ 的值很大时,输出 $y$ 会进入饱和区(saturated),即极其接近 1(或 -1),其导数也趋近于 0。 导数为零会给学习带来问题。正如第 6.6 节将要介绍的,我们通过反向传播误差信号来训练网络,过程中需要逐层相乘各层的梯度(偏导数)。如果梯度接近 0,误差信号就会逐层衰减,直至小到无法用于训练——这一现象称为梯度消失问题(vanishing gradient problem)。 ReLU 则没有这个问题。因为当 $z$ 较大时,ReLU 的导数为 1,而非接近 0。