本节简要总结一些已被研究的词嵌入语义特性。
不同类型的相似性或关联性
向量语义模型的一个重要参数是用于统计共现的上下文窗口大小。 这一参数对稀疏的 tf-idf 向量和稠密的 word2vec 向量都适用。 通常,窗口设为目标词左右各 1 到 10 个词(总上下文长度为 2–20 个词)。
具体选择取决于表示的目标。 较短的上下文窗口倾向于生成更偏向句法(syntactic)的表示,因为信息来自紧邻的词语。 在这种设置下,与目标词 $w$ 余弦相似度最高的词,通常是语义(semantic)相近且词性(part of speech)相同的词。 而当使用长上下文窗口计算向量时,与目标词 $w$ 余弦相似度最高的词,往往是主题相关但语义不相似的词。
例如,Levy 和 Goldberg(2014a)发现,使用 skip-gram 模型,当窗口为 ±2 时,与 Hogwarts (出自《哈利·波特》系列)最相似的词是其他虚构学校的名称,如 Sunnydale(出自《吸血鬼猎人巴菲》)或 Evernight(出自某吸血鬼系列)。 而当窗口扩大到 ±5 时,与 Hogwarts 最相似的词变成了《哈利·波特》系列中的主题相关词,如 Dumbledore、Malfoy 和 half-blood。
此外,通常还需区分两种词间相似性或关联性(Schütze & Pedersen, 1993): 一阶共现(first-order co-occurrence),有时称为组合关联(syntagmatic association),指两个词经常彼此邻近出现。 例如,wrote 是 book 或 poem 的一阶关联词。 二阶共现(second-order co-occurrence),有时称为聚合关联(paradigmatic association),指两个词具有相似的上下文邻居。 例如,wrote 与 said、remarked 等词构成二阶关联。
类比与关系相似性
词嵌入的另一重要语义特性,是其捕捉关系含义(relational meanings)的能力。 早在认知科学的早期研究中,Rumelhart 和 Abrahamson(1973)就提出了一种基于向量空间的平行四边形模型(parallelogram model),用于解决形如 $\textit{a is to b as } a^\ast \textit{ is to what?}$ 的简单类比问题。 例如,给定问题:apple:tree::grape:?,即 “apple 之于 tree,正如 grape 之于 ___”,系统应填入 vine(藤蔓)。 在该模型中(见图 5.8),计算从 apple 到 tree 的向量偏移:$\overrightarrow{tree} - \overrightarrow{apple}$;将此偏移加到 grape 的向量上:$\overrightarrow{grape} + (\overrightarrow{tree} - \overrightarrow{apple})$;找出距离该结果点最近的词,即为答案。
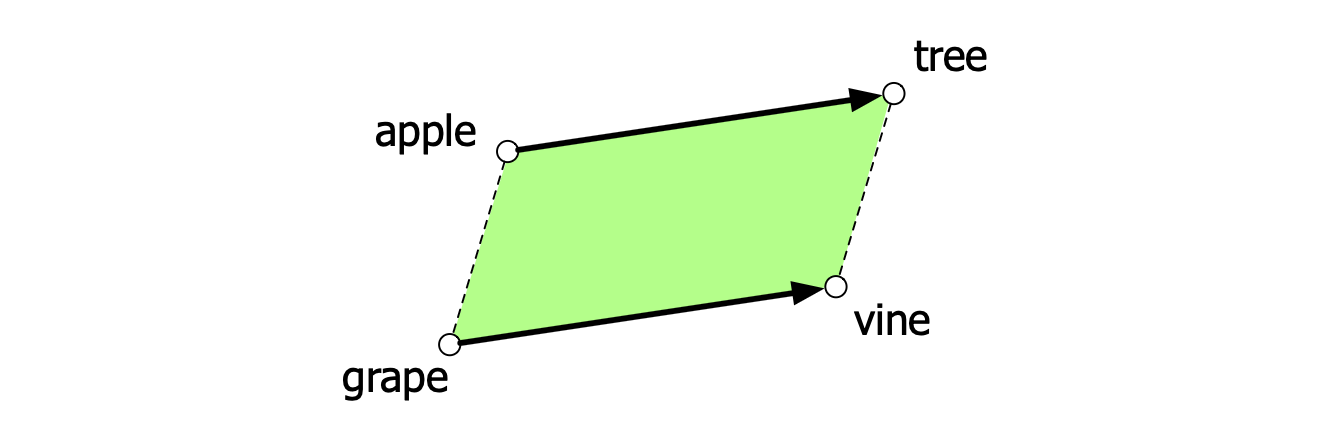
图 5.8:类比问题的平行四边形模型(Rumelhart & Abrahamson, 1973):通过 $\overrightarrow{tree} - \overrightarrow{apple} + \overrightarrow{grape}$ 可定位 $\overrightarrow{vine}$。
早期基于稀疏嵌入的研究已表明,稀疏向量模型能解决此类类比问题(Turney & Littman, 2005)。 但这一方法在现代受到更多关注,是因为它在 word2vec 或 GloVe 等稠密向量上取得了显著成功(Mikolov et al., 2013c;Levy & Goldberg, 2014b;Pennington et al., 2014)。 例如,表达式 $\overrightarrow{king} - \overrightarrow{man} + \overrightarrow{woman}$ 的结果向量接近 $\overrightarrow{queen}$。 同样,$\overrightarrow{Paris} - \overrightarrow{France} + \overrightarrow{Italy}$ 的结果向量接近 $\overrightarrow{Rome}$。 这表明嵌入模型似乎能提取出诸如 MALE–FEMALE(性别)、CAPITAL–CITY-OF(首都-国家)、甚至 COMPARATIVE/SUPERLATIVE(比较级/最高级)等抽象关系(见 GloVe 的图 5.9)。
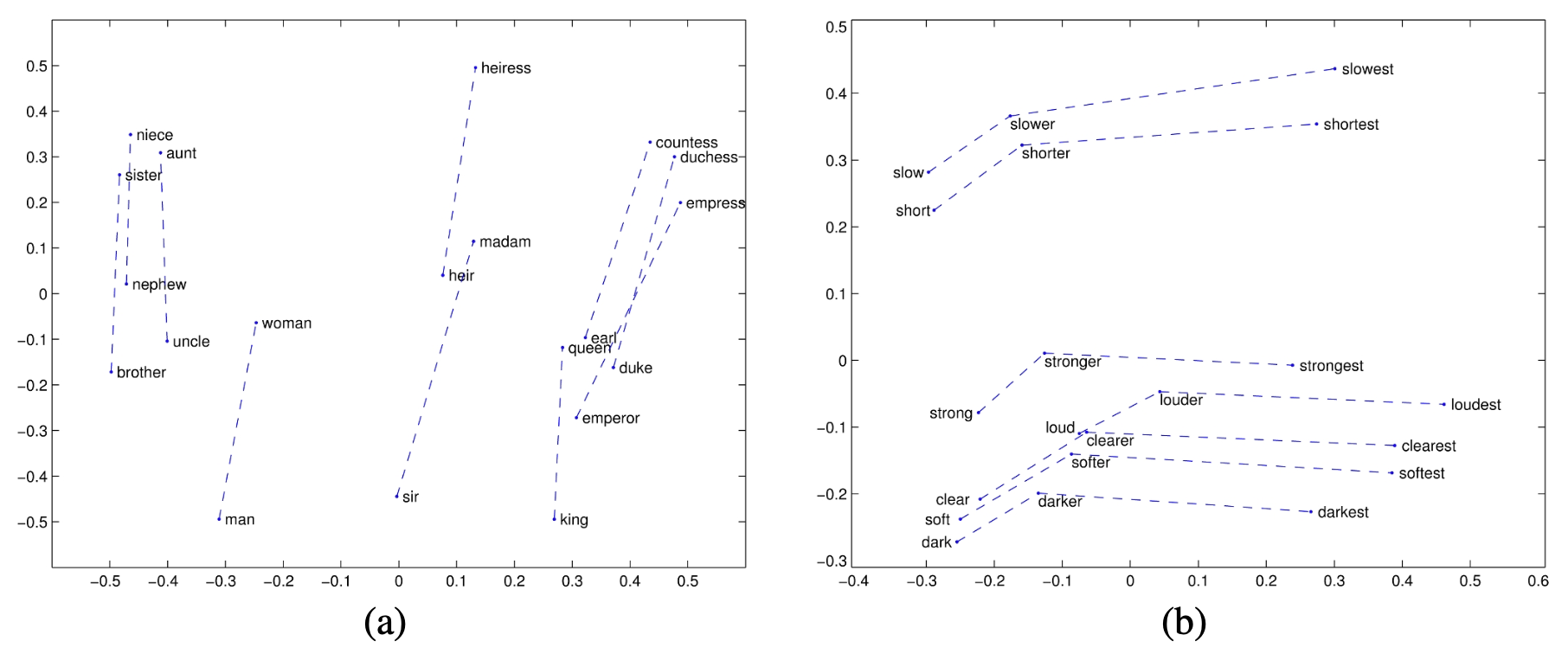
图 5.9:GloVe 向量空间的关系特性(投影至二维展示): (a) $\overrightarrow{king} - \overrightarrow{man} + \overrightarrow{woman}$ 接近 $\overrightarrow{queen}$; (b) 向量偏移似乎能捕捉形容词的比较级与最高级形态(Pennington et al., 2014)。
对于形式为 $\mathbf{a} : \mathbf{b} :: \mathbf{a}^* : \mathbf{b}^*$ 的问题(即已知向量 $\mathbf{a}$、$\mathbf{b}$、$\mathbf{a}^*$,需找出 $\mathbf{b}^*$),平行四边形方法的计算公式为:
$$ \hat{\mathbf{b}^*} = \arg\min_{\mathbf{x}} \text{distance}(\mathbf{x},\ \mathbf{b} - \mathbf{a} + \mathbf{a}^*) \tag{5.28} $$其中 distance 可采用欧氏距离等度量函数。
不过,这一方法存在一些局限。 在 word2vec 或 GloVe 空间中,平行四边形算法返回的最近词通常并非真正的 $\mathbf{b}^*$,而是三个输入词之一或其形态变体。 例如,在 cherry:red :: potato:x 中,系统可能返回 potato 或 potatoes,而非正确答案 brown。 因此,实际应用中必须显式排除输入词及其变体。 嵌入空间在以下情况表现较好:涉及高频词;向量偏移较小;关系类型明确(如国家与其首都、动词/名词与其屈折形式)。 但对于其他类型的关系,效果往往不佳(Linzen, 2016;Gladkova et al., 2016;Schluter, 2018;Ethayarajh et al., 2019a)。 Peterson 等人(2020)甚至指出,平行四边形方法过于简化,无法真实反映人类形成此类类比的认知过程。
5.7.1 嵌入与历史语义学
嵌入也可用于研究词义如何随时间演变,方法是为不同历史时期的文本分别构建多个嵌入空间。 例如,图 5.10 展示了过去两个世纪中若干英语词的语义变化。 计算方式是,使用历史语料库(如 Google n-grams(Lin et al., 2012b)和《美国英语历史语料库》(Davies, 2012)),为每个十年单独训练一个词嵌入空间。

图 5.10:使用 word2vec 向量对三个英语词的语义演变进行 t-SNE 可视化(Hamilton et al., 2016b)。 图中每个词的现代含义及其灰色上下文词,均来自最近时期(现代)的嵌入空间。 早期的点则来自更早的历史嵌入空间。 可视化结果展示了以下演变过程:gay 从表示 “cheerful”(愉快)或 “frolicsome”(嬉戏的)的含义,逐渐转向指代同性恋; broadcast 从最初的“播撒种子”义,发展出如今的“广播/传输”义; awful 经历了贬义化(pejoration):从“充满敬畏”(full of awe)演变为“糟糕或可怕”(terrible or appalling)。