在前面的章节中,我们了解了如何将一个词表示为稀疏的长向量,其维度对应词汇表中的词或文档集合中的文档。 现在,我们介绍一种更强大的词表示方法:嵌入(embeddings),即短而稠密的向量。 与迄今为止所见的向量不同,嵌入向量是短的,其维度 $d$ 通常在50到1000之间,远小于之前遇到的庞大词汇量 $|V|$ 或文档数量 $D$。 这些维度 $d$ 并没有明确的解释意义。 并且这些向量是稠密的:向量元素不再是稀疏的、大部分为零的计数或计数函数,而是可以为负的实数值。
事实证明,在每一项自然语言处理任务中,稠密向量的表现都优于稀疏向量。 虽然我们尚未完全理解所有原因,但有一些合理的解释。 将词表示为300维的稠密向量,比起表示为50,000维的向量,能让分类器学习的权重少得多,更小的参数空间可能有助于提升泛化能力并避免过拟合。 稠密向量也可能更有效地捕捉同义关系。 例如,在稀疏向量表示中,像 car 和 automobile 这样的同义词对应的维度是彼此独立且无关的;因此,稀疏向量可能无法捕捉到一个以 car 为邻近词的词与另一个以 automobile 为邻近词的词之间的相似性。
本节中介绍一种计算嵌入的方法:负采样 skip-gram(skip-gram with negative sampling),有时简称为 SGNS。 跳字算法是名为 word2vec 的软件包中的两种算法之一,因此该算法有时被笼统地称为 word2vec(Mikolov 等,2013a;Mikolov 等,2013b)。 word2vec 方法速度快、训练高效,且代码和预训练嵌入模型在线上易于获取。 Word2vec 嵌入是静态嵌入(static embeddings),意味着该方法为词汇表中的每个词学习一个固定的嵌入表示。 在第 10 章中,我们将介绍学习动态上下文嵌入(context embeddings)的方法,如流行的 BERT 表示系列,其中每个词的向量会因其所处的不同上下文而变化。
word2vec 的核心理念是:不再统计每个词 $w$ 在某个词(比如 apricot)附近出现的频率,而是训练一个分类器来执行一个二元预测任务:“词 $w$ 是否可能出现在 apricot 附近?” 我们实际上并不关心这个预测任务本身;而是将分类器学习到的权重作为词的嵌入表示。
这里的革命性思想在于,我们可以直接使用连续文本作为此类分类器的隐式监督训练数据:一个在目标词 apricot 附近出现的词 $c$,就充当了“词 $c$ 是否可能出现在 apricot 附近?”这一问题的黄金标准“正确答案”。 这种方法通常被称为自监督(self-supervision),它避免了任何人工标注监督信号的需求。 这一思想最初在神经语言建模任务中被提出,Bengio 等人(2003)和 Collobert 等人(2011)表明,一个神经语言模型(一种学习根据前文预测下一个词的神经网络)可以直接使用连续文本中的下一个词作为其监督信号,并可在执行此预测任务的同时学习每个词的嵌入表示。
我们将在下一章介绍神经网络的实现方法,但 word2vec 是一个比神经网络语言模型简单得多的模型,主要体现在两方面。 首先,word2vec 简化了任务(将其变为二元分类而非词预测)。 其次,word2vec 简化了架构(训练一个逻辑回归分类器,而不是一个多层、包含隐藏层且需要更复杂训练算法的神经网络)。 skip-gram 的设计原理如下:
- 将目标词与其邻近的上下文词视为正例。
- 从词典中随机采样其他词以获得负例。
- 使用逻辑回归训练一个分类器来区分这两种情况。
- 将学习到的权重用作嵌入表示。
5.5.1 分类器
我们先思考分类任务本身,然后再讨论如何训练。 假设有一个如下句子,目标词为 apricot,并假设使用 ±2 的上下文窗口:
... lemon, a [tablespoon of apricot jam, a] pinch ...
c1 c2 w c3 c4
我们的目标是训练一个分类器,使其在给定一个目标词 $w$ 与候选上下文词 $c$ 组成的元组 $(w,c)$ 时(例如 (apricot, jam),或可能是 (apricot, aardvark)),能够返回 $c$ 是真实上下文词的概率(对 jam 为真,对 aardvark 为假):
$$ P(+|w,c) \tag{5.11} $$词 $c$ 不是 $w$ 的真实上下文词的概率就是 1 减去公式 5.11:
$$ P(−|w,c) = 1 − P(+|w,c) \tag{5.12} $$分类器如何计算概率 $P$? Skip-gram模型的基本思想是,将此概率建立在嵌入相似性之上:如果一个词的嵌入向量与目标词的嵌入向量相似,那么它就更有可能出现在目标词附近。 为了计算这些稠密嵌入之间的相似性,我们依赖于这样一个原则:如果两个向量的点积很高,则它们是相似的(毕竟,余弦相似度只是归一化的点积)。换句话说:
$$ Similarity(w,c) \approx \mathbf{c} \cdot \mathbf{w} \tag{5.13} $$点积 $\mathbf{c} \cdot \mathbf{w}$ 本身不是一个概率,它只是一个取值范围从 $-\infty$ 到 $\infty$ 的数值(由于 word2vec 嵌入向量中的元素可以为负,因此点积结果也可能为负)。 为了将点积转化为概率,我们将使用逻辑回归(logistic)或Sigmoid函数 $\sigma(x)$,这是逻辑回归的核心组成部分:
$$ \sigma(x) = \frac{1}{1 + exp(−x)} \tag{5.14} $$我们将词 $c$ 是目标词 $w$ 的真实上下文词的概率建模为:
$$ \begin{align*} P(+|w,c) &= \sigma(\mathbf{c} \cdot \mathbf{w}) \\ &= \frac{1}{1 +exp(−\mathbf{c} \cdot \mathbf{w})} \tag{5.15} \end{align*} $$Sigmoid 函数返回一个介于 0 和 1 之间的数值,但要使其成为一个有效的概率,还需要确保两个可能事件($c$ 是上下文词,以及 $c$ 不是上下文词)的总概率之和为 1。 因此,将词 $c$ 不是 $w$ 的真实上下文词的概率估计为:
$$ \begin{align*} P(−|w,c) &= 1 −P(+|w,c) \\ &= \sigma(-\mathbf{c} \cdot \mathbf{w}) \\ &= \frac{1}{1 + exp(\mathbf{c} \cdot \mathbf{w})} \tag{5.16} \end{align*} $$公式 5.15 给出了单个词的概率,但在一个上下文窗口中存在多个上下文词。 Skip-gram 做了一个简化假设,即所有上下文词是相互独立的,这允许我们将它们的概率直接相乘:
$$ P(+|w,c_{1:L}) = \prod_{i=1}^L \sigma(\mathbf{c_i} \cdot \mathbf{w}) \tag{5.17} $$$$ logP(+|w,c_{1:L}) = \sum_{i=1}^L log \sigma(\mathbf{c_i} \cdot \mathbf{w}) \tag{5.18} $$总之,skip-gram 训练一个概率分类器,该分类器在给定一个测试目标词 $w$ 及其包含 $L$ 个词的上下文窗口 $c_{1:L}$ 时,会根据该上下文窗口与目标词的相似程度来分配一个概率。 首先计算目标词嵌入向量与每个上下文词嵌入向量的点积,然后对点积应用 逻辑回归(Sigmoid)函数,在此基础上得出概率。 为了计算这个概率,我们只需要词汇表中每个目标词和上下文词的嵌入表示即可。
图 5.16 展示了我们需要的参数背后的基本思想。 实际上,skip-gram 为每个词存储了两个嵌入向量:一个作为目标词时的嵌入,另一个作为上下文词时的嵌入。 因此,我们需要学习的参数是两个矩阵 W 和 C,每个矩阵都包含了词汇表 V 中全部 $|V|$ 个词的嵌入向量。1 现在,我们转向如何学习这些嵌入向量(而这才是训练这个分类器的真正目的)。
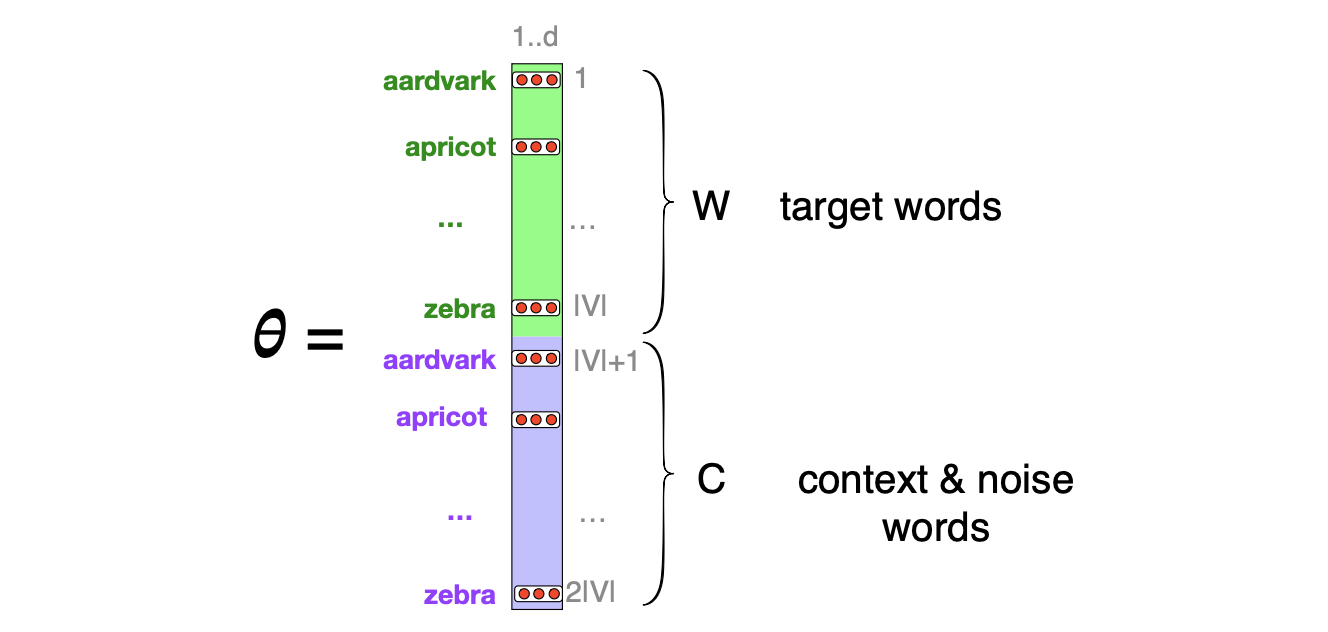
图 5.6 Skip-gram 模型所学习的嵌入向量。 该算法为每个词存储两个嵌入向量:目标嵌入(有时称为输入嵌入)和上下文嵌入(有时称为输出嵌入)。 算法所学习的参数 $\theta$ 因此是一个由 $2|V|$ 个向量组成的矩阵,每个向量维度为 $d$,它通过将两个矩阵拼接而成:目标嵌入矩阵 $\mathbf{W}$ 和上下文-噪声嵌入矩阵 $\mathbf{C}$。
5.5.2 学习 skip-gram 嵌入
Skip-gram 嵌入的学习算法以文本语料库和选定的词汇表大小 N 作为输入。 它首先为词汇表中的 N 个词各自分配一个随机的嵌入向量,然后迭代地调整每个词 $w$ 的嵌入向量,使其更接近在文本中与其邻近出现的词的嵌入向量,同时远离那些不邻近出现的词的嵌入向量。 我们先从一个训练数据片段开始:
... lemon, a [tablespoon of apricot jam, a] pinch ...
c1 c2 w c3 c4
这个例子有一个目标词 $w$(apricot),以及在 $L = \pm{2}$ 窗口内的 4 个上下文词,从而生成了 4 个正例训练样本(如下方左侧所示):
正例 +
| w | $c_{pos}$ |
|---|---|
| apricot | tablespoon |
| apricot | of |
| apricot | jam |
| apricot | a |
负例 -
| w | $c_{neg}$ | w | $c_{neg}$ |
|---|---|---|---|
| apricot | aardvark | apricot | seven |
| apricot | my | apricot | forever |
| apricot | where | apricot | dear |
| apricot | coaxial | apricot | if |
为了训练一个二元分类器,还需要负例样本。 事实上,采用负采样的skip-gram(SGNS)使用的负例样本数量多于正例样本(两者之间的比例由参数 $k$ 设定)。 因此,对于每一个 $(w,c_{pos})$ 训练实例,我们将创建 $k$ 个负样本,每个负样本由目标词 $w$ 加上一个“噪声词” $c_{neg}$ 组成。 噪声词是从词典中随机选取的一个词,但不能是目标词 $w$ 本身。 上方第二个表格展示了 $k = 2$ 的情况,因此对于每个正例 $w,c_{pos}$,我们将在负训练集中生成 2 个负例。
噪声词的选取依据其加权的 unigram 频率 $p_{\alpha} (w)$,其中 $\alpha$ 是一个权重参数。 如果我们按照未加权的频率 $p(w)$ 进行采样,就意味着以 unigram 概率 $P(\text{“the”})$ 选择词 the 作为噪声词,以 unigram 概率 $p(\text{“aardvark”})$ 选择 aardvark,依此类推。 但在实践中,通常将 $\alpha$ 设为 0.75,即使用权重 $p^{3/4}(w)$:
$$ P_α (w) = \frac{count(w)^α}{\sum_{w'}count(w')^\alpha} \tag{5.19} $$将 $\alpha$ 设为 0.75 能获得更好的性能,因为它略微提高了罕见词作为噪声词的概率:对于低频词,$P_\alpha (w) > P(w)$。 为了说明这一基本思想,可以用一个 $\alpha = 0.75$ 的例子来计算,假设有两个事件,$P(a) =0.99$ 和 $P(b) =0.01$:
$$ \begin{align*} P_{\alpha} (a) = \frac{.99^{.75}}{.99^{.75} +.01^{.75}} = 0.97 \\ P_{\alpha} (b) = \frac{.01^{.75}}{.99^{.75} +.01^{.75}} = 0.03 \tag{5.20} \end{align*} $$因此,使用 $\alpha = 0.75$ 将稀有事件 $b$ 的概率从 0.01 提高到了 0.03。
在给定一组正例和负例训练样本以及一组初始嵌入向量的情况下,学习算法的目标是调整这些嵌入向量,以实现以下两个目标:
- 最大化从正例样本中提取的目标词与上下文词对 $(w,c_{pos})$ 的相似度。
- 最小化从负例样本中提取的 $(w,c_{neg})$ 词对的相似度。
如果考虑一个词/上下文组合 $(w,c_{pos})$ 及其 $k$ 个噪声词 $c_{neg1} ...c_{negk}$,可以将这两个目标表示为以下需要最小化的损失函数 $L$(因此前面有负号 −)。 其中第一项表示,我们希望分类器为真实上下文词 $c_{pos}$ 分配一个较高的概率表明它是邻居。 第二项表示,我们希望为每个噪声词 $c_{neg_i}$ 分配一个较高的概率表明它们不是邻居,由于假设了独立性,因此将这些概率相乘:
$$ \begin{align*} L &= −log[P(+|w,c_{pos}) \prod^k_{i=1} P(−|w,c_{neg_i})] \\ &= −[logP(+|w,c_{pos}) + \sum^k_{i=1}log P(−|w,c_{neg_i} )] \\ &= −[logP(+|w,c_{pos}) + \sum^k_{i=1} log(1 −P(+|w,c_{neg_i} ))] \\ &= −[log\sigma(c_{pos} \cdot w) + \sum^k_{i=1} log\sigma(c_{neg_i} \cdot w)] \tag{5.21} \end{align*} $$也就是说,我们希望最大化目标词与真实上下文词的点积,同时最小化目标词与 $k$ 个通过负采样得到的非邻近词的点积。
使用随机梯度下降法来最小化这个损失函数。 图 5.7 展示了学习一步的基本思想。
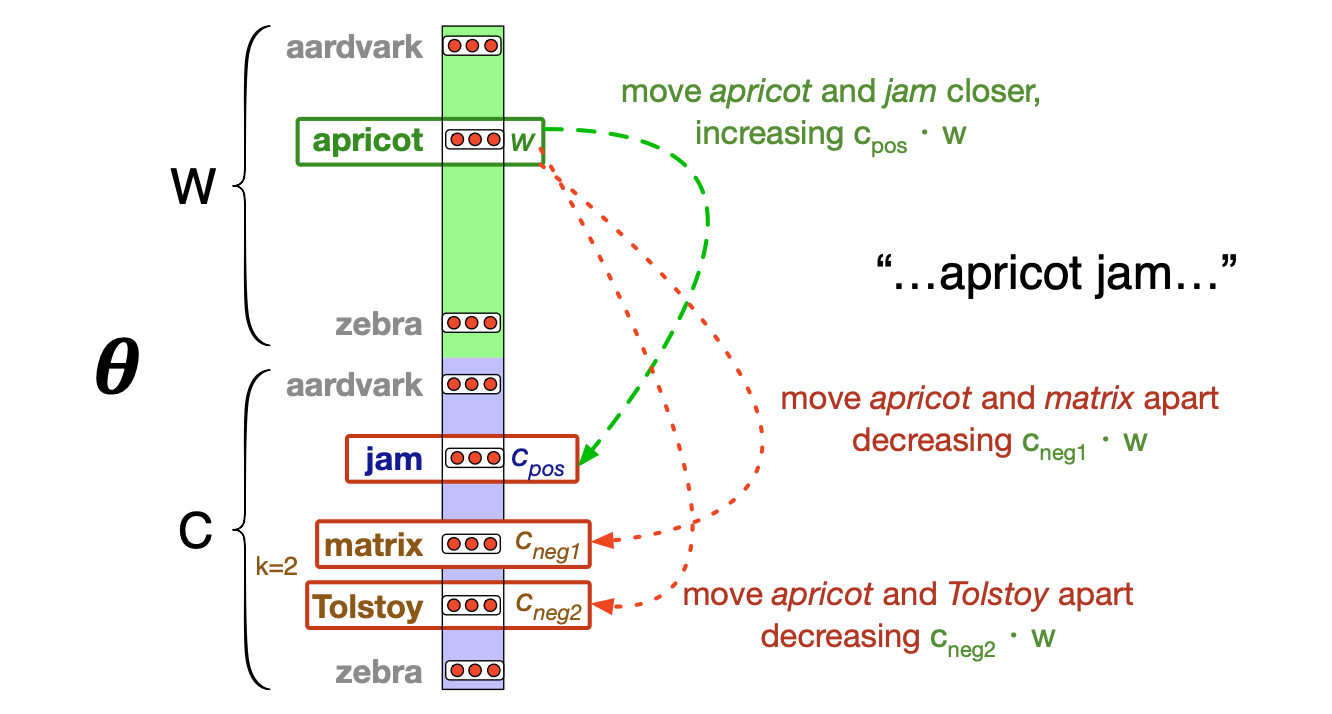
图 5.7 梯度下降一步的基本思想。跳字模型试图调整嵌入向量,使得目标嵌入(此处为 apricot)与邻近词的上下文嵌入(此处为 jam)更接近(点积更高),而与那些不邻近出现的噪声词的上下文嵌入(此处为 Tolstoy 和 matrix)距离更远(点积更低)。
为了得到梯度,需要对公式 5.21 关于不同的嵌入向量求导。 结果导数如下所示(证明过程留作本章末尾的练习题):
$$ \begin{align*} \frac{\partial L}{\partial c_{pos}} &= [\sigma(\mathbf{c}_{pos} \cdot \mathbf{w}) − 1]\mathbf{w} \tag{5.22} \\ \frac{\partial L}{\partial c_{neg}} &= [\sigma(\mathbf{c}_{neg} \cdot \mathbf{w})]\mathbf{w} \tag{5.23} \\ \frac{\partial L}{\partial w} &= [\sigma(\mathbf{c}_{pos} \cdot \mathbf{w}) − 1]\mathbf{c}_{pos} + \sum^k_{i=1}[\sigma(\mathbf{c}_{neg_i} \cdot \mathbf{w})]\mathbf{c}_{neg_i} \tag{5.24} \end{align*} $$因此,在随机梯度下降中,从时间步 $t$ 到 $t + 1$ 的更新方程为:
$$ \begin{align*} c^{t+1}_{pos} &= c^t_{pos} − \eta[\sigma(c^t_{pos} \cdot \mathbf{w}^t) − 1]\mathbf{w}^t \tag{5.25} \\ c^{t+1}_{neg} &= c^t_{neg} − \eta[\sigma(c^t_{neg} \cdot \mathbf{w}^t)]\mathbf{w}^t \tag{5.26} \\ w^{t+1} &= w^t − \eta[[\sigma(c^t_{pos} \cdot \mathbf{w}^t) − 1]c^t_{pos} + \sum^k_{i=1}[\sigma(c^t_{neg_i} \cdot \mathbf{w}^t )]c^t_{neg_i}] \tag{5.27} \end{align*} $$因此,与逻辑回归类似,该学习算法首先对 $\mathbf{W}$ 和 $\mathbf{C}$ 矩阵进行随机初始化,然后遍历训练语料库,使用梯度下降法调整 $\mathbf{W}$ 和 $\mathbf{C}$,通过执行公式 (5.25) 到 (5.27) 的更新,以最小化公式 5.21 中的损失函数。
回顾一下,skip-gram 模型为每个词 i 学习了两个独立的嵌入向量:目标嵌入 $w_i$ 和 上下文嵌入 $c_i$,它们分别存储在两个矩阵中,即目标矩阵 $\mathbf{W}$ 和上下文矩阵 $\mathbf{C}$。 通常的做法是将这两个向量相加,用向量 $\mathbf{w}_i + \mathbf{c}_i$ 来表示词 i。 或者,也可以丢弃 $\mathbf{C}$ 矩阵,仅用向量 $\mathbf{w}_i$ 来表示每个词 $i$。
与 tf-idf 等简单的基于计数的方法一样,上下文窗口大小 $L$ 会影响跳字模型嵌入的性能,实验中通常会在开发集上对参数 $L$ 进行调优。
5.5.3 其他类型的静态嵌入
静态嵌入有多种类型。word2vec 的一个扩展是 fasttext (Bojanowski 等, 2017),它解决了迄今为止介绍的 word2vec 存在一个的问题:它无法很好地处理未知词——即在测试语料库中出现但在训练语料库中未见过的词。
一个相关的问题是词的稀疏性,例如在具有丰富形态的语言中,每个名词和动词的许多变体形式可能只出现很少的次数。
fasttext 通过使用子词模型来解决这些问题,它将每个词表示为该词本身加上一组构成它的 n-gram 的集合,并在每个词的首尾添加特殊的边界符号 < 和 >。例如,当 $n = 3$ 时,单词 where 将由序列 < where> 加上以下字符 n-gram 表示:
<wh, whe, her, ere, re>
然后,为每个构成的 n-gram 学习一个 skipgram 嵌入向量,而单词 where 则由其所有构成 n-gram 的嵌入向量之和来表示。 未知词则仅能由其构成 n-gram 的嵌入向量之和来表示。 一个包含 157 种语言预训练嵌入的 fasttext 开源库可在 https://fasttext.cc 获取。
另一个被广泛使用的静态嵌入模型是 GloVe (Pennington 等, 2014),是 Global Vectors 的缩写,因为该模型基于捕捉语料库的全局统计信息。 GloVe 基于词-词共现矩阵中的概率比值。
事实证明,像 word2vec 这样的稠密嵌入与像 PPMI 这样的稀疏嵌入之间存在着优雅的数学关系,其中 word2vec 可以被视为在隐式地优化一个 PPMI 矩阵的某种函数 (Levy 和 Goldberg, 2014c)。
理论上,目标矩阵和上下文矩阵可以使用不同的词汇表,但为了简化,我们假设使用一个共享的词汇表 V。 ↩︎