为了度量两个目标词 $v$ 和 $w$ 之间的相似性,我们需要一种度量方法,它能接受两个向量(维度相同,要么都以词语为维度,因此长度为 $|V|$,要么都以文档为维度,长度为 $|D|$),给出它们相似程度的度量值。 迄今为止最常用的相似性度量是向量之间夹角的余弦(cosine)。
余弦——像NLP中使用的大多数向量相似性度量一样——基于线性代数中的点积(dot product)运算符,也称为内积(inner product):
$$ \begin{align*} \text{点积}(\mathbf{v},\mathbf{w}) &= \mathbf{v} \cdot \mathbf{w} \\ &= \sum_{i=1}^N v_i w_i \\ &= v_1w_1 + v_2w_2 + ... + v_N w_N \tag{5.7} \end{align*} $$点积可以作为一种相似性度量,因为当两个向量在相同维度上具有较大的值时,点积的值往往会很高。 相反,如果两个向量在不同维度上为零(即正交向量),它们的点积为 0,这表示它们的差异性很强。
然而,这种原始的点积作为相似性度量存在一个问题:它偏向于长度更长的向量。 向量的长度定义为:
$$ |\mathbf{v}| = \sqrt{\sum_{i=1}^N v_i^2} \tag{5.8} $$如果一个向量更长,每个维度的值更高,其点积也会更高。 更频繁出现的词具有更长的向量,因为它们倾向于与更多的词共现,并且与每个共现词的共现值也更高。 因此,原始点积对高频词的值会更高。 但这是一个问题;我们希望相似性度量能告诉我们两个词有多相似,而不受它们频率的影响。
我们通过将点积除以两个向量的长度来对点积进行归一化,从而修正这一问题。 这种归一化的点积实际上等于两个向量之间夹角的余弦,这源于两个向量 $\mathbf{a}$ 和 $\mathbf{b}$ 之间点积的定义:
$$ \begin{align*} \mathbf{a} \cdot \mathbf{b} &= |\mathbf{a}||\mathbf{b}| \cos\theta \\ \frac{\mathbf{a} \cdot \mathbf{b}}{|\mathbf{a}||\mathbf{b}|} &= \cos\theta \tag{5.9} \end{align*} $$因此,两个向量 $\mathbf{v}$ 和 $\mathbf{w}$ 之间的余弦相似性度量可计算为:
$$ \begin{align*} \text{余弦}(v,w) &= \frac{v \cdot w}{|v||w|} \\ &= \frac{\sum_{i=1}^N v_iw_i}{\sqrt{\sum_{i=1}^N v_i^2}\sqrt{\sum_{i=1}^N w_i^2}} \tag{5.10} \end{align*} $$对于某些应用,我们会预先进行归一化,将每个向量除以其长度来,从而创建长度为 1 的单位向量(unit vector)。 因此,可以将向量 $\mathbf{a}$ 除以 $|$\mathbf{a}$|$ 来计算出一个单位向量。 对于单位向量,点积就等于余弦值。
余弦值的范围从 1(向量方向相同)到 0(向量正交),再到 -1(向量方向相反)。 但由于原始的频率值是非负的,这些向量的余弦值范围为 0 到 1。
我们看看余弦如何计算“cherry”(樱桃)和“digital”(数字)哪个词在意义上更接近“information”(信息),仅使用下表简化后的原始计数数据:
| pie | data | computer | |
|---|---|---|---|
| cherry | 442 | 8 | 2 |
| digital | 5 | 1683 | 1670 |
| information | 5 | 3982 | 3325 |
模型判断:information 与 digital 的距离远小于它与 cherry 的距离,这一结果看起来很合理。 图 5.5 展示了其可视化效果。
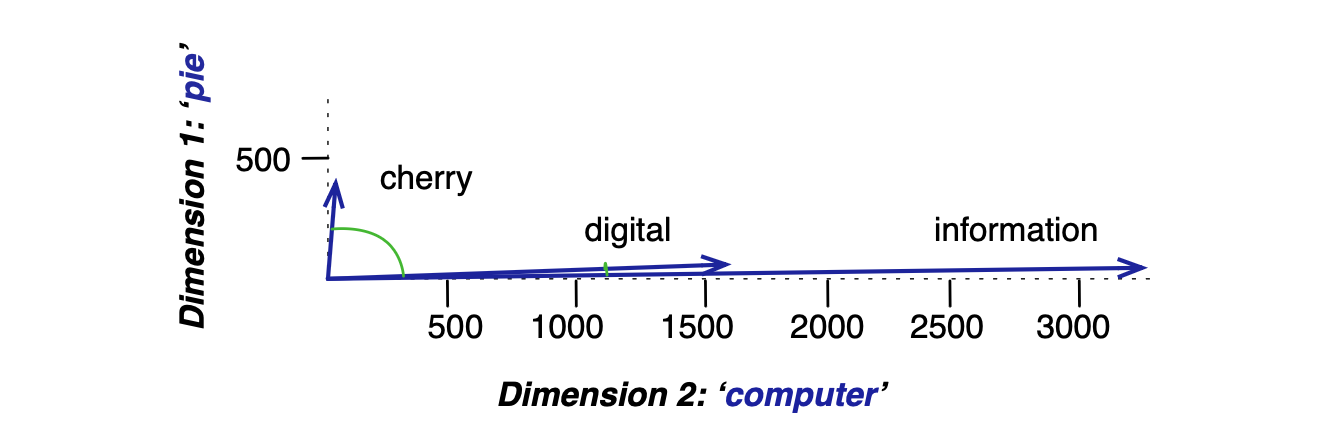
图 5.5:余弦相似度的(粗略)图示。图中展示了三个词(cherry、digital、information)在由邻近词 computer 和 pie 的频次所定义的二维空间中的向量。 图中未直接显示余弦值,但突出了向量之间的夹角;注意,digital 与 information 之间的夹角,小于 cherry 与 information 之间的夹角。 当两个向量越相似,它们的余弦值越大,夹角越小;当夹角为最小值 0° 时,余弦达到最大值 1;其他所有角度的余弦值均小于 1。
余弦相似度可用于计算词与词之间的相似性,适用于多种任务,例如寻找同义词、追踪词义演变,或在不同语料库中自动发现词语的含义差异。 例如,要找出与任意目标词 $w$ 最相似的 10 个词,只需计算 $w$ 与其余 $|V| - 1$ 个词的余弦值,排序后取前 10 名即可。