“三维空间中向量最重要的属性是:位置、位置、位置。”
—— Randall Munroe,来自 xkcd 第 2358 期 的悬停提示
我们现在介绍第一种计算词向量嵌入的方法。 这种最简单的词义向量模型基于共现矩阵(co-occurrence matrix),用来表示词语共同出现的频率。 我们定义一种特定的共现矩阵,称为词-上下文矩阵(word-context matrix):矩阵的每一行对应词汇表中的一个词(目标词);每一列对应词汇表中另一个词作为上下文出现的次数。 因此,这个矩阵的维度是 $|V| \times |V|$($|V|$ 表示词汇表大小),每个单元格记录的是:在某个训练语料中,某一行的目标词与某一列的上下文词在邻近位置共同出现的次数。
那么,“邻近”具体指什么? 可以有多种实现方式,但我们先采用最简单的一种:以目标词为中心,左右各取 4 个词作为窗口。 这样,每个单元格就表示:在训练语料中,该列的上下文词出现在该行目标词 ±4 词范围内的总次数。
我们用四个词来演示这一过程:cherry(樱桃)、strawberry(草莓)、digital(数字的)、information(信息)。 对每个词,我们从语料中选取一个实例,并展示其 ±4 词的上下文窗口:
- is traditionally followed by cherry pie, a traditional dessert
- often mixed, such as strawberry rhubarb pie. Apple pie
- computer peripherals and personal digital assistants. These devices usually
- a computer. This includes information available on the internet
如果我们在一个大型语料中统计每个词的所有出现,并计算其上下文词的频次,就能得到完整的词-上下文共现矩阵。
但完整的矩阵非常庞大:因为对词汇表中的每个词(共 $|V|$ 个),都要统计它与其他所有词的共现次数,所以维度是 $|V| \times |V|$。
因此,我们改用一个小规模的例子来说明。
假设我们只关注上述四个词,并且只考虑以下三个上下文词:a、computer、pie。
此外,我们仅使用上面给出的微型语料进行计数。
那么,在看图 5.2 之前,请先手动计算这四个词(cherry、strawberry、digital、information)在上述三个上下文词上的共现次数。

图 5.2:基于上述四个上下文窗口统计得到的四个词的共现向量,仅展示三个可能的上下文维度。cherry 的向量用红色标出。注意:真实向量的维度要大得多,因此会更加稀疏。
希望你的计数结果与图 5.2 一致,每个单元格表示:某一行定义的词,在某一列定义的上下文词附近出现的次数。
于是,每一行就构成了一个代表该词的向量。 回顾一下基础线性代数知识:向量本质上就是一个数字列表(或数组)。 例如,cherry 被表示为列表 $[1, 0, 1]$(图 5.2 中的第一行向量),而 information 被表示为列表 $[1, 1, 0]$(第四行向量)。
一个向量空间(vector space)是由一组向量构成的集合,其特征由维度(dimension)决定。 三维向量空间中的每个向量,都包含对应于该空间三个维度的三个元素。 我们通常将三维空间中的向量简称为“三维向量”,即每个维度上有一个数值。 在图 5.2 的例子中,我们特意将文档向量设为三维,只是为了能在一页纸上画出来。 而在真实的词-文档矩阵中,文档向量的维度是 $|V|$,即词汇表的大小。
向量中数值的顺序,代表了文档在不同维度上的变化。 例如,在这些向量中,第三个维度表示上下文中 pie(派)出现的次数; 第二个维度表示 computer(计算机)出现的次数。 注意:information 和 digital 在“computer”这一维度上的值相同(都是 1)。
实际上,我们不会只基于单个上下文窗口来计算词向量,而是基于整个语料库进行统计。 我们看看真实数据中的计数是什么样子。 图 5.3 展示了这四个词的部分词-词共现矩阵。由于在教科书页面上无法展示全部 $|V|$ 个可能的上下文维度,我们从中挑选了 6 个维度,并基于维基百科语料库(Davies, 2015)计算了共现频次。

图 5.3:在维基百科语料中计算得到的四个词的共现向量,展示了其中六个维度(为教学目人工挑选)。digital 的向量用红色标出。注意:真实向量的维度要大得多,因此会更加稀疏——即大多数维度上的值为零。
从图 5.3 可以看出,cherry 和 strawberry 彼此更相似(它们的上下文中常出现 pie 和 sugar);而它们与 digital 等词则差异较大。 反过来,digital 和 information 之间的相似度,远高于它们与 strawberry 的相似度。
我们可以把一个文档的向量看作 $|V|$ 维空间中的一个点。 因此,图 5.3 中的文档在三维空间中是一些点。 图 5.4 则展示了这种空间表示。
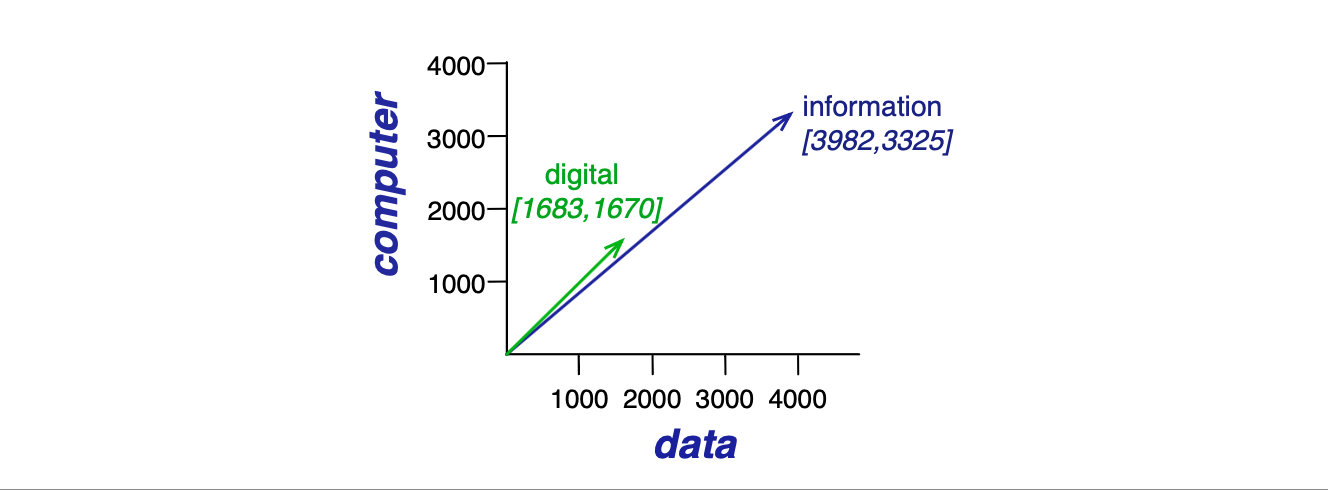
图 5.4:digital 与 information 的词向量在二维空间中的可视化,仅展示其中两个维度,分别对应 data 和 computer。
注意:向量的维度 $|V|$ 通常等于词汇表大小,一般取训练语料中最常见的 10,000 到 50,000 个词。再往后增加低频词通常帮助不大。 由于这些向量中绝大多数数值为零,因此被称为稀疏向量表示(sparse vector representations)。 针对稀疏矩阵,已有高效的存储和计算算法。
此外,也可以对单元格中的计数值应用各种加权函数。 最常用的加权方法是 tf-idf,我们将在第 11 章介绍。历史上还出现过多种其他加权方式。
现在,我们已经建立了基本直觉,接下来将深入探讨如何计算词与词之间的相似度。