文本分类的训练与测试流程与我们在语言建模中所见(第 3.2 节)一致:我们使用训练集(training set)来训练模型,然后使用开发测试集(development test set,也称为 devset)来调整某些参数,并总体上确定哪个模型表现最佳。 一旦我们选定自认为最优的模型,便在此前从未见过的测试集(test set)上运行该模型,并报告其性能。
虽然使用 devset 可以避免对测试集过拟合,但采用固定的训练集、devset 和测试集会带来另一个问题:为了保留足够多的数据用于训练,测试集(或 devset)可能不够大,从而缺乏代表性。 难道不能设法既用全部数据进行训练,又用全部数据进行测试吗?答案是肯定的——我们可以采用交叉验证(cross-validation)。
在交叉验证中,我们先选定一个数字 $k$,并将数据划分为 $k$ 个互不重叠的子集,称为折(folds)。 接着,依次选取其中一折作为测试集,在其余 $k-1$ 折上训练分类器,并在该测试集上计算错误率。 然后换另一折作为测试集,再次在剩下的 $k-1$ 折上训练模型。 如此重复 $k$ 次,每次使用不同的测试折,最后将这 $k$ 次测试得到的错误率取平均,作为模型的平均错误率。 例如,若选择 $k = 10$,我们将训练 10 个不同的模型(每个使用 90% 的数据),测试 10 次,并对这 10 个结果取平均。 这种方法称为10 折交叉验证(10-fold cross-validation)。
交叉验证唯一的缺点在于:由于所有数据都被用于测试,因此整个语料库必须保持“盲态”:不能事先查看任何数据以推测可能的特征,也不能通过观察数据了解其分布情况,否则就相当于“偷看”了测试集。 这种作弊行为会导致对系统性能的估计过于乐观。 然而,在设计自然语言处理系统时,通过观察语料来理解数据特性至关重要!那该怎么办? 为此,一种常见做法是:先划分出固定的训练集和测试集,然后仅在训练集内部进行 10 折交叉验证(用于模型选择或调参),而仍按常规方式在独立的测试集上计算率,如图 4.10 所示。
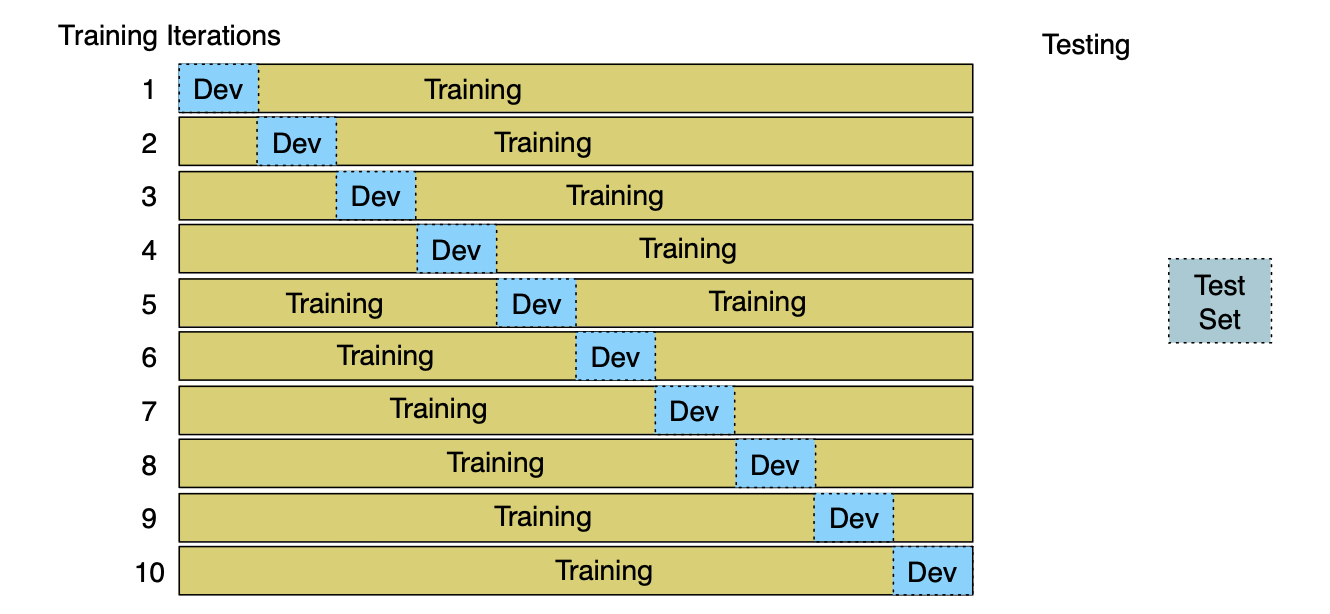
图 4.10 10 折交叉验证