为了介绍文本分类的评估方法,我们先考虑一些简单的二元检测任务(detection tasks)。 例如,在垃圾邮件检测中,我们的目标是将每封邮件标记为属于垃圾邮件类别(“正例”,positive)或不属于该类别(“负例”,negative)。 对于每个样本(即每封电子邮件),我们需要知道我们的系统是否将其判定为垃圾邮件。 我们还需要知道该邮件实际上是否为垃圾邮件,即由人工标注的、我们试图匹配的标签。 我们将这些人工标注的标签称为黄金标准标签(gold labels)。
再举一个例子:假设你是“美味派公司”(Delicious Pie Company)的 CEO,你想了解人们在社交媒体上对你们派的评价,于是你构建了一个系统来检测提及“美味派”的推文。 在这个任务中,正例是关于美味派的推文,负例则是所有其他推文。
在这两类场景中,我们都需一种指标来衡量垃圾邮件检测器(或派相关推文检测器)的表现好坏。 要评估任何检测系统,我们首先构建一个如图 4.7 所示的混淆矩阵(confusion matrix)。 混淆矩阵是一个表格,用于可视化算法输出与人工黄金标准标签之间的对应关系。它以两个维度(系统输出 vs. 黄金标签)组织数据,每个单元格代表一类可能的结果。 以垃圾邮件检测为例:真正例(True Positives, TP)代表邮件确实是垃圾邮件(由人工标签确认),且系统也正确地将其判为垃圾邮件。 假负例(False Negatives, FN)表示邮件确实是垃圾邮件,但系统错误地将其标记为非垃圾邮件。
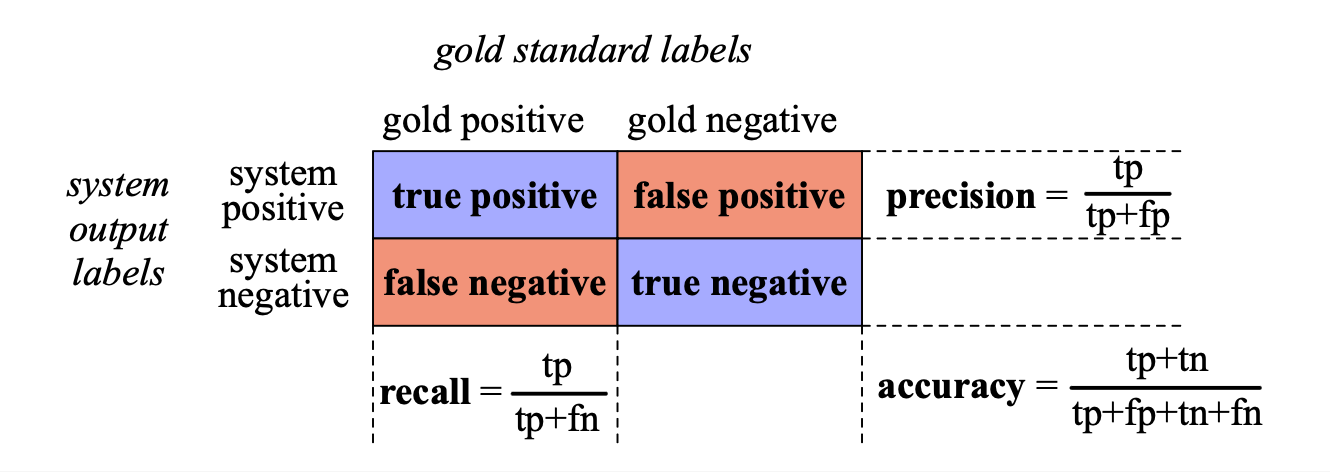
图 4.7 用于可视化二元分类系统相对于黄金标准标签表现的混淆矩阵。
表格右下角给出了准确率(accuracy)的计算公式,即系统正确分类的样本占总样本数(对于垃圾邮件或者派的例子,就是所有邮件或者所有推文)的百分比。 尽管准确率看似自然直观,但通常不用于文本分类任务。 原因在于,当类别分布严重不平衡时(例如垃圾邮件在全部邮件中占绝大多数,或关于派的推文在海量推文中极为稀少),准确率会严重失真。
为更清楚地说明这一点,设想我们分析了 100 万条推文,其中仅有 100 条讨论了对我们派的喜爱(或厌恶),其余 999,900 条则完全无关。 现在考虑一个极其简单的分类器:它一律将所有推文判为“与派无关”。该分类器会产生 999,900 个真负例和 100 个假负例,准确率达到 $\frac{999,900}{1,000,000} = 99.99\%$! 多么惊人的准确率! 我们是否该为此欢呼? 显然不该,因为这个“完美”的分类器一条相关评论都没找到,对我们毫无用处。 换言之,当目标任务是发现稀有事件(或至少是频率不平衡的事件)时,准确率就不是一个合适的评估指标,而这种情况在现实世界中极为普遍。
正因如此,我们通常不使用准确率,而是转向图 4.7 中所示的另外两个指标:精确率(Precision)和召回率(Recall)。 精确率衡量的是:在系统判定为正例的所有样本中(即系统标记为正例),真正为正例的比例(即按照人类的黄金标准标签为正例)。 精确率的定义为:
$$ \text{Precision} = \frac{\text{true positives}}{\text{true positives} + \text{false negatives}} $$召回率衡量的是,在所有实际为正例的样本中,被系统正确识别出来的比例。其定义为:
$$ \text{Recall} = \frac{\text{true positives}}{\text{true positives} + \text{false negatives}} $$这两个指标能有效解决前述“无派分类器”的问题。 尽管该分类器准确率高达 99.99%,但其召回率为 0(因为真正例为 0,假负例为 100,故召回率是 0/100)。 同时,由于它从未预测任何正例,其精确率在数学上未定义(分母为 0),但在实际应用中也被视为无效。 因此,与准确率不同,精确率和召回率都聚焦于“真正例”,即我们真正想要找的东西。
有许多方法可以将精确率和召回率合并为单一指标。 其中最简单的是 F 值(F-measure)(van Rijsbergen, 1975),定义如下:
$$ F_\beta = \frac{(\beta^2 + 1)PR}{\beta^2 P + R} $$其中参数 $\beta$ 用于调节召回率与精确率的相对重要性,具体取值可依据应用场景需求而定。 当 $\beta > 1$ 时,更重视召回率;当 $\beta < 1$ 时,更重视精确率。 当 $\beta = 1$ 时,精确率与召回率被同等对待,这是最常用的版本,称为 $F_{\beta=1}$ 或简写为 $F_1$:
$$ F_1 = \frac{2PR}{P + R} \tag{4.41} $$F 值本质上是精确率与召回率的加权调和平均(weighted harmonic mean)。 调和平均的定义是:一组数的倒数的算术平均值的倒数:
$$ \text{Harmonic Mean}(a_1,a_2,\dots,a_n) = \frac{n}{\frac{1}{a_1} + \frac{1}{a_2} + \cdots + \frac{1}{a_n}} \tag{4.42} $$因此,F 值可表示为:
$$ \begin{gather*} F = \frac{1}{\alpha \frac{1}{P} + (1 - \alpha)\frac{1}{R}} \\ \text{或} \\ \text{(令 } \beta^2 = \frac{1 - \alpha}{\alpha} \text{)} \quad F = \frac{(\beta^2 + 1)PR}{\beta^2 P + R} \tag{4.43} \end{gather*} $$之所以采用调和平均而非算术平均,是因为调和平均更接近两个数值中的较小者。 因此调和平均数对较低的指标给予更高权重,这种保守的特性在评估分类性能时尤为重要——它确保模型不能仅靠高精确率或高召回率“蒙混过关”,而必须在两者之间取得合理平衡。
4.9.1 多类别评估
到目前为止,我们讨论的文本分类任务都只有两个类别。 然而,自然语言处理中的许多分类任务实际上包含两个以上的类别。 例如,在情感分析中,我们通常有三个类别(正面、负面、中性);而在词性标注、词义消歧、语义角色标注、情绪识别等任务中,类别数量往往更多。 幸运的是,朴素贝叶斯算法本身就是一个多类别分类算法,可直接应用于这类场景。
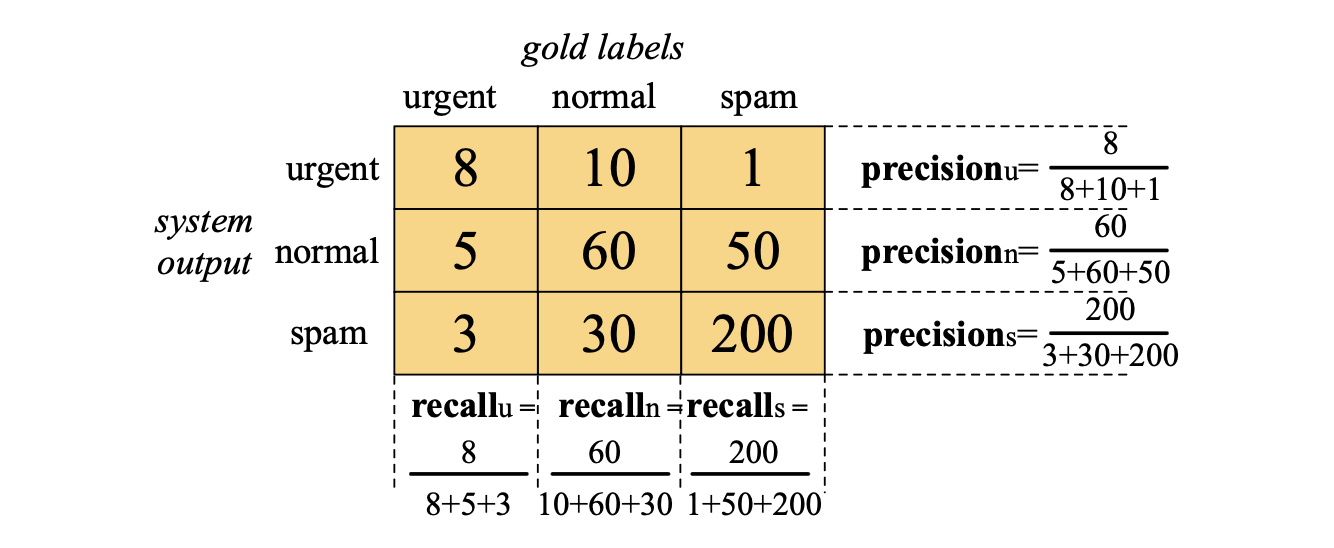
图 4.8 一个三类别分类任务的混淆矩阵,展示了对于每一对类别 $(c_1, c_2)$,有多少原本属于 $c_1$ 的文档被(正确或错误地)分配给了 $c_2$。
不过,我们需要对精确率和召回率的定义稍作调整。 以图 4.8 中所示的一个假设性三类“互斥”(one-of)邮件分类任务(紧急、普通、垃圾邮件)为例。 该混淆矩阵显示,例如,系统将一封垃圾邮件错误地标记为了“紧急”;而我们在前文已展示了如何为每个类别分别计算其对应的精确率和召回率。 为了得到一个能整体衡量系统性能的单一指标,可以用两种方式来合并这些值。 宏平均(Macroaveraging):先为每个类别单独计算性能指标(如精确率、召回率),然后对所有类别的指标取算术平均。 微平均(Microaveraging):将所有类别的预测结果汇总到一个全局混淆矩阵中,再基于这个合并后的矩阵统一计算精确率和召回率。 图 4.9 展示了针对上述三个类别分别构建的混淆矩阵,并演示了微平均和宏平均精确率的计算过程。

图 4.9 针对前图中三个类别的独立混淆矩阵,展示了合并后的全局混淆矩阵,以及微平均与宏平均精确率的计算方式。
如图所示,微平均受高频类别主导(本例中是“垃圾邮件”),因为其计算基于所有样本的总计数。 相比之下,宏平均更能反映低频类别的表现,因此在所有类别同等重要时更为合适。