使用梯度下降的目标是找到最优的权重:即最小化为模型定义的损失函数。 在下面的公式 4.25 中,我们将明确表示交叉熵损失函数 $L_{CE}$ 是权重的函数。 在机器学习中,我们通常将待学习的参数统称为 $\theta$;在逻辑回归中,$\theta = \{\mathbf{w}, b\}$。 因此,目标是找到一组权重,使得损失函数在所有训练样本上的平均值最小:
$$ \hat{\theta} = \underset{\theta}{\mathrm{argmin}} \frac{1}{m} \sum_{i=1}^m L_{CE}( f(x^{(i)};\theta), y^{(i)}) \tag{4.25} $$该如何找到这个(或任何)损失函数的最小值呢? 梯度下降是一种找到函数最小值的方法:找出函数在参数空间 $\theta$ 中哪个方向上升最陡峭,然后朝相反方向移动。 其核心思想是:如果你在峡谷中徒步,想要最快地走到谷底的河流处,可能会环顾四周,找到地面坡度最陡的方向,然后朝着那个方向下坡行走。
对于逻辑回归而言,这个损失函数恰好是凸函数(convex)。 凸函数最多只有一个最小值,不存在会陷入的局部最小值,因此无论从哪个点开始,梯度下降都能保证找到全局最小值。 (相比之下,多层神经网络的损失函数是非凸的,梯度下降在训练神经网络时可能会陷入局部最小值,而永远无法找到全局最优解。)
该算法(以及梯度的概念)是为方向向量设计的,不过我们先考虑一个更简单的可视化场景:假设系统的参数只是一个标量 $w$,如图 4.4 所示。
假设随机初始化 $\mathbf{w}$ 为某个值 $w_1$,并假设损失函数 $L$ 恰好具有图 4.4 所示的形状。 此时,我们需要算法告诉我们,在下一次迭代中,是应该向左移动(使 $w_2$ 小于 $w_1$)还是向右移动(使 $w_2$ 大于 $w_1$),才能到达最小值。
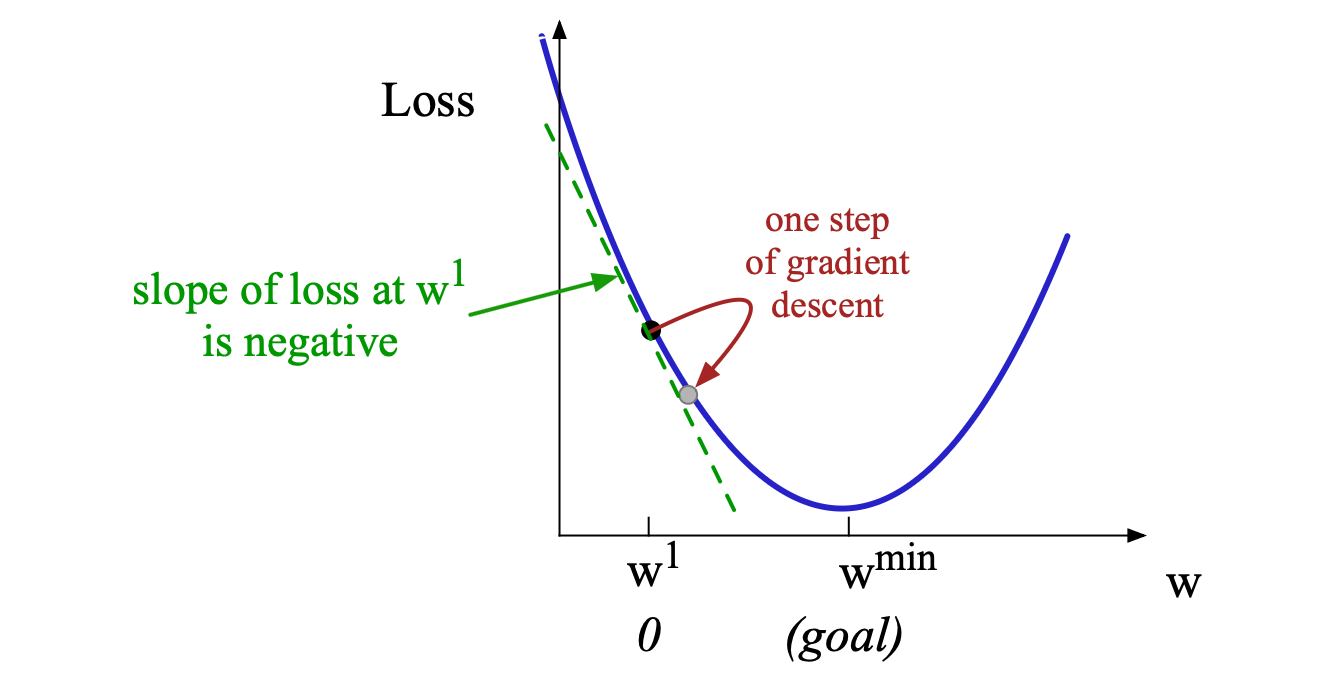
图 4.4 通过迭代找到该损失函数最小值,第一步是沿函数斜率的反方向移动 $\mathbf{w}$。由于斜率为负,需要将 $\mathbf{w}$ 向正方向(右侧)移动。此处上标用于表示学习步骤,因此 $w^1$ 表示 $\mathbf{w}$ 的初始值(即 0),$w^2$ 表示第二步的值,依此类推。
梯度下降算法计算当前点处损失函数的梯度(gradient),并朝其相反方向移动,以此来解决这个问题。 一个多变量函数的梯度是一个向量,指向函数值增长最快的方向。 梯度是斜率在多变量情况下的推广,因此对于像图 4.4 中这样的单变量函数,我们可以非正式地将梯度视为斜率。 图 4.4 中的虚线显示了在点 $\mathbf{w} = w^1$ 处这个假想损失函数的斜率。 可以看到,这条虚线的斜率为负。 因此,为了找到最小值,梯度下降告诉我们应朝相反方向移动:即把 $\mathbf{w}$ 向正方向移动。
在梯度下降中,移动的幅度大小由斜率 $\frac{d}{dw} L(f(x;w),y)$ 的值乘以一个学习率(learning rate)$\eta$ 决定。 较高的(更快的)学习率意味着我们在每一步中对 $\mathbf{w}$ 的调整更大。 对参数的调整量等于学习率乘以梯度(在我们的单变量例子中即斜率):
$$ w^{t+1} = w^{t} - \eta \frac{d}{dw} L( f(x;w), y) \tag{4.26} $$现在,我们将这种思想从单个标量变量 $\mathbf{w}$ 扩展到多个变量的情况。因为我们不仅仅需要决定向左或向右移动,而是需要知道在由 $N$ 个参数构成的 $N$ 维空间(即参数向量 $\theta$ 的空间)中,应该朝哪个方向移动。 梯度正是这样一个向量;它表达了在每个维度上最陡峭坡度的方向分量。 如果只考虑两个权重维度(例如一个权重 $w$ 和一个偏置 $b$),梯度可能是一个包含两个正交分量的向量,每个分量分别告诉我们地面在 $\mathbf{w}$ 维度和 $b$ 维度上的坡度。 图 4.5 展示了在红点处取到的一个二维梯度向量的可视化。
图 4.5 二维空间中($\mathbf{w}$ 和 $b$)红点处梯度向量的可视化,图中红色箭头指向了我们寻找最小值的方向:即梯度的反方向(注意:梯度指向函数值增加的方向,而非减少的方向)。
在实际的逻辑回归中,参数向量 $\mathbf{w}$ 远不止 1 或 2 维,因为输入特征向量 $\mathbf{x}$ 可能很长,我们需要为每个 $x_i$ 设置一个权重 $w_i$。 对于 $\mathbf{w}$(以及偏置 $b$)中的每个维度/变量 $w_i$,梯度都会有一个分量,告诉我们相对于该变量的斜率。 在每个维度 $w_i$ 上,用损失函数对 $w_i$ 的偏导数 $\frac{\partial}{\partial w_i}$ 来表示斜率。 本质上我们是在问:“该变量 $w_i$ 的微小变化会对总损失函数 $L$ 产生多大影响?”
因此,形式上,一个多变量函数 $f$ 的梯度是一个向量,其中每个分量表示 $f$ 对其中一个变量的偏导数。 我们将使用倒置的希腊字母 delta 符号 $\nabla$ 来表示梯度,并将 $\hat{y}$ 表示为 $f(x;\theta)$ 以更清楚地体现其对 $\theta$ 的依赖:
$$ \nabla L( f(x;\theta), y) = \begin{bmatrix} \frac{\partial}{\partial w_1}L(f(x;\theta), y) \\ \frac{\partial}{\partial w_2}L(f(x;\theta), y) \\ \vdots \\ \frac{\partial}{\partial w_n}L(f(x;\theta), y) \\ \frac{\partial}{\partial b}L(f(x;\theta), y) \end{bmatrix} \tag{4.27} $$因此,基于梯度更新 $\theta$ 的最终方程为:
$$ \theta^{t+1} = \theta^t - \eta \nabla L(f(x;\theta), y) \tag{4.28} $$4.7.1 逻辑回归的梯度
为了更新参数 $\theta$,我们需要定义梯度 $\nabla L(f(x;\theta), y)$。 回顾一下,对于逻辑回归,交叉熵损失函数为:
$$ L_{CE}(\hat{y}, y) = -[y \log \sigma(\mathbf{w} \cdot \mathbf{x} + b) + (1 - y) \log(1 - \sigma(\mathbf{w} \cdot \mathbf{x} + b))] \tag{4.29} $$事实证明,对于一个样本向量 $x$,该函数的导数为公式 4.30(感兴趣的读者可参见第 4.15节,了解该公式的推导过程):
$$ \begin{align*} \frac{\partial L_{CE}(\hat{y}, y)}{\partial w_j} &= [\sigma(\mathbf{w} \cdot \mathbf{x} + b) - y] x_j \\ &= (\hat{y} - y) x_j \tag{4.30} \end{align*} $$你有时也会看到这个公式的等价形式:
$$ \frac{\partial L_{CE}(\hat{y}, y)}{\partial w_j} = -(y - \hat{y}) x_j \tag{4.31} $$请注意,在这些公式中,关于单个权重 $w_j$ 的梯度代表了一个非常直观的值:即该观测样本的真实标签 $y$ 与我们的估计值 $\hat{y} = \sigma(\mathbf{w} \cdot \mathbf{x} + b)$ 之间的差值,再乘以对应的输入值 $x_j$。
4.7 .2 随机梯度下降算法
随机梯度下降(Stochastic Gradient Descent, SGD)是一种在线算法,它在训练每个样本后,计算损失函数的梯度,将参数 $\theta$ 向正确方向(即梯度的反方向)微调,来最小化损失函数。 (“在线算法”是指逐个处理输入样本,而不是等到看到全部输入后再进行处理。) 随机梯度下降之所以被称为随机,是因为它每次只选择一个随机样本进行处理;在第 4.7.4 节中,我们将讨论梯度下降的其他版本,可以一次批量处理多个样本的。 图 4.6 展示了该算法。
function STOCHASTIC GRADIENT DESCENT (L(), f(), x, y) returns \theta
# 其中:L 是损失函数
# f 是一个由参数 \theta 参数化的函数
# x 是训练输入集合 $x^{(1)}$, $x^{(2)}$, ..., $x^{(m)}$
# y 是训练输出(标签)集合 $y^{(1)}$, $y^{(2)}$, ..., $y^{(m)}$
θ ← 0 # (或小的随机值)
重复直到完成 # 见下方说明
对于每个训练样本 ($x^{(i)}$, $y^{(i)}$) (按随机顺序)
1. 可选(用于报告): # 当前样本的表现如何?
计算 $\hat{y}(i)$ = $f(x(i);\theta)$ # 我们的估计输出 $\hat{y}$ 是多少?
计算损失 $L(\hat{y}(i),y(i))$ # $\hat{y}^{(i)}$ 与真实输出 $y^{(i)}$ 相差多远?
2. g ← $∇_θ L(f(x^{(i)};\theta),y(i))$ # 我们应该如何移动 θ 来最大化损失?
3. θ ← θ − η g # 改为朝相反方向移动
返回 θ
图 4.6 随机梯度下降算法。 第 1 步(计算损失)主要用于报告当前元祖上的表现;计算梯度时并不需要先计算损失。 该算法可以在收敛时终止(当梯度的范数小于某个小值 $\epsilon$ 时),或在进展停滞时终止(例如,在一个预留集合上损失值开始上升)。 对于逻辑回归,权重通常初始化为0;而对于神经网络,则初始化为小的随机值,我们将在第 6 章中看到这一点。
学习率 $\eta$ 是一个必须调整的超参数(hyperparameter)。 如果它太大,学习过程的步长会过大,导致越过损失函数的最小值;如果它太小,学习过程的步长会过小,导致到达最小值所需的时间过长。 通常的做法是开始时使用较高的学习率,然后逐渐降低,使其成为训练迭代次数 $k$ 的函数;符号 $\eta_k$ 可以表示在第 $k$ 次迭代时的学习率值。
我们将在第 6 章更详细地讨论超参数,但简而言之,它们是任何机器学习模型的一种特殊参数。 与模型的常规参数(如权重 $w$ 和偏置 $b$)不同,常规参数是由算法从训练集中学习得到的,而超参数是由算法设计者选择的,它们影响着算法的工作方式。
5.6.3 通过一个例子来理解
我们逐步走一遍梯度下降算法的单次更新过程。 我们将使用图 4.2 中例子的简化版本,该例子只处理一个样本 $x$,其正确标签为 $y = 1$(这是一个正面评价),其特征向量为 $x = [x_1, x_2]$,包含以下两个特征:
$$ \begin{align*} x_1 &= 3 \quad \text{(正面词汇词典词的计数)} \\ x_2 &= 2 \quad \text{(负面词汇词典词的计数)} \end{align*} $$假设初始权重和偏置 $\theta^0$ 均设置为 0,初始学习率 $\eta$ 为0.1:
$$ \begin{align*} w_1 = w_2 = b &= 0 \\ \eta &= 0.1 \end{align*} $$单次更新步骤要求我们计算梯度,再乘以学习率:
$$ \theta^{t+1} = \theta^t - \eta \nabla_\theta L(f(x^{(i)};\theta), y^{(i)}) $$在这个小例子中,共有三个参数,因此梯度向量有三个维度,分别对应 $w_1$、$w_2$ 和 $b$。我们可以计算第一个梯度如下:
$$ \begin{align*} \nabla_{w,b}L &= \begin{bmatrix} \frac{\partial L_{CE}(\hat{y}, y)}{\partial w_1} \\ \frac{\partial L_{CE}(\hat{y}, y)}{\partial w_2} \\ \frac{\partial L_{CE}(\hat{y}, y)}{\partial b} \end{bmatrix} \\ &= \begin{bmatrix} (\sigma(\mathbf{w} \cdot \mathbf{x} + b) - y)x_1 \\ (\sigma(\mathbf{w} \cdot \mathbf{x} + b) - y)x_2 \\ \sigma(\mathbf{w} \cdot \mathbf{x} + b) - y \end{bmatrix} \\ &= \begin{bmatrix} (\sigma(0) - 1) \cdot 3 \\ (\sigma(0) - 1) \cdot 2 \\ \sigma(0) - 1 \end{bmatrix} \\ &= \begin{bmatrix} -0.5 \cdot 3 \\ -0.5 \cdot 2 \\ -0.5 \end{bmatrix} \\ &= \begin{bmatrix} -1.5 \\ -1.0 \\ -0.5 \end{bmatrix} \end{align*} $$现在我们得到了梯度,将 $\theta^0$ 沿梯度的反方向移动,计算出新的参数向量 $\theta^1$:
$$ \theta^1 = \begin{bmatrix} w_1 \\ w_2 \\ b \end{bmatrix} - \eta \begin{bmatrix} -1.5 \\ -1.0 \\ -0.5 \end{bmatrix} = \begin{bmatrix} 0.15 \\ 0.10 \\ 0.05 \end{bmatrix} $$因此,在一次梯度下降更新后,权重更新为:$w_1 = 0.15$,$w_2 = 0.10$,$b = 0.05$。
请注意,这个样本 $x$ 恰好是一个正面例子。 我们可以预期,在看到更多负面词计数较高的负面例子后,权重 $w_2$ 会向负值方向调整。
4.7.4 小批量训练
随机梯度下降被称为“随机”,是因为它每次只选择一个随机样本,调整权重以提升模型在该单个样本上的表现。 这种方式可能导致参数更新路径非常不稳定,因此,通常的做法是计算一个批次(batch)训练实例上的梯度,而不是单个实例的梯度,以获得更平滑的更新。
例如,在批量训练(batch training)中,我们会在整个数据集上计算梯度。 通过观察大量样本,批量训练能够提供一个非常精确的权重更新方向估计,但代价是需要花费大量时间处理训练集中的每一个样本,才能计算出这个“完美”的方向。
一种折中的方案是小批量训练(mini-batch training):在一个包含 $m$ 个样本的组(例如 512 或 1024 个)上进行训练,这个 $m$ 小于整个数据集的大小。 (如果 $m$ 等于数据集的大小,那么就是在进行批量梯度下降;如果 $m = 1$,则又回到了随机梯度下降。) 小批量训练还有一个优势是计算效率高。 小批量可以很容易地进行向量化处理,并且可以根据计算资源来选择小批量的大小。 这使得我们能够并行处理一个小批量中的所有样本,然后累积损失,而这是单个样本处理或全批量训练无法实现的。
只需要定义第 4.6 节中交叉熵损失函数和第 4.7.1 节中梯度的小批量版本即可。 将公式 4.23 中针对单个样本的交叉熵损失扩展到大小为 $m$ 的小批量上。 继续使用符号 $x^{(i)}$ 和 $y^{(i)}$ 分别表示第 $i$ 个训练样本的特征和标签。 我们假设训练样本是相互独立的:
$$ \begin{align*} \log p(\text{训练标签}) &= \log \prod_{i=1}^m p(y^{(i)}|x^{(i)}) \\ &= \sum_{i=1}^m \log p(y^{(i)}|x^{(i)}) \\ &= -\sum_{i=1}^m L_{CE}(\hat{y}^{(i)}, y^{(i)}) \tag{4.32} \end{align*} $$现在,大小为 $m$ 的小批量的代价函数是每个样本损失的平均值:
$$ \begin{align*} \text{Cost}(\hat{y}, y) &= \frac{1}{m} \sum_{i=1}^m L_{CE}(\hat{y}^{(i)}, y^{(i)}) \\ &= -\frac{1}{m} \sum_{i=1}^m \left[ y^{(i)} \log \sigma(\mathbf{w} \cdot \mathbf{x}^{(i)} + b) + (1 - y^{(i)}) \log(1 - \sigma(\mathbf{w} \cdot \mathbf{x}^{(i)} + b)) \right] \tag{4.33} \end{align*} $$小批量梯度是公式 (5.30) 中各个样本梯度的平均值:
$$ \frac{\partial \text{Cost}(\hat{y}, y)}{\partial w_j} = \frac{1}{m} \sum_{i=1}^m [\sigma(\mathbf{w} \cdot \mathbf{x}^{(i)} + b) - y^{(i)}] x_j^{(i)} \tag{4.34} $$除了使用求和符号,还可以遵循第 69 页所介绍的向量化方法,更高效地以矩阵形式计算梯度。其中,我们有一个大小为 $[m \times f]$ 的矩阵 $\mathbf{X}$,表示批次中的 $m$ 个输入,以及一个大小为 $[m \times 1]$ 的向量 $\mathbf{y}$,表示正确的输出:
$$ \begin{align*} \frac{\partial \text{Cost}(\hat{y}, y)}{\partial \mathbf{w}} &= \frac{1}{m} (\hat{\mathbf{y}} - \mathbf{y})^T \mathbf{X} \\ &= \frac{1}{m} (\sigma(\mathbf{Xw} + \mathbf{b}) - \mathbf{y})^T \mathbf{X} \tag{4.35} \end{align*} $$