有时我们需要处理超过两个类别的分类问题。 例如,可能需要进行三类情感分类(正面、负面或中性)。 或者,可能会分配第 17 章将要介绍的一些标签,比如一个词的词性(从 10个、30 个甚至 50 个不同的词性中选择),或一个短语的命名实体类型(从“人名”、“地点”、“组织”等标签中选择)。 或者在大语言模型中,词汇表中 |V| 个词,预测下一个词其中的哪一个,这就是 |V| 分类。
在这种情况下,使用多项逻辑回归(multinomial logistic regression),也被称为Softmax回归(在早期的NLP文献中,有时会看到它被称为最大熵分类器,maxent classifier)。 在多项逻辑回归中,我们希望将每个观测样本标记为 $K$ 个类别中的某一个 $k$,并规定只有一个类别是正确的(有时称为硬分类;一个观测样本不能同时属于多个类别)。 我们采用以下表示方式:每个输入 $\mathbf{x}$ 的输出 $\mathbf{y}$ 将是一个长度为 $K$ 的向量。 如果类别 $c$ 是正确的类别,我们将 $y_c$ 设为1,并将 $\mathbf{y}$ 的所有其他元素设为0,即 $y_c = 1$ 且 $y_j = 0 \quad \forall j \neq c$。 像这样的向量 $\mathbf{y}$(只有一个值为1,其余为0)被称为独热向量(one-hot vector)。 分类器的任务是生成一个估计向量 $\hat{\mathbf{y}}$。 对于每个类别 $k$,值 $\hat{y}_k$ 将是分类器对概率 $p(y_k = 1|\mathbf{x})$ 的估计。
5.3.1 Softmax函数
多项逻辑分类器使用 Sigmoid 函数的一个推广版本,称为Softmax函数,来计算 $p(y_k = 1|\mathbf{x})$。 Softmax函数接收一个包含 $K$ 个任意值的向量 $\mathbf{z} = [z_1, z_2, ..., z_K]$,并将其映射为一个概率分布,其中每个值都在 $[0,1]$ 范围内,且所有值的总和为1。 与Sigmoid函数一样,它也是一种指数函数。
对于一个维度为 $K$ 的向量 $\mathbf{z}$,Softmax函数定义如下:
$$ \mathrm{softmax}(z_i) = \frac{\exp(z_i)}{\sum_{j=1}^K \exp(z_j)} \quad 1 \leq i \leq K \tag{4.16} $$因此,输入向量 $\mathbf{z} = [z_1, z_2, \cdots, z_K]$ 的Softmax结果本身也是一个向量:
$$ \mathrm{softmax}(\mathbf{z}) = \left[\frac{\exp(z_1)}{\sum_{i=1}^K \exp(z_i)}, \frac{\exp(z_2)}{\sum_{i=1}^K \exp(z_i)}, \cdots, \frac{\exp(z_K)}{\sum_{i=1}^K \exp(z_i)}\right] \tag{4.17} $$分母 $\sum_{i=1}^K \exp(z_i)$ 用于将所有值归一化为概率。 例如,给定向量:
$$ \mathbf{z} = [0.6, 1.1, -1.5, 1.2, 3.2, -1.1] $$其对应的(四舍五入后的)Softmax($\mathbf{z}$) 结果为:
$$ [0.05, 0.09, 0.01, 0.10, 0.74, 0.01] $$与 Sigmoid 函数类似,Softmax 函数也具有将极端值压缩至0或1的特性。 因此,如果其中一个输入值远大于其他输入值,Softmax 会倾向于将其概率推高至接近1,同时抑制较小输入值的概率。
最后,请注意,得分向量 $\mathbf{z}$ 是 softmax 函数的输入。与 Sigmoid 函数的情况类似,我们将 $\mathbf{z}$ 称为 logits(参见公式 4.7)。
4.4.2 在逻辑回归中应用 Softmax
当我们将 Softmax 应用于逻辑回归时,其输入(与 Sigmoid 函数类似)将是权重向量 $\mathbf{w}$ 与输入向量 $\mathbf{x}$ 的点积(再加上一个偏置项)。 但现在,我们需要为 $K$ 个类别中的每一个都设置独立的权重向量 $\mathbf{w}_k$ 和偏置项 $b_k$。 因此,每个输出类别 $\hat{y}_k$ 的概率可以计算如下:
$$ p(y_k = 1|\mathbf{x}) = \frac{\exp(\mathbf{w}_k \cdot \mathbf{x} + b_k)}{\sum_{j=1}^K \exp(\mathbf{w}_j \cdot \mathbf{x} + b_j)} \tag{4.18} $$公式 4.18 的形式似乎暗示我们需要分别计算每个输出。 然而,为了更高效地利用现代向量化硬件进行计算,我们通常会以另一种方式构建方程。 为此,我们将 $K$ 个权重向量表示为一个权重矩阵 $\mathbf{W}$,并将偏置项表示为一个偏置向量 $\mathbf{b}$。 $\mathbf{W}$ 的每一行 $k$ 对应于权重向量 $\mathbf{w}_k$。 因此,$\mathbf{W}$ 的形状为 $[K \times f]$,其中 $K$ 是输出类别的数量,$f$ 是输入特征的数量。 偏置向量 $\mathbf{b}$ 则包含 $K$ 个输出类别各自的偏置值。 以这种方式表示权重后,我们可以用一个简洁的公式一次性计算出 $\hat{\mathbf{y}}$,即所有 $K$ 个类别的输出概率向量:
$$ \hat{\mathbf{y}} = \mathrm{softmax}(\mathbf{Wx} + \mathbf{b}) \tag{4.19} $$如果你仔细推导一下矩阵运算过程,就会发现第一个输出类别 $\hat{y}_1$ 的估计得分(在应用 Softmax 之前)确实等于 $\mathbf{w}_1 \cdot \mathbf{x} + b_1$。
一种有助于解读权重矩阵 $W$ 的方式是,当每一行 $w_k$ 当作类别 $k$ 的原型(prototype)。 学习到权重向量 $w_k$ 把类别表示为一种模版。 由于两个相似度高的向量,它们的点积结果更高,点积相当于相似度函数。 因此,逻辑斯谛回归学习了每一类别的典型表示,结果在 $K$ 个类别中,输入的向量被赋予与其最相似的类别 $k$。
对权重矩阵 $\mathbf{W}$ 的一种有益理解是:将每一行 $\mathbf{w}_k$ 视为类别 $k$ 的一个原型(prototype)。 所学习到的权重向量 $\mathbf{w}_k$ 以某种模板的形式表征该类别。 由于两个向量越相似,它们的点积就越大,因此点积可充当一种相似度函数。 由此,逻辑回归实际上是在为每个类别学习一个范例式(exemplar)表示,使得输入向量被分配给 $K$ 个类别中与其最相似的那个类别 $k$(Doumbouya et al., 2025)。
图 4.3 直观地展示了在二元逻辑回归和多项逻辑回归中,权重向量与权重矩阵在计算输出类别概率时所起的不同作用。
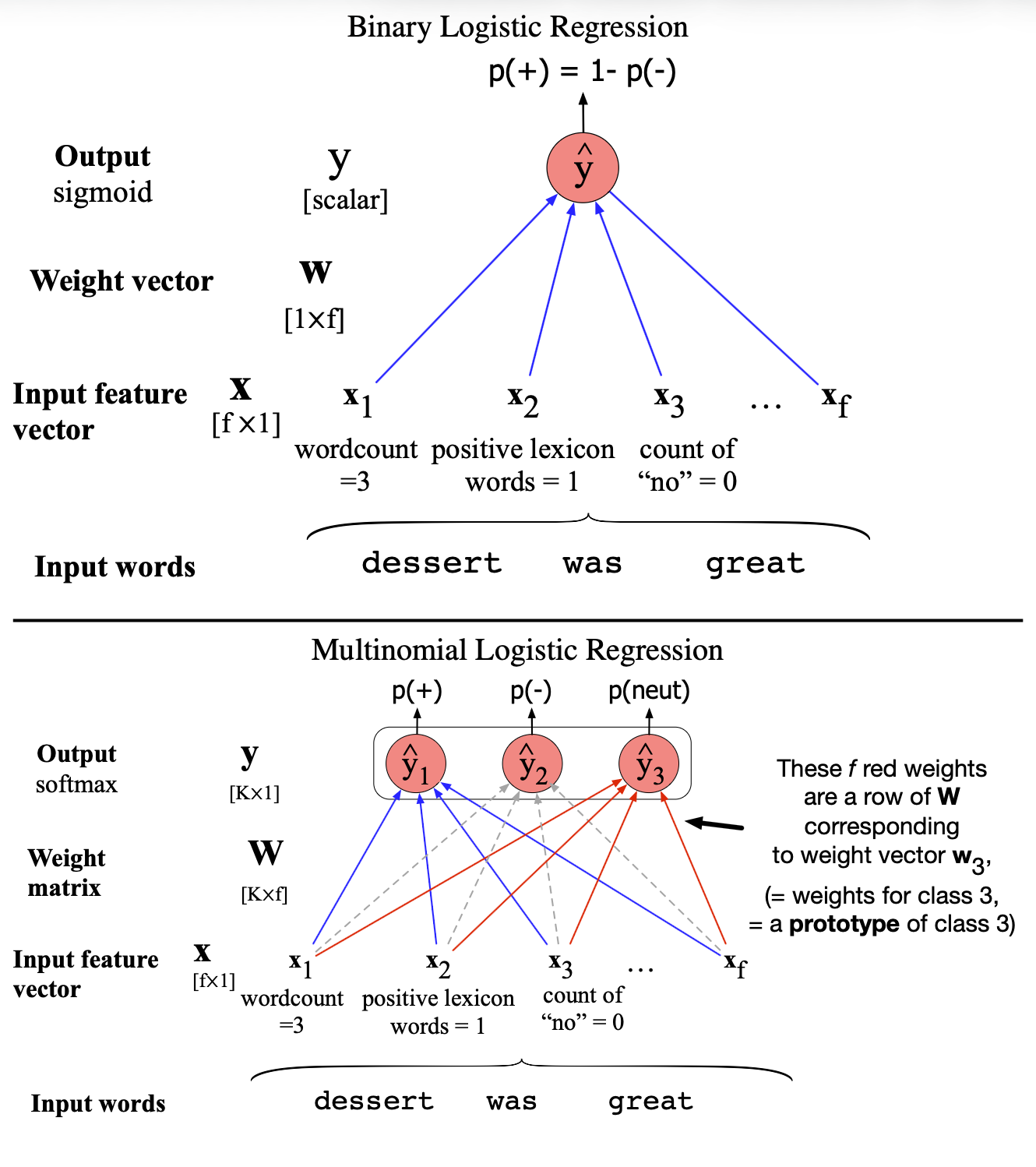
图 4.3 二元逻辑回归与多项逻辑回归的对比。二元逻辑回归使用单个权重向量 $\mathbf{w}$,输出为标量 $\hat{y}$。在多项逻辑回归中,有 $K$ 个分别对应 $K$ 个类别的独立权重向量,它们被整合进一个权重矩阵 $\mathbf{W}$ 中,输出为向量 $\hat{\mathbf{y}}$。为清晰起见,图中省略了偏置项。
4.4.3 多项逻辑回归中的特征
多项逻辑回归中的特征与二元逻辑回归中的特征作用类似,唯一的区别是如上所述,我们需要为 $K$ 个类别中的每一个都设置独立的权重向量和偏置项。回顾第 66 页提到的二元分类中的感叹号特征 $x_5$:
$$ x_5 = \begin{cases} 1 & \text{if “!” } \in \text{doc} \\ 0 & \text{otherwise} \end{cases} $$在二元分类中,某个特征上的正权重 $w_5$ 会促使分类器倾向于将样本判为 $y = 1$(正面情感),而负权重则会使其倾向于 $y = 0$(负面情感),其绝对值大小表示该特征的重要性。 而在多项逻辑回归中,由于每个类别都有独立的权重,因此一个特征可能对某个类别是支持证据,而对另一个类别则是反对证据。
例如,在三类情感分类任务中,我们需要将每篇文档分配到三个类别之一:+(正面)、−(负面)或 0(中性)。 此时,与感叹号相关的特征可能对“中性”类别具有负权重,而对“正面”或“负面”类别具有正权重:
| 特征 | 定义 | $w_{5,+}$ | $w_{5,-}$ | $w_{5,0}$ |
|---|---|---|---|---|
| $f_5(x)$ | $\begin{cases} 1 & \text{if “!” } \in \text{doc} \\ 0 & \text{otherwise} \end{cases}$ | 3.5 | 3.1 | -5.3 |
由于这些特征权重同时依赖于输入文本和输出类别,我们有时会明确表示这种依赖关系,将特征本身写成 $f(x, y)$:即输入和类别的函数。 使用这种记法,上面的 $f_5(x)$ 可以表示为三个特征:$f_5(x,+)$、$f_5(x,−)$ 和 $f_5(x,0)$,每个特征对应一个单一的权重。 我们将在第 17 章描述条件随机场(CRF)时使用这种记法。