二元逻辑回归的目标是训练一个分类器,使其能够对新输入样本的类别做出二元判断。 本节我们将介绍Sigmoid分类器,它将帮助我们完成这一决策。
考虑一个输入样本 $x$,我们将其表示为一个特征向量 $[x_1, x_2, ..., x_n]$。 (下一小节将展示具体的特征示例。) 分类器的输出 $y$ 可以是 1(表示该样本属于该类别)或 0(表示不属于该类别)。 我们希望知道该样本属于该类别的概率 $P(y = 1|x)$。 例如,这个决策可能是“正面情感”与“负面情感”的区分,特征代表文档中词的出现次数,$P(y = 1|x)$ 表示文档具有正面情感的概率,而 $P(y = 0|x)$ 表示文档具有负面情感的概率。
逻辑回归解决该任务的方法是从训练集中学习一个权重向量和一个偏置项(bias term)。 每个权重 $w_i$ 是一个实数,与输入特征 $x_i$ 相关联。 权重 $w_i$ 表示该输入特征对分类决策的重要性,其值可以为正(为样本属于正类提供证据),也可以为负(为样本属于负类提供证据)。 因此,在情感分析任务中,我们可能会预期单词 awesome 具有很高的正值权重,而 abysmal 则具有非常低的负值权重。 偏置项(也称为截距项,intercept)是另一个实数,会被加到加权后的输入中。
在训练中学习到权重后,要在测试样本上做出决策,分类器首先将每个 $x_i$ 与其对应的权重 $w_i$ 相乘,对所有加权特征求和,并加上偏置项 $b$。 得到的单个数值 $z$ 表示支持该类别的加权证据总和:
$$ z = \left( \sum_{i=1}^n w_i x_i \right) + b \tag{4.2} $$在本书其余部分,我们将使用线性代数中的**点积(dot product)**符号来表示此类求和。 两个向量 $a$ 和 $b$ 的点积记作 $a \cdot b$,是它们对应元素乘积之和。(注意:我们用粗体 $\mathbf{b}$ 表示向量。) 因此,以下表达式与公式 4.1 等价:
$$ z = \mathbf{w} \cdot \mathbf{x} + b \tag{4.3} $$但请注意,公式 4.3 中没有任何机制强制 $z$ 成为一个合法的概率值,即落在 0 到 1 之间。 事实上,由于权重是实数,输出甚至可能为负;$z$ 的取值范围是从 $-\infty$ 到 $\infty$。
为了生成一个概率值,我们将 $z$ 输入Sigmoid函数 $\sigma(z)$。 Sigmoid函数(因其形状像字母“s”而得名)也被称为Logistic函数,逻辑回归也因此得名。 Sigmoid函数的数学表达式如下,其图形如图 4.1 所示:
$$ \sigma(z) = \frac{1}{1 + e^{-z}} = \frac{1}{1 + \exp(-z)} \tag{4.4} $$(在本书后续内容中,我们将使用 $\exp(x)$ 表示 $e^x$。) Sigmoid函数具有多个优点:它将一个实数值映射到 (0,1) 区间内,这正是我们对概率值的要求。 因为它在 0 附近近似线性,而在两端趋于平坦,所以能将异常值压缩到接近 0 或 1。 此外,它是可微的,这一点将在第 4.15 节中对模型学习过程起到重要作用。
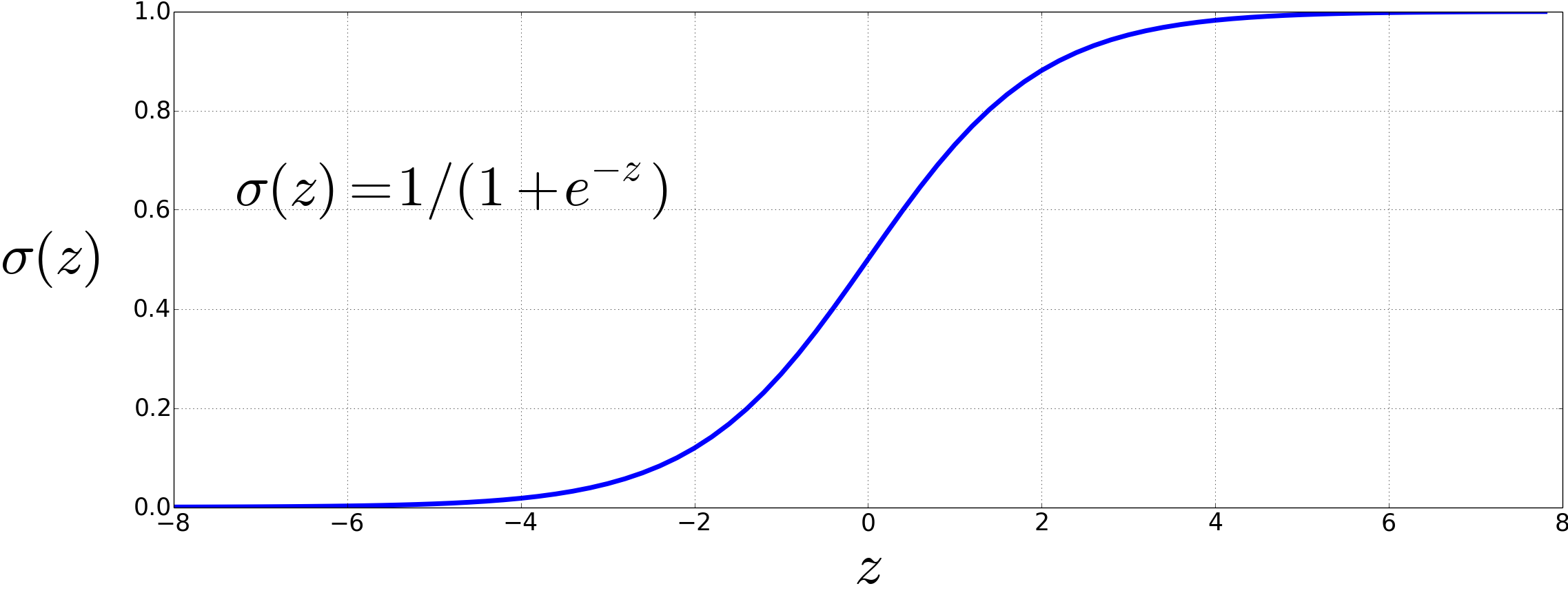
图 4.1 Sigmoid函数 $\sigma(z) = \frac{1}{1+e^{-z}}$ 将一个实数值映射到区间 (0,1) 内。它在 0 附近接近线性,但极端值会被压缩至 0 或 1。
我们几乎完成了整个过程。 如果将 Sigmoid 函数应用于加权特征的总和,就会得到一个介于 0 和 1 之间的数值。 为了让它成为一个真正的概率分布,我们只需确保两种情况的概率之和为1,即 $P(y=1) + P(y=0) = 1$。 我们可以按如下方式实现:
$$ \begin{align*} P(y = 1) &= \sigma(\mathbf{w} \cdot \mathbf{x} + b) \\ &= \frac{1}{1 + \exp(-(\mathbf{w} \cdot \mathbf{x} + b))} \\ \\ P(y = 0) &= 1 - \sigma(\mathbf{w} \cdot \mathbf{x} + b) \\ &= 1 - \frac{1}{1 + \exp(-(\mathbf{w} \cdot \mathbf{x} + b))} \\ &= \frac{\exp(-(\mathbf{w} \cdot \mathbf{x} + b))}{1 + \exp(-(\mathbf{w} \cdot \mathbf{x} + b))} \tag{4.5} \end{align*} $$Sigmoid函数具有以下性质:
$$ 1 - \sigma(x) = \sigma(-x) \tag{4.6} $$因此,我们也可以将 $P(y = 0)$ 表达为 $\sigma(-(\mathbf{w} \cdot \mathbf{x} + b))$。
最后,补充一个术语说明。 Sigmoid函数的输入,即公式 (4.3) 中的得分 $z = \mathbf{w} \cdot \mathbf{x} + b$,通常被称为 logit。 这是因为 logit 函数是 Sigmoid 函数的逆函数。 logit 函数定义为几率比(odds ratio)$\frac{p}{1-p}$ 的对数:
$$ \mathrm{logit}(p) = \sigma^{-1}(p) = \ln\frac{p}{1 - p} \tag{4.7} $$将 $z$ 称为 logit,是在提醒我们:通过使用Sigmoid函数将 $z$(取值范围为 $-\infty$ 到 $\infty$)转换为概率,我们实际上隐含地将 $z$ 解释为不仅仅是任意实数,而是特定的对数几率(log odds)。