可视化语言模型所包含知识的一种重要方式是从模型中采样。 所谓从一个分布中采样,就是按照每个结果出现的可能性大小来随机选择结果。 因此,从语言模型中采样——该模型本质上是对句子分布的一种表示——意味着生成一些句子,模型定义的概率选择每个句子。 也就是说,更容易生成模型认为概率较高的句子,而更难生成模型认为概率较低的句子。
通过采样来可视化语言模型的思想最早由 Shannon(1948)以及 Miller 和 Selfridge(1950)提出。
从 unigram 入手来可视化其工作原理,是最容易理解的。
想象英语中的所有词排列在 0 到 1 的数轴上,每个词占据的区间长度与其出现频率成正比。
图 3.3 展示了一个可视化示例,它使用的是根据本书文本训练出的 unigram 模型。
我们随机选择一个介于 0 和 1 之间的数值,在概率线上找到对应的位置,输出该数值落在哪个词的区间内。
不断重复地选择随机数字来生成词,直到随机生成句子结束标记 </s>,此时句子生成结束。
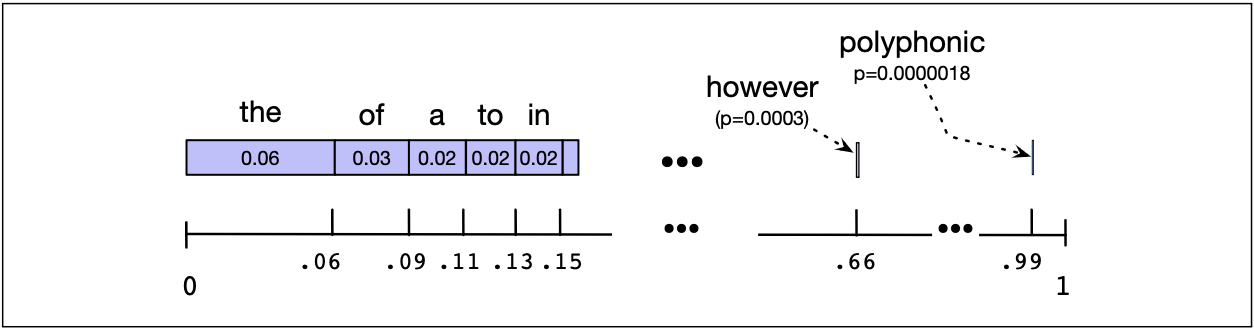
图 3.3 展示了通过不断采样 unigram 来生成句子时的采样分布。 蓝色条形图表示每个词的相对频率(按从高频到低频的顺序排列,但顺序本身是任意的)。 数轴显示了累积概率。如果随机选择一个介于 0 和 1 之间的数字,它会落在某个词所对应的区间内。 我们更有可能随机选中高频词(如 the、of、a)所对应的较大区间,而不太可能选中低频词(如 polyphonic)所对应的小区间。
也可以用同样的方法生成 bigram 句子。首先根据起始标记 <s> 出现的bigram 概率,随机生成一个以 <s> 开头的 bigram。
假设选中的 bigram 第二个词是 $w$,那么下一步就根据以 $w$ 开头的所有 bigram 的概率,再次随机选择下一个词,依此类推,直到生成句子结束标记 </s> 为止。