我们经常需要一种方法来衡量两个单词或字符串之间的相似程度。 正如在后续章节中将看到的,这种需求最常出现在自动语音识别或机器翻译等任务中。在这些场景下,我们需要评估一个词序列与某个参考词序列的相似程度。
编辑距离(edit distance)提供了一种方法,来量化上述关于字符串相似性的合理判断。 更正式地说,两个字符串之间的最小编辑距离(minimum edit distance)被定义为将一个字符串转换为另一个字符串所需的最少编辑操作次数(如插入、删除、替换等操作)。 本节中,我们讲介绍单个词的编辑距离,但是该算法同样适用于整个字符串。
例如,“intention”与“execution”之间的差距为 5(删除一个 i,将 n 替换为 e,将 t 替换为 x,插入 c,将 n 替换为 u)。
为了更直观地理解这一点,可以观察字符串距离最重要的可视化方式:两个字符串之间的对齐(alignment),如图 2.16 所示。
给定两个序列,对齐指的是两个序列子串之间的一种对应关系。
因此,我们说 I 与空字符串对齐,N 与 E 对齐,依此类推。
在对齐的字符串下方是另一种表示方式:一系列符号,表示将上方字符串转换为下方字符串的操作列表:d 表示删除(deletion),s 表示替换(substitution),i 表示插入(insertion)。
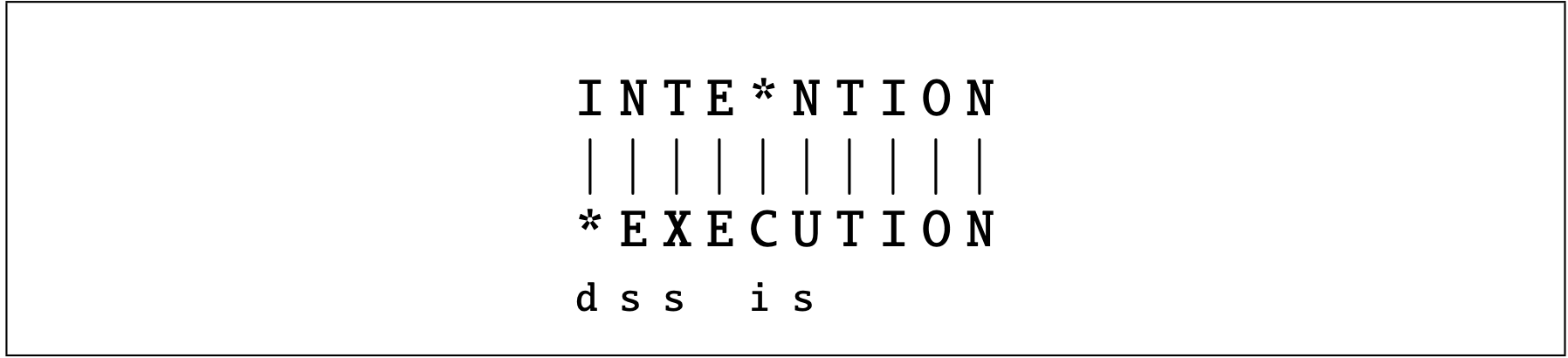
图 2.16 将两个字符串之间的最小编辑距离表示为对齐。最后一行给出了将上方字符串转换为下方字符串的操作列表:d 表示删除,s 表示替换,i 表示插入。
我们也可以为每种操作赋予特定的成本或权重。
两个序列之间的莱文斯坦距离(Levenshtein distance)是最简单的加权方式,其中三种操作的代价均为 1(Levenshtein, 1966),我们假设一个字母替换自身(例如t替换t)的代价为 0。
“intention”与“execution”之间的莱文斯坦距离为 5。
莱文斯坦还提出了该度量的一种替代版本,其中每次插入或删除的代价为 1,且不允许替换操作(这等价于允许替换,但将每次替换的代价设为 2,因为任何替换操作都可以用一次插入和一次删除来表示)。
使用此版本,“intention”与“execution”之间的莱文斯坦距离为8。
2.9.1 最小编辑距离算法
如何找到最小编辑距离?可以将其视为一个搜索任务,即在从一个字符串转换到另一个字符串的所有可能编辑路径中,寻找最短路径(即编辑操作序列)。

图 2.17 将编辑距离求解视为一个搜索问题
所有可能的编辑路径构成的空间极为庞大,因此无法进行穷举式搜索。 然而,许多不同的编辑路径最终会到达相同的状态(即相同的字符串)。 为了避免重复计算这些路径,可以在每次遇到某个状态时,只记录到达该状态的最短路径。 实现这一目标的方法是使用动态规划(dynamic programming)。 动态规划是一类算法的统称,由 Bellman(1957)首次提出,其核心思想是采用表格驱动的方式,通过组合子问题的解来求解整体问题。 自然语言处理中最常用的若干算法都基于动态规划,例如维特比算法(Viterbi algorithm,见第17章)和用于句法分析的CKY算法(第18章)。
动态规划问题的核心思想是:一个大问题的最优解可以通过恰当地组合其各个子问题的最优解来获得。 考虑图 2.18 所示变换的词的最短路径,它们代表了字符串 intention 到 execution 之间的的最小编辑距离。

图 2.18 从 intention 到 execution 的路径。
假设某个字符串(例如 exention)在该最优路径是上(不考虑这个路径是什么样)。 动态规划的核心思想是:如果 exention 位于最优操作列表中,那么该最优序列也必然包含从 intention 到 exention 的最优路径。 为什么?因为如果存在一条从 intention 到 exention 的更短路径,我们就可以用它来替代原路径中的对应部分,从而得到一条更短的整体路径,这与“原路径是最优的”这一前提矛盾。
最小编辑距离算法由 Wagner 和 Fischer(1974)正式命名,但此前已被多人独立发现(详见第17章的历史注记部分)。
我们首先定义两个字符串之间的最小编辑距离。
给定源字符串 X,长度为 n,目标字符串 Y,长度为 m,定义 D[i,j] 为子串 X[1..i](即 X 的前 i 个字符)与 Y[1..j](即 Y 的前 j 个字符)之间的编辑距离。
因此,X 与 Y 之间的编辑距离即为 D[n,m]。
我们将采用动态规划自底向上地计算 D[n,m],通过组合子问题的解来逐步求解。
当目标字符串为空时,若源字符串长度为 i,则需执行 i 次删除操作才能将其变为空。
若目标子串长度为 j,而源子串为空,则从 0 个字符变为 j 个字符需要 j 次插入操作。
在计算出较小 i 和 j 对应的 D[i,j] 后,我们再基于这些已计算出的较小值,逐步计算更大的 D[i,j]。
D[i,j] 的值通过取以下三种可能路径的最小值得到:
前文提到了两种版本的莱文斯坦距离:一种是替换操作代价为 1,另一种是替换操作代价为 2(即等价于一次插入加一次删除)。
此处我们采用第二种版本的莱文斯坦距离,即插入和删除操作的代价均为 1(ins-cost(·) = del-cost(·) = 1),而替换操作的代价为 2(但相同字母之间的替换代价为0)。
在此设定下,D[i,j] 的计算公式变为:
图 2.19 总结了该算法;图 2.20 展示了使用公式 (2.20) 所示的莱文斯坦距离版本,计算 intention 与 execution 之间距离的结果。
function MIN-EDIT-DISTANCE (source, target) returns min-distance
n ← 源字符串的长度
m ← 目标字符串的长度
创建一个距离矩阵 D[n+1, m+1]
# 初始化:第0行和第0列表示从空字符串出发的距离
D[0,0] = 0
对每一行 i 从 1 到 n 执行
D[i,0] ← D[i-1,0] + 删除代价(源字符串[i])
对每一列 j 从 1 到 m 执行
D[0,j] ← D[0, j-1] + 插入代价(目标字符串[j])
# 递推关系:
对每一行 i 从 1 到 n 执行
对每一列 j 从 1 到 m 执行
D[i, j] ← MIN( D[i−1, j] + 删除代价(源字符串[i]),
D[i−1, j−1] + 替换代价(源字符串[i], 目标字符串[j]),
D[i, j−1] + 插入代价(目标字符串[j]))
# 终止
返回 D[n,m]
图 2.19 最小编辑距离算法,是动态规划算法类的一个典型示例。各种操作的代价可以是固定的(例如,对所有字符x,插入代价均为1),也可以与具体字符相关(以建模“某些字母比其他字母更容易被插入”的现象)。我们假设将一个字母替换为自身不产生代价(即,替换代价(x,x) = 0)。
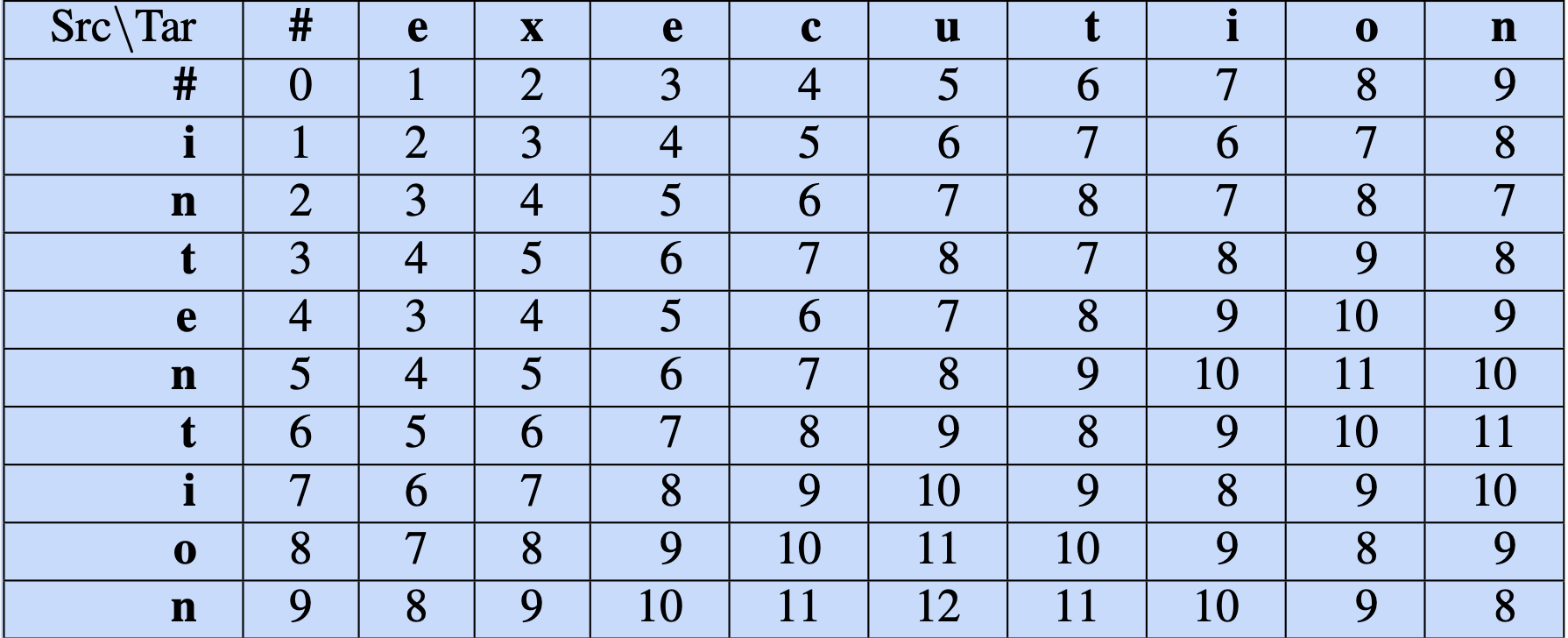
图 2.20 使用图 2.19 的算法计算 intention 与 execution 之间的最小编辑距离,采用莱文斯坦距离,插入和删除操作代价为1,替换操作代价为2。
对齐 了解最小编辑距离对于拼写错误候选纠正等算法非常有用。 但该算法还有另一重重要意义:稍作修改,它还能提供两个字符串之间的最小代价对齐(alignment)。 对齐在语音与语言处理的诸多任务中都有广泛应用。 在语音识别中,最小编辑距离对齐用于计算词错误率(见第 15 章)。 在机器翻译中,对齐也扮演着关键角色,机器翻译需要将平行语料库(包含两种语言文本的语料库)中的句子相互匹配。
要扩展编辑距离算法以生成对齐结果,我们可以先将对齐视为编辑距离矩阵中的一条路径。 图 2.21 用加粗的单元格标示了这条路径。 每个加粗的单元格代表两个字符串中一对字母的对齐关系。 如果两个加粗单元格出现在同一行,则表示从源字符串到目标字符串存在一次插入操作;若出现在同一列,则表示存在一次删除操作。
图 2.21 也展示了如何计算该对齐路径的思路。 整个计算过程分为两步。 第一步,我们对最小编辑距离算法进行增强,在每个单元格中存储回溯指针(backpointer)。 回溯指针从当前单元格指向进入该单元格时所来自的前一个(或多个)单元格。 我们在图 2.19 中展示了这些回溯指针的示意图。 某些单元格有多个回溯指针,因为最小代价的扩展可能来自多个前驱单元格。 第二步是进行回溯(backtrace)。 在回溯过程中,我们从最后一个单元格(位于最后一行和最后一列)开始,沿着指针逆向追踪回动态规划矩阵的起点。 从终点到起点的每一条完整路径都对应一个最小距离的对齐方式。 练习 2.7 要求你修改最小编辑距离算法,使其能够存储指针,并执行回溯以输出对齐结果。
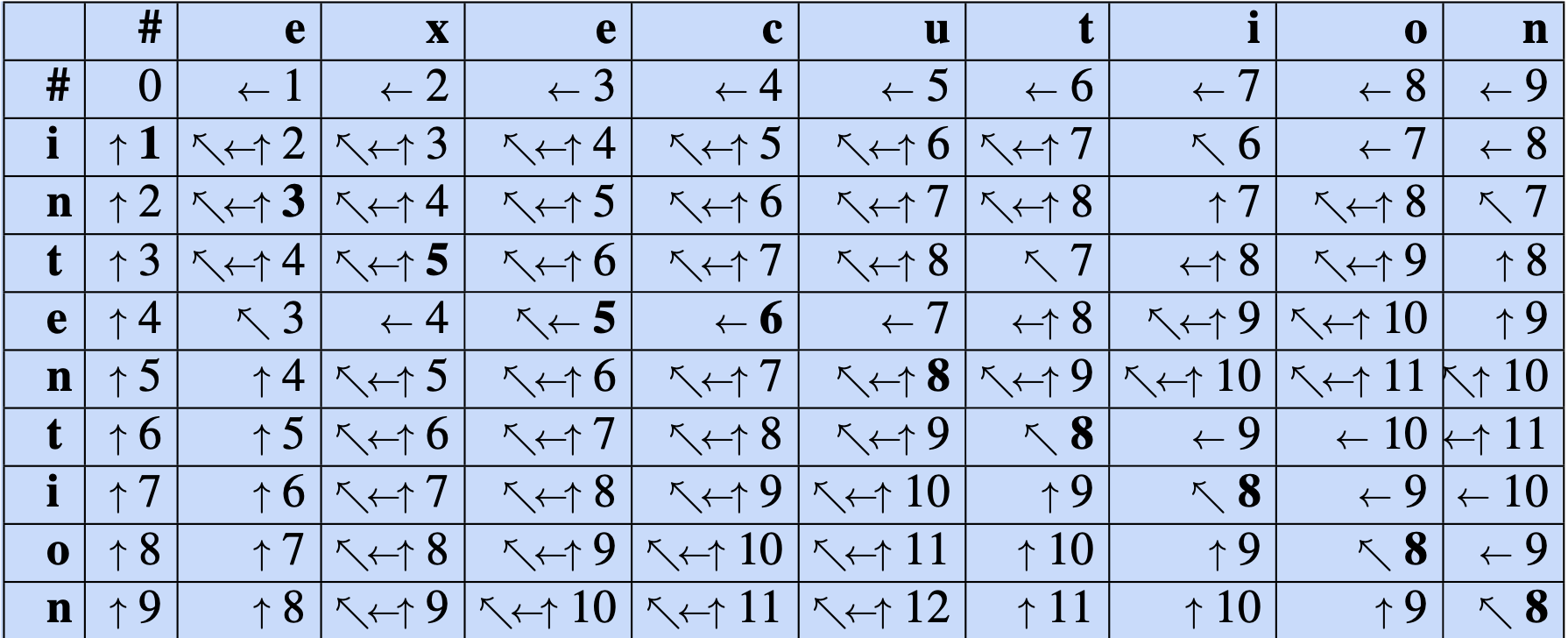
图 2.21 在向每个单元格填入数值时,我们用最多三个箭头标记出该值来自哪个相邻的三个单元格。表格填满后,通过回溯(backtrace)计算对齐路径(即最小编辑路径):从右下角的数字8开始,沿箭头逆向追踪。加粗单元格的序列代表了两个字符串之间一种可能的最小代价对齐方式,再次使用了插入/删除代价为1、替换代价为2的莱文斯坦距离。图表设计参考 Gusfield (1997)。
尽管我们的示例使用了简单的莱文斯坦距离,但图 2.17 中的算法允许为各种操作设置任意权重。 例如在拼写纠错中,键盘上相邻的字母之间更容易发生替换错误。 维特比算法(Viterbi algorithm)是最小编辑距离的一种概率化扩展。 维特比算法不是计算两个字符串间的“最小编辑距离”,而是计算一个字符串对另一个字符串的“最大概率对齐”。 我们将在第 17 章进一步讨论这一点。