下面这个句子中有多少个词?
They picnicked by the pool, then lay back on the grass and
looked at the stars.
如果我们不将标点符号视为词,则该句包含 16 个词;若计入标点,则为 18 个词。 是否将句号(“.”)、逗号(“,”)等视为词,取决于具体任务。 标点符号对于识别语言单位的边界(如逗号、句号、冒号)以及某些语义特征(如问号、感叹号、引号)至关重要。 大型语言模型通常将标点符号视为独立的词。
在口语中,对“词”的界定会带来其他复杂性。 例如,考虑以下来自口语对话的话语(utterance)(话语是语言学中与书面句子相对应的口语技术术语):
I do uh main- mainly business data processing
该话语包含两类不流畅现象(disfluencies)。 被中断的词 main- 被称为片段(fragment)。 像 uh 和 um 这样的成分则被称为填充词(fillers)或有声停顿(filled pauses)。 我们是否应将它们视为词? 答案依然取决于具体应用场景。 如果我们在构建语音转写系统,可能最终希望去除这些不流畅现象。 但有时我们也会保留它们。 事实上,uh 或 um 等不流畅现象在语音识别中对预测后续词汇有帮助,因为它们可能表明说话者正在重启某个子句或想法。因此,在语音识别任务中,它们通常被当作普通词处理。 此外,由于不同说话人使用不同的不流畅形式,这些现象还可作为识别说话人的线索。 Clark 与 Fox Tree(2002)甚至指出,uh 和 um 在英语中具有不同的语用含义。 你认为它们的区别是什么?
在思考“什么是词”时,或许最重要的是区分两种谈论词的方式,这一区分将在本书中反复使用。 词型(word types)指语料库中互不相同的词的数量;若词汇表为 $V$,则词型数量即为词汇量(vocabulary size)$|V|$。 词例(word instances)则是文本中所有连续出现的词的总数 $N$。1 若忽略标点符号,上述野餐句包含 14 个词型和 16 个词例:
They picnicked by the pool, then lay back on the grass and
looked at the stars.
我们仍需做出若干决策! 例如,首字母大写的字符串(如 They)与小写形式(如 they)是否应视为同一词型? 答案依然是:视任务而定! 在某些不关注格式细节的任务中,They 与 they 可能被归并为同一词型;而在其他任务中,大小写是重要的特征,需予以保留。 有时,我们会同时维护两个版本的 NLP 模型:一个保留大小写信息,另一个则不保留。
到目前为止,我们讨论的都是正字法词(orthographic words)——即依据英语书写系统划分出的词。
然而,“词”还有许多其他可能的定义方式。
例如,从正字法角度看,I’m 是一个词,但从语法功能上看,它实际由两个词组成:主语代词 I 和动词 ’m(即 am 的缩写形式)。
| 语料库 | 词型数 = $\vert V \vert$ | 词例数 = $N$ |
|---|---|---|
| 莎士比亚作品 | 3.1 万 | 88.4 万 |
| Brown 语料库 | 3.8 万 | 100 万 |
| Switchboard 电话对话 | 2 万 | 240 万 |
| COCA(当代美国英语语料库) | 200 万 | 4.4 亿 |
| Google n-grams | 1300 万 | 1 万亿 |
图 2.1 若干英语语料库中词形(wordform)的词型与词例数量概览。其中规模最大的 Google n-grams 语料库包含 1300 万个词型,但该统计仅包含出现频次 ≥40 的词型,因此实际词型总数会大得多。
一旦我们开始考虑其他语言,对“词”的界定就变得更加困难。 例如,中文、日文和泰语等语言的书写系统根本不存在正字法词(orthographic words)! 也就是说,它们不使用空格来标记潜在的词边界。 以中文为例,词由汉字(中文称为 hanzi)组成。 每个汉字通常表示一个独立的意义单位(即下文将介绍的 语素(morpheme)),并可作为一个音节发音。 中文词平均长度约为 2.4 个汉字。 但由于中文没有正字法词,判断什么应被视为一个“词”变得十分复杂。 例如,考虑以下句子:
(2.1) 姚明进入总决赛 yáo míng jìn rù zǒng jué sài
“Yao Ming reaches the finals”
正如 Chen 等人(2017b)所指出的,该句可被划分为 3 个词(采用“中文树库”(Chinese Treebank)的词定义,其中中文姓名——姓氏后面跟名字——被视为一个整体):
(2.2) 姚明 进入 总决赛
YaoMing reaches finals
但同一句子也可按 5 个词划分(采用“北京大学标准”(Peking University standard)),其中姓名被拆分为独立单元,某些形容词也被视为单独的词:
(2.3) 姚 明 进入 总 决赛
Yao Ming reaches overall finals
最后,在中文中甚至可以完全忽略“词”的概念,直接以汉字作为基本处理单元,将句子视为 7 个字符的序列。这种方法在多数应用场景下效果相当不错,因为汉字本身通常已处于合适的语义粒度(Li et al., 2019):
(2.4) 姚 明 进 入 总 决 赛
Yao Ming enter enter overall decision game
然而,这种基于字符的方法不适用于日语和泰语,因为在这些语言中,单个字符的语义单元过小,无法有效承载语言信息。
正是由于“词”的定义在跨语言场景下面临上述种种挑战,使得在自然语言处理中难以统一地以“词”作为文本词元化(tokenization)。
但“词”还存在另一个问题:数量实在太多了!!! 英语中究竟有多少个词? 当我们谈论一种语言中“词的数量”时,通常指的是词型(word types)。 图 2.1 展示了从若干英语语料库中统计得到的词型与词例的大致数量。
你会注意到,语料库规模越大,我们发现的词型就越多! 这表明“一种语言究竟有多少词”并没有明确答案——随着观察到的数据增多,这个数字会持续增长! 这一现象在数学上可以形式化描述:词型数量 $|V|$ 与词例总数 $N$ 之间的关系被称为 Herdan 定律(Herdan, 1960)或 Heaps 定律(Heaps, 1978),分别由语言学和信息检索领域的研究者独立提出。 该关系如公式 (2.5) 所示,其中 $k$ 和 $\beta$ 为正常数,且 $0 < \beta < 1$:
$$ |V| = kN^{\beta} \tag{2.5} $$参数 $\beta$ 的取值取决于语料库的规模和体裁;文献中常报告的数值范围在 0.44 到 0.56 之间,甚至更高。 粗略而言,一段文本的词汇量增长速度略快于其词数长度的平方根。
此外,该定律还存在一些变体,用以刻画两类大致可区分的词。 一类是功能词(function words),即像英语中的 a、of 这类语法性词汇,其数量通常不会无限增长(一种语言的功能词数量基本固定)。 另一类是实义词(content words),包括名词、形容词和动词,它们承载关于人、地点和事件的具体语义。 其中,名词——尤其是专有名词(如人名)和技术术语——往往会持续不断涌现。 因此,一些更精细的模型会区分这两类词:在语料初期阶段(所有类型的词仍在不断出现时)使用一个 $\beta$ 值,而在后期阶段(仅实义词继续新增时)则采用另一个 $\beta$ 值。 图 2.2 展示了 Tria 等人(2018)在 Gutenberg 图书语料库上计算 Heaps 定律时得到的两个不同 $\beta$ 值的实例。
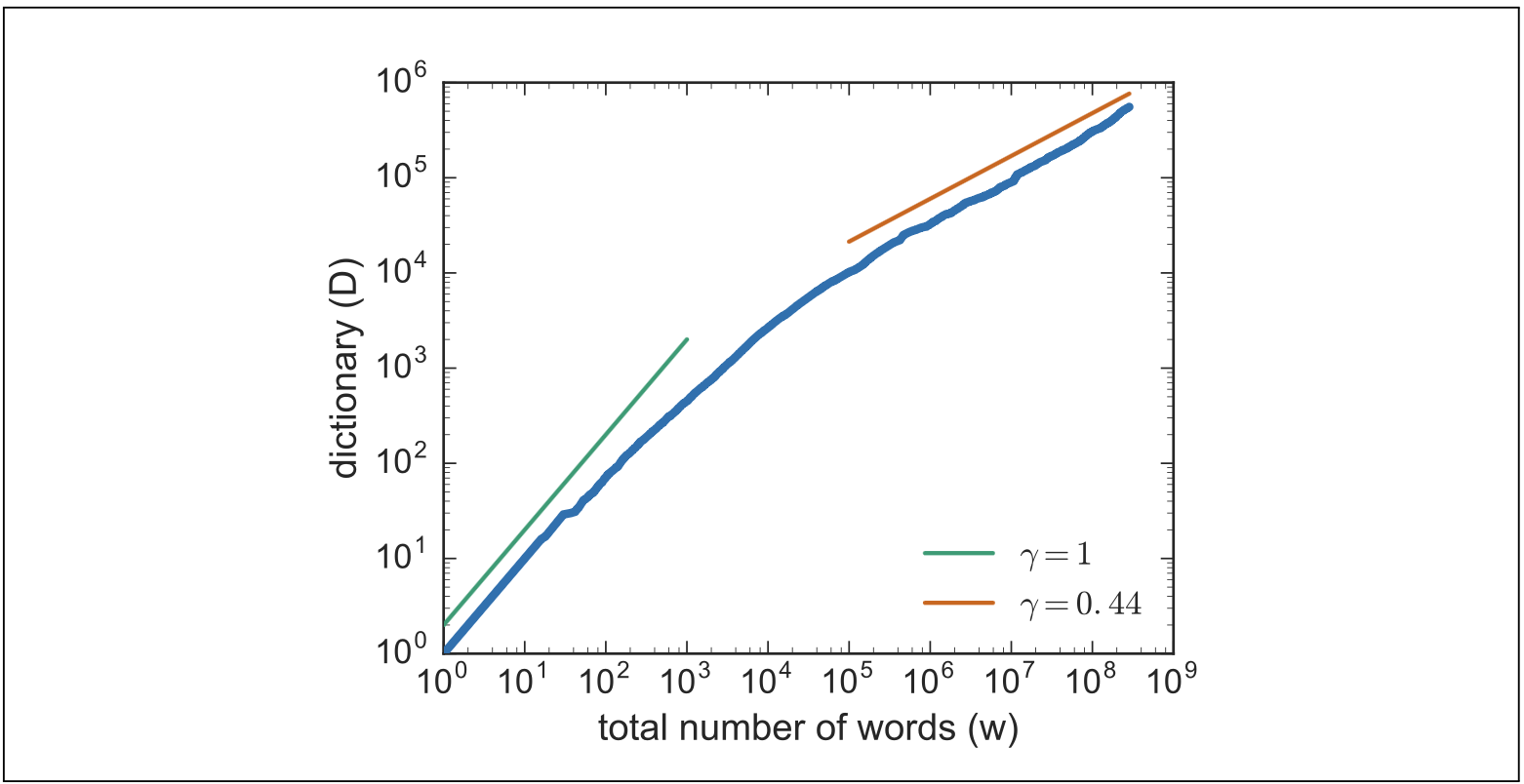
图 2.2 基于公开 Gutenberg 图书语料库计算的词汇量随文本长度的变化关系。引自 Tria 等(2018)。
词型数量无界增长这一事实,给任何计算模型都带来了根本性挑战。 无论我们的词汇表有多大,都不可能涵盖未来可能出现的所有词! 这意味着计算模型将不断遇到未登录词(unknown words)——即模型从未见过的词。 这对机器学习模型构成了巨大难题。
正因存在上述两个问题:(1)许多语言本身没有正字法词,事后定义词边界既困难又依赖标准;(2)词型数量随数据规模持续增长,永无上限, 现代语言模型及其他 NLP 模型通常不直接以“词”作为基本处理单元。 取而代之的是使用更小的单元,称为子词(subwords)。这些子词可以重新组合,从而有效建模模型从未见过的新词。 要探讨如何定义子词,我们首先需要讨论比词更小的语言单元:语素(morphemes)和字符(characters)。
在早期文献中(偶尔至今仍可见),词例有时被称为单词词元(word tokens),但我们现在倾向于将“词元(token)”一词专门用于指代子词词元化算法(如 BPE)的输出单元。 ↩︎