正如引言中所述,VALL-E 等 TTS 系统的基本结构是:以待合成的文本和目标说话人的语音样本作为输入,分别对二者进行词元化,文本使用 BPE(字节对编码)词元化,语音则通过音频编解码器转换为离散词元。 随后,系统利用一个语言模型,以这些输入为条件,生成与文本提示相对应、且具有语音样本音色的离散音频词元序列。
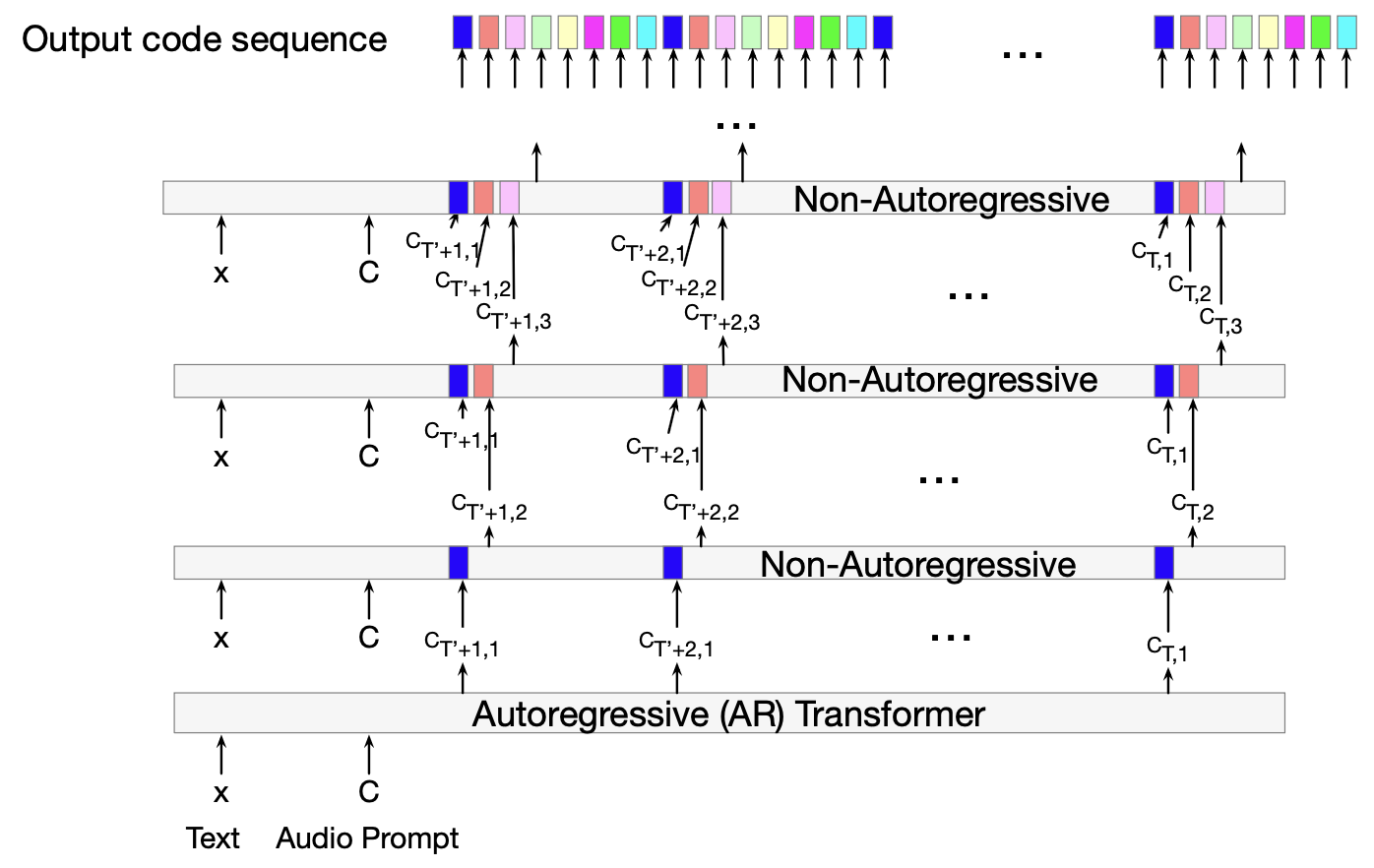
图 16.7 VALL-E 的两阶段语言建模方法,展示了自回归 Transformer 的推理阶段,以及后续 7 个非自回归 Transformer 中的前 3 个。 离散音频词元序列的生成分为两个阶段。 首先,自回归语言模型从左到右逐帧生成第一个量化器(即第一层 RVQ)的所有词元; 然后,非自回归模型被调用 7 次,每次基于前一层所有量化器的词元(包括右侧未来的词元)生成下一层的词元。
VALL-E 并未采用单一的自回归语言模型来完成这一条件生成任务,而是将其拆分为两阶段过程,使用两种不同的语言模型。 这一架构设计受到 RVQ 量化器(生成音频词元)层级结构的启发。 RVQ 的第一层量化器输出对最终语音质量影响最大,而后续各层仅提供越来越微弱的残差信息。 因此,语言模型也分两阶段生成声学词元。 首先,一个自回归语言模型(autoregressive LM)根据输入文本和注册语音样本(enrolled audio),从左到右生成整个输出序列中第一层量化器的全部词元; 接着,在已知这些第一层词元的前提下,一个非自回归语言模型(non-autoregressive LM)被连续运行 7 次。每次运行时,它以初始自回归生成的词元和之前所有非自回归层的输出为条件,依次生成剩余 7 个量化器层的词元。 图 16.7 直观地展示了这一推理过程。
下面我们更详细地介绍该架构。 在训练阶段,给定一段音频样本 $\mathbf{y}$ 及其对应的词元化后文本转录 $\mathbf{x} = [x_0, x_1, \dots, x_L]$。我们使用一个预训练好的 ENCODEC 模型将 $\mathbf{y}$ 转换为一个词元矩阵 $\mathbf{C}$。设 ENCODEC 输出的下采样向量数量为 $T$,每个向量对应 8 个 RVQ 词元,则编码器输出可表示为:
$$ \mathbf{C}^{T \times 8} = \text{ENCODEC}(\mathbf{y}) \tag{16.5} $$此处,$\mathbf{C}$ 是一个二维声学词元矩阵,共包含 $T \times 8$ 个元素。其中,列表示时间步(共 $T$ 列),行表示不同的量化器层级(共 8 行)。 具体来说,矩阵的第 $t$ 行向量 $c_{t,:}$ 包含第 $t$ 个时间帧对应的 8 个词元;第 $j$ 列向量 $c_{:,j}$包含来自第 $j$ 个向量量化器的完整词元序列,其中 $j \in [1, \dots, 8]$。
给定文本 $\mathbf「$ 和音频词元矩阵 $\mathbf『$,我们将 TTS 训练为一个条件词元语言模型,目标是最大化在给定文本 $\mathbf{x}$ 条件下音频词元矩阵 $\mathbf{C}$ 的似然:
$$ \begin{align*} L &= -\log p(\mathbf{C} \mid \mathbf{x}) \\ &= -\log \prod_{t=0}^{T} p(c_{t,:} \mid \mathbf{c}_{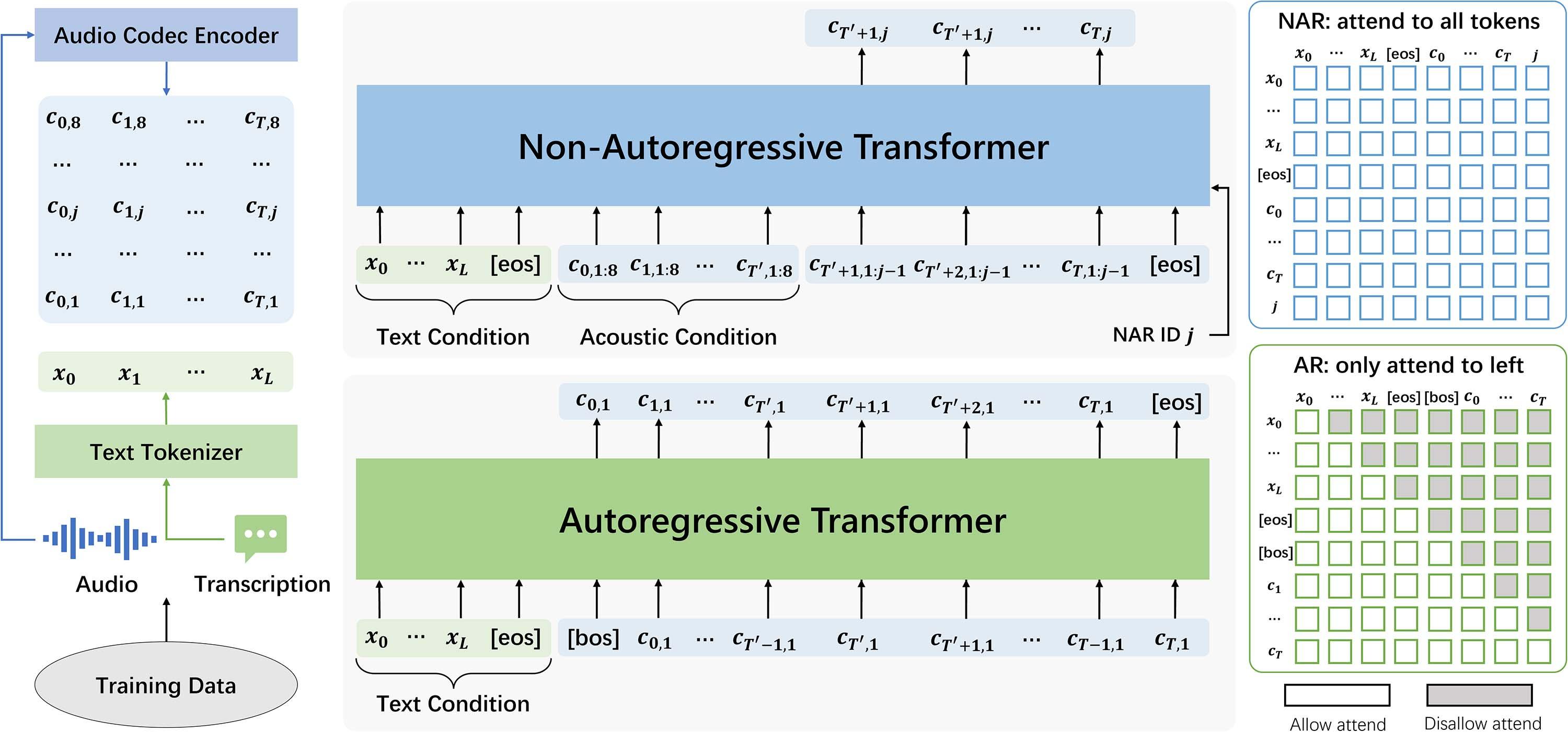
图 16.8 VALL-E 的训练流程。 给定文本提示后,首先训练自回归变换器逐个生成首个量化器代码序列中的每个代码。 之后,非自回归变换器负责生成剩余的代码。 该图来源于 Chen 等人(2025)的研究。
如图 16.8 所示,在左侧我们有一个音频样本及其转录文本,并且二者都进行了词元化处理。 然后我们在文本 $\mathbf{x}$ 的末尾附加 [EOS] 和 [BOS] 标记,在音频代码矩阵 $\mathbf{C}$ 的末尾附加 [EOS] 标记,接着训练自回归变换器从 $c_{0,1}$ 开始预测声学标记直到 [EOS] 出现。随后,非自回归变换器用于填充其余的标记。
在推理阶段,我们获得一段待合成的文本序列以及来自某位未见过的说话人的语音样本 $\mathbf{y}'$,并拥有其转录 transcript($\mathbf{y}'$)。 首先,我们运行编解码器(codec)为 $\mathbf{y}'$ 生成一个声学代码矩阵 $\mathbf{C}^P = \mathbf{C}_{:T',:} = [\mathbf{c}_{0,:}, \mathbf{c}_{1,:}, ..., \mathbf{c}_{T',:}]$。 接下来,我们将 $\mathbf{y}'$ 的转录与待合成的文本序列拼接起来,创建总的输入文本 $\mathbf{x}$ 并通过文本词元化器进行处理。 此时,我们得到词元化后的文本 $\mathbf{x}$ 和词元化后的音频提示 $\mathbf{C}^P$。
然后,基于文本序列 $\mathbf{x}$ 和提示 $\mathbf{C}_P$ 来生成 $\mathbf{C}^T = \mathbf{C}_{>T',:} = [\mathbf{c}_{T'+1,:}, ..., \mathbf{c}_{T,:}]$:
$$ \begin{align*} \mathbf{C}^T &= \underset{\mathbf{C}^T}{\text{argmax}} p(\mathbf{C}^T \mid \mathbf{C}^P,\mathbf{x}) \\ &= \underset{\mathbf{C}^T}{\text{argmax}} \prod^{T}_{t=T'+1} p(\mathbf{c}_{t,:} \mid \mathbf{c}_{图 16.9 VALL-E 的推理流程。 首先将 3 秒注册语音的转录添加到要生成的文本之前,并对语音和文本进行词元化处理。 接着,自回归变换器开始根据转录和声学提示生成第一个代码 $\mathbf{c}_{t'+1,1}$。
有关变换器组件和其他训练细节的更多信息,请参阅 Chen 等人(2025)的研究。