现代 TTS 系统的核心在于将语音波形转换为一串离散的音频词元(audio tokens)。 这种操作离散音频词元的思想,也适用于其他语音赋能系统,例如口语语言模型(spoken language models)。这类模型可以接收文本或语音输入,并生成文本或语音输出,用于完成语音到语音翻译、说话人日志(diarization)或口语问答等任务。 使用离散词元意味着我们可以利用语言模型技术——因为语言模型正是为处理离散词元序列而设计的。 因此,音频词元化器已成为现代语音工具箱中的关键组件。
目前学习音频词元的标准方法是使用神经网络实现的音频编解码器(audio codec)。“codec”一词由 coder/decoder(编码器/解码器)合成而来。 历史上,编解码器是一种将模拟信号数字化的硬件设备。 如今,我们更广义地用它指代一种机制:将模拟语音信号编码为一种可高效存储和传输的压缩数字表示。 编解码器仍广泛用于压缩,但在 TTS 和口语语言模型中,我们主要利用它们将语音转换为离散词元。
当然,我们在第 14 章描述的语音数字表示本身已经是离散的。 例如,以 16 kHz 采样率、16 位精度存储的语音,可以看作 $2^{16} = 65,536$ 个符号构成的序列,每秒钟的语音包含 16,000 个这种符号。 然而,若一个系统每秒需生成 16,000 个符号,那么语音信号序列就过长,难以被语言模型有效处理——尤其是基于 Transformer 的模型,其注意力机制具有二次方复杂度,效率较低。 因此,我们希望使用能代表更长时间片段的符号,例如每秒仅几百个词元。
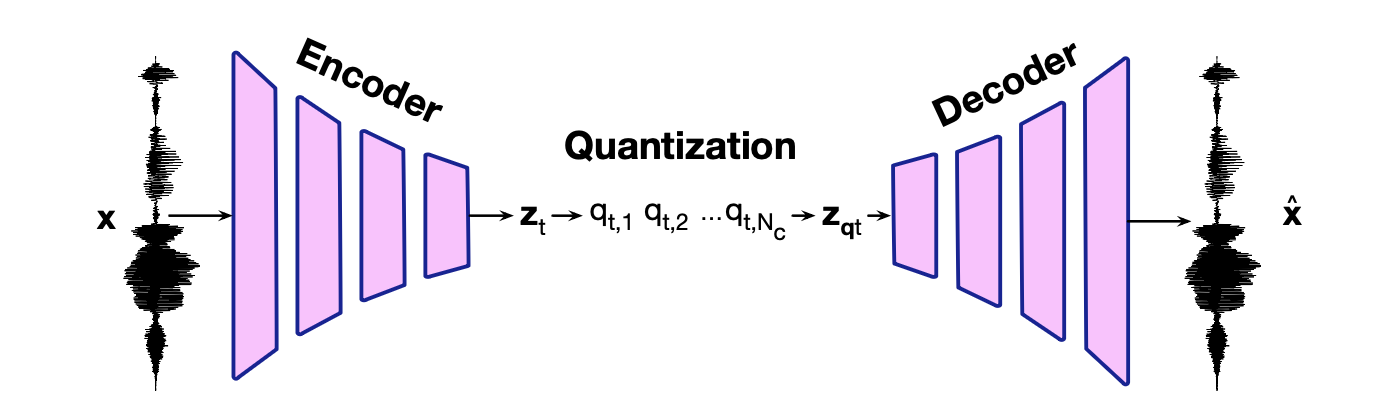
图 16.2 音频词元化器的标准推理架构(图改编自 Mousavi 等,2025)。 输入波形 $\mathbf{x}$ 经编码器(通常由一系列下采样卷积网络组成)转换为嵌入序列 $\mathbf{z}_t$。 每个嵌入随后通过量化器,生成离散词元序列 $q_t$。 为重建语音信号,这些量化后的词元会被重新映射为向量 $z_{qt}$,再经解码器(通常由一系列上采样卷积网络组成)还原为波形。 我们将在第 16.2.4 节讨论该架构的训练方式。
图 16.2(改编自 Mousavi 等,2025)展示了音频词元化器的标准架构。 音频词元化器以语音波形作为输入,通过一个由向量量化生成的离散词元构成的中间表示,训练目标是尽可能重建原始语音波形。
音频词元化器包含三个阶段:
编码器(encoder)将声学波形(即长度为 $T$ 的序列 $x = x_1, x_2, \dots, x_T$)映射为长度为 $\tau$ 的嵌入序列 $z = z_1, z_2, \dots, z_\tau$。其中 $\tau$ 通常比 $T$ 小 100 到 1000 倍。
向量量化器(vector quantizer)对每个对应于波形某一部分的嵌入 $z_t$ 进行处理,将其表示为一组离散词元 $q_t = q_{t,1}, q_{t,2}, \dots, q_{t,N_c}$,其中每个词元来自 $N_c$ 个码本(codebook)之一。该量化器还会将每个码本中对应的向量码字相加,得到量化器的输出向量 $z_{qt}$。
解码器(decoder)根据量化器输出向量 $z_{qt}$,生成有损重建的波形 $\hat{x}$。
音频词元化器通常采用端到端方式训练,其损失函数旨在鼓励系统学习一种词元表示,使得重建的波形尽可能接近原始输入。
在接下来的小节中,我们将详细介绍一种具体的词元化器——Défossez 等人(2023)提出的 ENCODEC 词元化器 的各个组成部分。
16.2.1 ENCODEC 模型的编码器与解码器
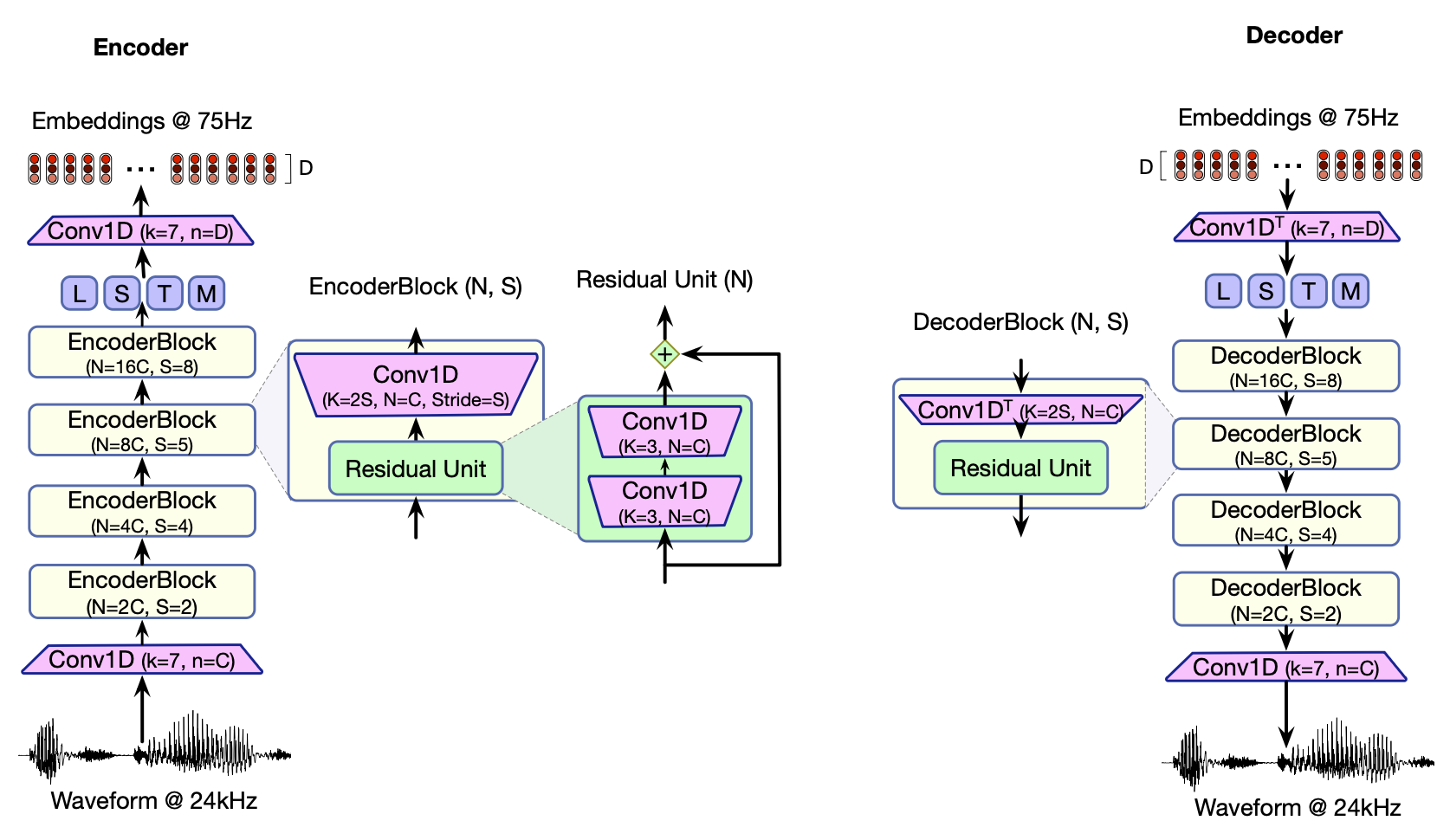
图 16.3 ENCODEC 模型的编码器与解码器阶段。 编码器的目标是将输入波形下采样,将其编码为每秒 75 个嵌入(即 75 Hz)的序列 $z_t$。 由于原始信号以 24 kHz 表示,这意味着下采样倍数为 $\frac{24000}{75} = 320$ 倍。 在编码器和解码器之间是一个量化步骤,生成有损嵌入 $\mathbf{z}_{qt}$。 解码器的目标则是接收该有损嵌入 $z_{qt}$,对其进行上采样,并还原为波形。
ENCODEC 模型(Défossez 等,2023)的编码器与解码器结构如图 16.3 所示。 编码器的作用是将时间步 $t$ 处的一段波形进行下采样。原始波形以 24 kHz 采样率表示——即每秒语音包含 24,000 个实数值;而编码器将其转换为 75 Hz 的嵌入表示 $z_t$——即每秒音频由 75 个向量表示,每个向量维度为 $D$。 为便于说明,此处我们设 $D = 256$。
这种下采样通过一系列编码器模块实现。每个模块由卷积层构成,且卷积步长(stride)大于 1,从而逐级对音频信号进行下采样——这与第 15.2 节末尾讨论的方法一致。 如图 16.3 所示,这些卷积模块包含一长串卷积层,以及残差单元(residual units),后者将一个卷积结果加到前一层的输入上。
编码器每秒输出 75 个嵌入 $\mathbf{z}_t$。 随后,每个嵌入 $z_t$ 会经过量化处理(详见下一节),被转换为 $N_c$ 个离散词元组成的序列 $q_t = q_{t,1}, q_{t,2}, \dots, q_{t,N_c}$,同时这些词元也会被重新组合成一个新的量化器输出向量 $\mathbf{z}_{qt}$。 最后,解码器接收来自量化器的输出嵌入 $\mathbf{z}_{qt}$,并通过一组对称的卷积网络(convnets)对其进行上采样,最终重建出原始波形。
总结来说:一个 24 kHz 的波形输入后,首先被编码并下采样为维度 $D = 256$ 的向量 $\mathbf{z}_t$;接着被量化为离散词元 $q_t$;然后这些词元被重新映射回维度 $D = 256$ 的向量 $\mathbf{z}_{qt}$;最后,该向量经解码和上采样,还原为 24 kHz 的波形。
16.2.2 向量量化
向量量化(Vector Quantization,简称 VQ)的目标是将一串向量转换为一串离散词元。
历史上,向量量化(Gray, 1984)主要用于压缩语音信号,以降低传输或存储所需的比特率。 为了压缩语音的向量序列表示,我们将每个向量替换为一个整数——即代表某个类别或聚类的索引。 这样,传输时就不再发送庞大的浮点向量,而只需发送该整数索引。 在接收端,再根据该索引还原出对应的向量。
而在 TTS 及其他现代语音应用中,我们使用向量量化的目的有所不同:因为 VQ 能够方便地生成离散词元,而这些词元恰好契合语言建模范式——语言模型擅长预测离散词元序列。
在实际应用中,对于 ENCODEC 模型及其他音频词元化器,我们采用一种更强大的向量量化形式,称为残差向量量化(residual vector quantization),我们将在下一节中定义它。 但在介绍这种扩展方法之前,先了解基本的 VQ 算法会更有帮助。
向量量化包含训练阶段和推理阶段。 我们在第 15.4.3 节介绍向量的 k-means 聚类时,实际上已经接触了基本 VQ 训练算法的核心,因为 k-means 是实现 VQ 最常用的算法。 简要回顾一下:在 VQ 训练中,我们首先将大量语音波形文件通过编码器处理,生成 N 个向量,每个向量对应语音中的某一帧。 然后,我们将这 N 个向量聚类为 k 个簇;k 是由设计者设定的参数,表示我们希望得到的离散词元数量,通常满足 $k \ll N$。 在最简单的 VQ 算法中,我们使用迭代式的 k-means 算法来学习这些簇。 如第 15.4.3 节所述,k-means 是一种两步迭代算法,其核心是不断更新一组共 k 个质心(centroid)向量。 质心是 n 维空间中一组点的几何中心。
k-means 聚类算法首先为每个簇随机分配一个初始向量。
随后进入两个交替进行的迭代步骤。
在分配(assignment)步骤中,给定当前的 k 个质心和全部向量数据集,每个向量被分配到与其码字(即质心)欧氏距离平方最小的那个簇。
在重估计(reestimation)步骤中,重新计算每个簇的码字,即取该簇内所有向量的均值作为新的质心。
通过反复执行这两个步骤,簇及其质心逐渐适应训练数据的分布,直至算法收敛。
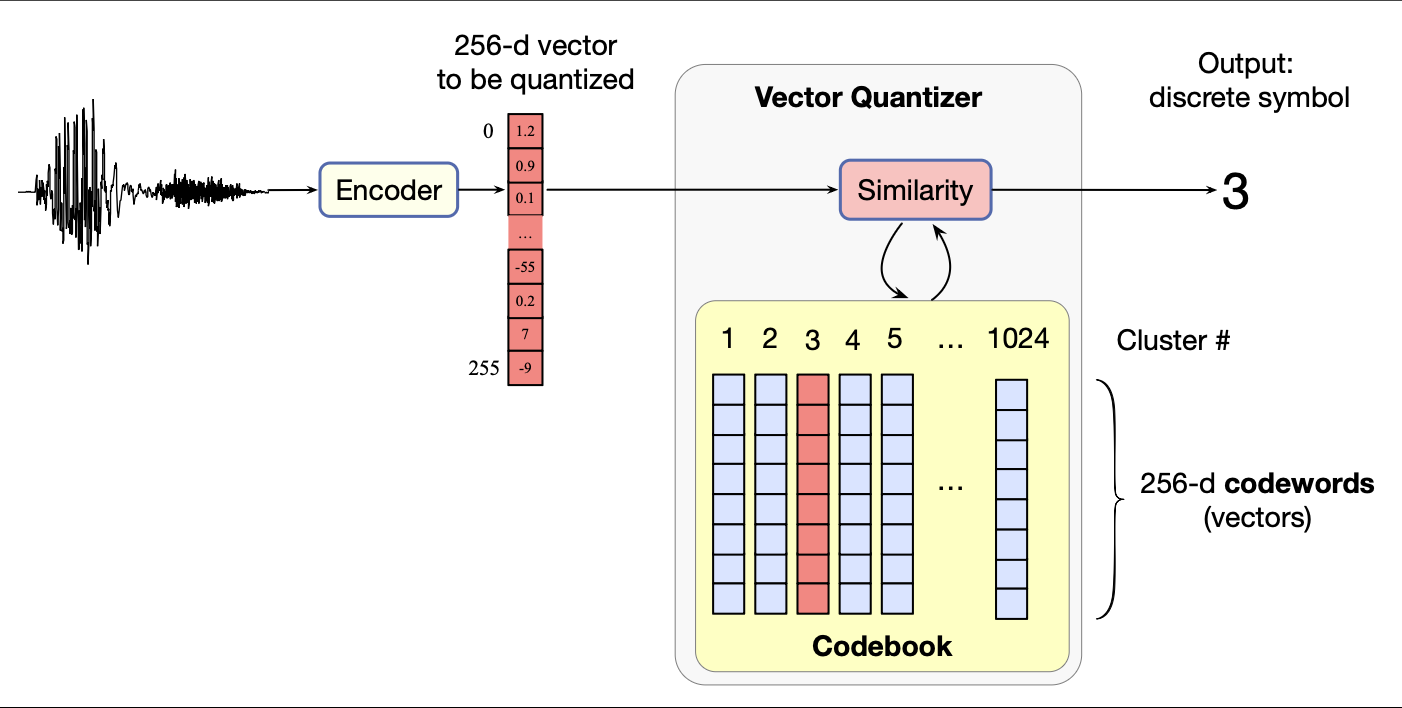
图 16.4 基本 VQ 算法在推理阶段的流程(码本已训练完成)。 输入是一段经编码器处理后的语音,表示为维度 $D = 256$ 的向量。 该向量与码本中的每个码字(即聚类质心)进行比较。 结果发现第 3 个簇的码字最相似,因此 VQ 输出整数 3,作为该向量的离散表示。
VQ 也可用于端到端训练(如下文所述)。此时,我们不再使用迭代式 k-means,而是在小批量训练过程中,通过指数移动平均(exponential moving averages)等在线算法动态更新质心。
聚类完成后,每个簇的索引即可作为离散词元使用。 每个簇还关联一个码字(codeword),即该簇中所有向量的质心。 我们将所有簇 ID(即词元)及其对应码字组成的集合称为码本(codebook),而簇 ID 本身常被称为码(code)。
在推理阶段,当输入一个新的向量时,我们将其与码本中的每个码字进行比较。 找到距离最近的码字后,就将该向量分配给对应簇。 图 16.4 直观展示了语音编码场景下的这一推理过程:
- 输入语音波形被编码为一个向量 $\mathbf{v}$;
- 该向量 $\mathbf{v}$ 与码本中 1024 个可能的码字逐一比较;
- 发现 $\mathbf{v}$ 与第 3 号码字最相似;
- 因此,VQ 的输出是离散词元 3,用以表示向量 $\mathbf{v}$。
正如我们将在下文看到的那样,在端到端训练 ENCODEC 模型时,我们需要一种方法将这个离散词元还原为波形。 在简单 VQ 中,我们直接使用该簇对应的码字,并将该码字传给解码器,由解码器重建波形。 当然,由于码字向量不可能完全匹配原始语音片段的编码向量(尤其当码本仅有 1024 个码字时),重建必然存在信息损失。但如果码本质量良好,码字至少能近似原始向量,解码器仍可生成合理的语音。 尽管如此,实践中通常会采用更强大的方法,我们将在下一节介绍。
16.2.3 残差向量量化
在实践中,简单的 VQ 无法产生足够好的重建效果——至少在码本大小为 1024 的情况下是如此。 编码所有可能语音波形后得到丰富多样的嵌入,1024 个码字向量不足以表示它们。 因此,ENCODEC 模型(以及许多其他音频分词方法)采用了一种更复杂的变体,称为残差向量量化(Residual Vector Quantization,简称 RVQ)。 在残差向量量化中,我们使用多个码本,并以层级方式组织它们。
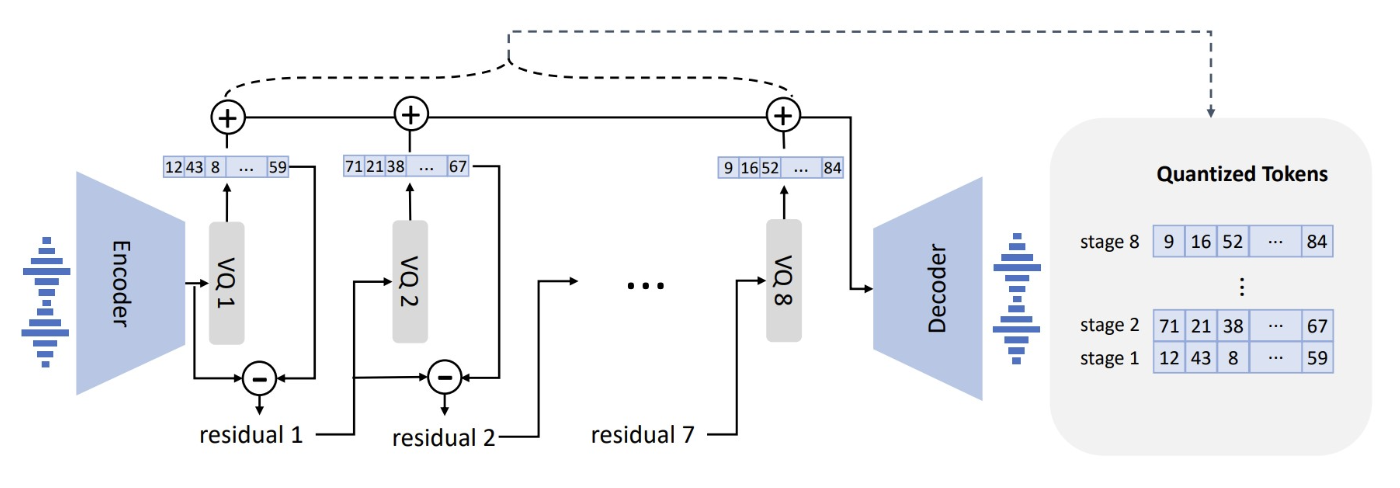
图 16.5 残差 VQ(引自 Chen 等,2025)。 我们对编码器输出的嵌入执行 VQ,得到一个离散词元及其对应的码字。 然后计算残差——即编码器输出嵌入 $z_t$ 与 VQ 所选码字之间的差值。 接着,我们使用第二个码本对该残差再次执行 VQ。 重复此过程,直到获得 8 个词元。
其基本思想非常简单。 我们首先像上一节图 16.4 那样,使用一个码本进行标准 VQ。 对于输入嵌入 $\mathbf{z}_t$,我们得到第一个码字向量,记作 $z^{(1)}_{qt}$(表示由码本 1 对 $z_t$ 量化后的结果),然后计算两者之差:
$$ \text{residual} = z_t - z^{(1)}_{qt}. \tag{16.1} $$这个残差就是 VQ 引入的误差——即原始向量中未被 VQ 捕获的部分。 该残差类似于“舍入误差”:VQ 相当于将向量“四舍五入”到最近的码字,从而产生一定误差。 于是,我们将这个残差向量送入另一个向量量化器,得到第二个码字,用以表示向量的残差部分。 接着,再对第二个码字产生的新残差重复这一过程。 最终,我们得到 8 个码字(第一个原始码字加上后续 7 个残差码字)。
这意味着,在 RVQ 中,我们用 8 个离散词元(而非基本 VQ 中的 1 个)来表示原始语音片段。 图 16.5 直观地展示了这一过程。
那么,在需要重建语音时,我们该怎么做? ENCODEC 的 RVQ 方法同样简单:我们将这 8 个码字相加! 所得向量 $\mathbf{z}_{qt}$ 随后被送入解码器,用于生成最终的波形。
16.2.4 音频词元的 ENCODEC 模型训练
ENCODEC 模型(以及类似的音频词元化器模型)采用端到端方式进行训练。 输入是一段波形,通常是从更长原始语音中截取的 1 秒或 10 秒片段。 期望的输出是与输入完全相同的波形片段——因为该模型本质上是一种自编码器(autoencoder),其目标是学习将输入映射回自身。 该模型在大规模语音数据集上进行重建训练,例如 Common Voice(Ardila 等,2020)——包含 133 种语言、超过 3 万小时的语音;同时也使用其他音频数据,如 AudioSet(Gemmeke 等,2017)——包含 170 万段来自 YouTube 视频的 10 秒音频片段,这些片段根据一个涵盖自然声、动物声、机器声、音乐等类别的大型本体进行了标注。
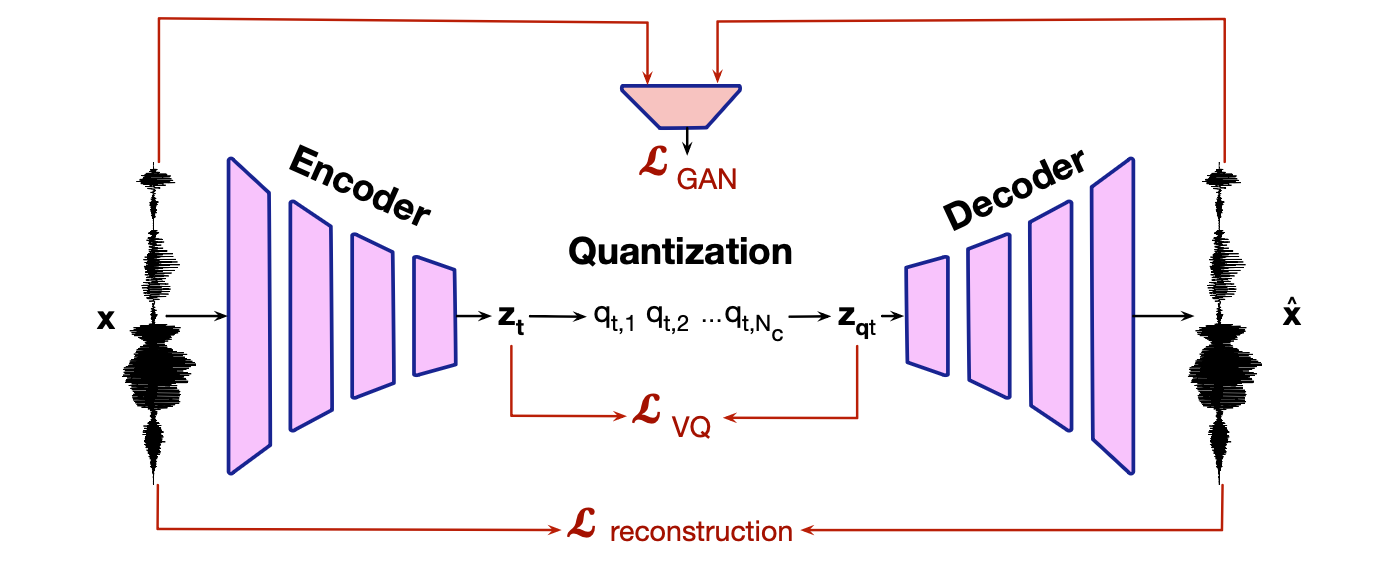
图 16.6 音频词元化器的训练架构(图改编自 Mousavi 等,2025)。 音频词元化器通过多种损失函数的加权组合进行训练,图中对此进行了概括,下文将详细说明。
与大多数音频词元化器一样,ENCODEC 模型使用多个损失函数进行训练,如图 16.6 所示。 首先是重建损失(reconstruction loss)$L_{\text{reconstruction}}$,用于衡量输出波形与输入波形的相似程度。例如,可通过原始音频与重建音频之间的平方误差之和来计算:
$$ L_{\text{reconstruction}}(\mathbf{x},\hat{\mathbf{x}}) = \sum_{t=1}^T \|x_t - \hat{x}_t \|^2 \tag{16.2} $$此外,还可以在频域中衡量相似性:比较原始音频与重建音频的梅尔频谱图(mel-spectrogram),同样使用 L2 距离(平方和)、L1 距离,或两者的组合。
另一种损失是对抗损失(adversarial loss)$L_{\text{GAN}}$。 为此,我们训练一个生成对抗网络(GAN),包括一个生成器和一个二分类判别器 $D$。该判别器的作用是区分真实波形 $x$ 与生成波形 $\hat{x}$。 我们的目标是让生成器“欺骗”判别器,因此判别器越强,说明当前重建效果越差。于是,我们将判别器的成功率用作损失函数。 此外,也可以引入生成器输出的多种特征来增强该损失。
最后,我们需要为量化器设计专门的损失。 这是因为,在端到端训练中,量化步骤位于模型中间,而量化操作本身不可微,会导致反向传播时梯度无法正常传递。 我们通过两种方式解决这一问题。 第一,在反向传播时直接忽略量化步骤。 具体做法是:将量化器输出 $\mathbf{z}_{qt}$ 处的梯度原样复制回量化器输入 $\mathbf{z}_t$ 处。这种方法称为直通估计器(straight-through estimator)(Van Den Oord 等,2017)。
我们需要确保向量量化器中的码字在训练过程中能够被有效更新。 一种方法是:先对编码器输出的嵌入 $\mathbf{z}_t$ 进行 k-means 聚类,以此初始化码本。 然后,我们引入一个额外的损失项 $L_{\text{VQ}}$,它衡量编码器输出向量 $\mathbf{z}_t$ 与量化后重建向量 $\mathbf{z}_{qt}$(即码字)之间的差异,并对所有 $N_c$ 个码本及残差层级求和:
$$ L_{\text{VQ}}(x,\hat{x}) = \sum_{t=1}^T \sum_{c=1}^{N_c} \|\mathbf{z}^{(c)}_t - \mathbf{z}^{(c)}_{qt} \| \tag{16.3} $$最终的总损失函数是上述各项损失的加权和:
$$ L(\mathbf{x},\hat{\mathbf{x}}) = \lambda_1 L_{\text{reconstruction}}(x,\hat{\mathbf{x}}) + \lambda_2 L_{\text{GAN}}(\mathbf{x},\hat{\mathbf{x}}) + \lambda_3 L_{\text{VQ}}(\mathbf{x},\hat{\mathbf{x}}) \tag{16.4} $$