文本到语音(TTS)的任务是:根据用户指定的特定声音,生成与目标文本相对应的语音波形。
传统上,TTS 的实现方式是在实验室中从单一说话人那里收集数百小时的语音数据,并在此基础上训练一个大型系统来。 由此构建的 TTS 系统只能合成一种声音。如果需要第二种声音,就必须重新收集另一位说话人的语音数据。
现代方法则不同:使用来自数千名说话人的数万小时语音数据,训练一个与说话人无关的合成器。 当需要生成训练过程中从未见过的新声音时,只需提供极少量的目标说话人语音(例如几秒钟),即可引导系统生成该声音。 因此,现代 TTS 系统的输入包括一段文本提示,以及大约 3 秒钟的目标说话人语音样本。 这种 TTS 任务被称为 零样本 TTS(zero-shot TTS),因为目标声音可能在训练阶段从未出现过。
现代 TTS 系统解决这一任务的方式是采用语言建模,特别是条件生成方法。 其基本思路是:首先获取一个庞大的语音数据集;然后利用基于音频编解码器(audio codec)的音频词元化器(audio tokenizer),从语音中提取出离散的音频标记(tokens),用以表示语音内容。 接着,我们训练一个语言模型,其词汇表同时包含语音词元和文本词元。
在训练过程中,该语言模型接收两个序列作为输入:一段文本转录稿,以及一小段目标说话人的语音样本。模型将文本和语音分别转换为离散标记,然后以这些标记为条件,生成与输入文本相对应、且具有目标说话人音色的离散语音标记序列。
在推理阶段,我们将经过分词的文本字符串和目标声音样本(由编解码器转换为离散音频标记)作为提示输入该语言模型。模型据此条件生成所需的音频词元。 随后,这些词元可被还原为语音波形。
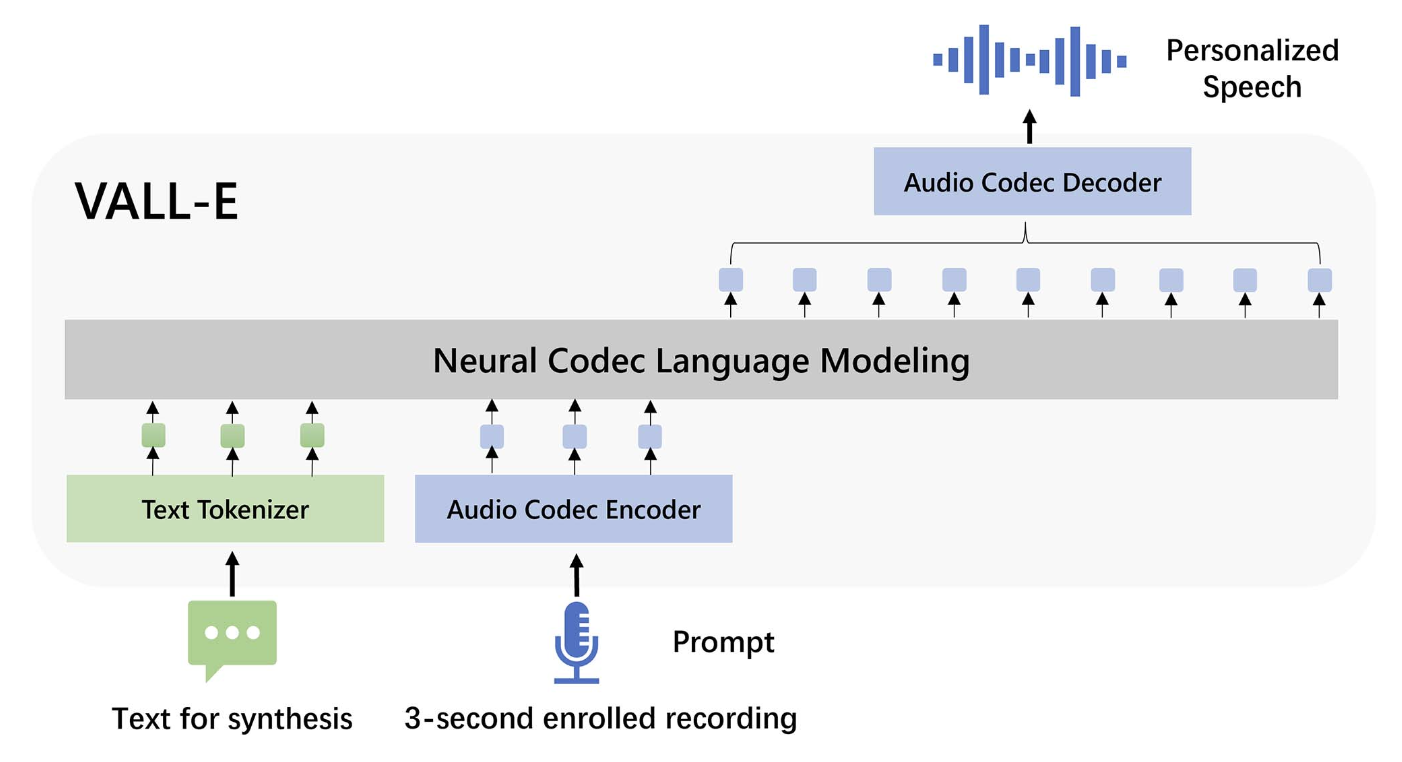
图 16.1 VALL-E 架构用于个性化 TTS(引自 Chen 等,2025)。
Chen 等人(2025)提出的图 16.1 展示了一种此类 TTS 系统的基本思路,该系统名为 VALL-E。 VALL-E 在超过 7000 名不同说话人的 6 万小时英语语音数据上进行训练。 像 VALL-E 这样的系统包含两个组成部分:
音频词元化器(audio tokenizer),通常基于音频编解码器(audio codec)——我们将在下一节详细描述该系统。 编解码器包含三个部分:编码器(将语音转换为嵌入向量)、量化器(将嵌入向量转换为离散词元),以及解码器(将离散词元还原为语音)。
两阶段的条件语言模型(conditional language model),能够生成与目标文本对应的音频词元。我们将在第 16.3 节简要介绍该模型。