“文字的意义远不止于纸面上所写下的内容。唯有通过人的声音,才能为其注入更深层的意蕴。”
——玛雅·安杰卢,《我知道笼中鸟为何歌唱》
将文本转换为语音的任务,其历史甚至比语音识别还要悠久。 1769年,在维也纳,沃尔夫冈·冯·肯佩伦为玛丽亚·特蕾莎女皇制造了著名的“机械土耳其人”。那是一个下棋的自动装置,由一个装满齿轮的木箱构成,箱后坐着一个机器人偶,能用机械手臂移动棋子下棋。 “机械土耳其人”在欧洲和美洲巡展数十年,曾击败拿破仑·波拿巴,甚至还与查尔斯·巴贝奇对弈过。 若非后来被揭穿——原来箱内藏有一名真人棋手操控——它或许会被视为人工智能早期的一大成功案例。
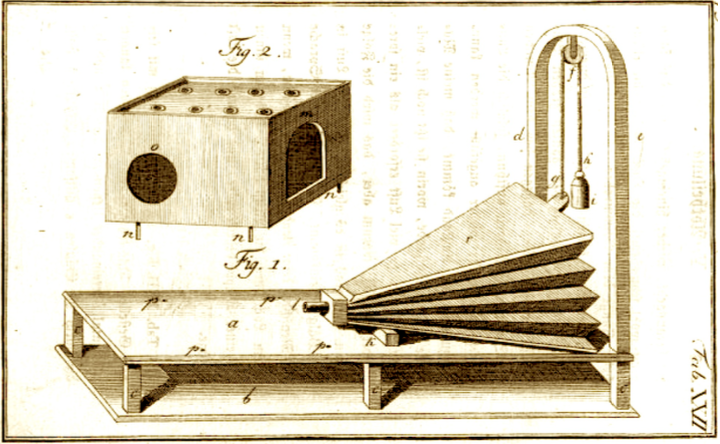
较少为人所知的是,冯·肯佩伦还是一位极其多产的发明家。他在1769年至1790年间,建造了一台绝非骗局的装置:世界上第一台能合成完整句子的语音合成器(部分结构见右图)。 该装置包含一个风箱,用于模拟肺部;一个橡胶制的口模和鼻孔开口;一片簧片,用来模拟声带;若干哨子,用于生成擦音;还有一个小型辅助风箱,专门提供爆破音所需的气流。 操作者双手操纵杠杆,控制各处开口的开合,并调节柔性皮革制成的“声道”,从而发出不同的辅音和元音。
两个多世纪之后,我们不再用木材和皮革来构建语音合成器,也不再需要人工操作。现代的文本到语音(Text-to-Speech,简称 TTS),也称语音合成,其任务正好与自动语音识别(ASR)相反:它将文本:
It's time for lunch!
映射为一段声学波形:
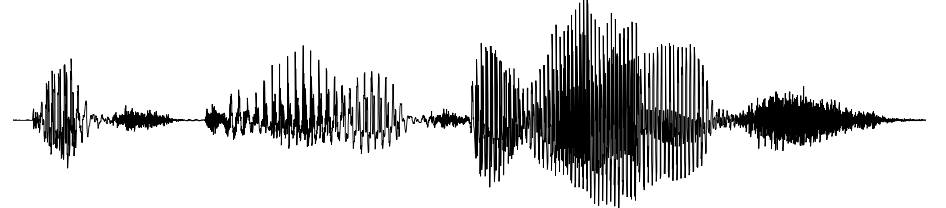
TTS 拥有广泛的应用场景。 它被用于与人类交互的口语语言系统,用于朗读文本,用于游戏配音,也用于为神经系统疾病患者生成语音。例如,已故天体物理学家斯蒂芬·霍金因罹患肌萎缩侧索硬化症(ALS)而失去发声能力后,就依靠TTS系统进行交流。
本章将介绍一种TTS算法。与上一章所述的ASR算法类似,这种算法也是在海量语音数据集上训练而成的。 我们还将简要介绍其他一些语音应用。