在上一节中,我们指出语音识别有两个特别的属性,使其非常适合编码器-解码器架构:编码器生成输入的编码,解码器则通过注意力机制来探索这些编码。 首先,在语音中,我们有一个非常长的声学输入序列 $X$ 映射到一个短得多的字母序列 $Y$;其次,很难确切知道 $X$ 的哪一部分映射到 $Y$ 的哪一部分。
在本节中,我们将简要介绍一种替代编码器-解码器的方法:一种名为CTC(Connectionist Temporal Classification,连接时序分类)的算法和损失函数(Graves 等,2006),它以非常不同的方式处理这些问题。 CTC 的原理是为每个输入帧输出一个字符,使得输出长度与输入相同,然后应用一个折叠函数将连续相同的字母合并,从而得到一个较短的序列。
假设我们要识别某人说出“dinner”这个词,并且我们有一个函数可以为每个输入谱帧表示 $x_i$ 选择最可能的字母。 我们将与每个输入帧对应的字母序列称为对齐(alignment),因为它告诉我们声学信号中的每一部分对应哪个字母。 图 15.12 展示了一个这样的对齐示例,以及如果我们使用一个简单的折叠函数去除连续重复字母会发生什么。
显然,这种方法行不通;我们的简单算法将语音转录成了“diner”,而不是“dinner”! 折叠操作无法处理双写字母。 此外,我们的简单函数还有一个问题:它没有告诉我们如何对输入中的静音部分进行对齐。 我们不希望将静音部分转录成随机的字母!
CTC 算法通过在转录字母表中添加一个特殊的符号——空白(blank),解决了这两个问题,我们用 ␣ 表示这个符号。 每当不想转录一个字母时,就可以在对齐中使用空白符号。 空白也可以用于字母之间;由于我们的折叠函数只折叠连续重复的字母,因此不会跨过空白折叠。 更正式地讲,让我们定义一个从对齐 $a$ 到输出 $y$ 的映射 $B: a \rightarrow y$,该映射会折叠所有重复的字母并移除所有空白。 图 15.13 展示了这个折叠函数 $B$。
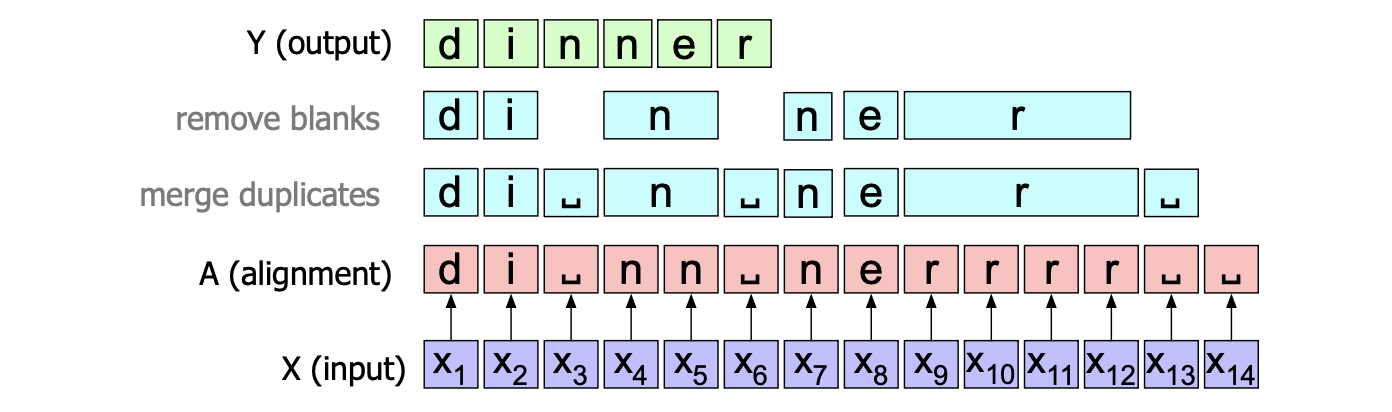
图 15.13 CTC 折叠函数 $B$,显示了空白字符 ␣;对齐 $A$ 中的重复(连续)字符被移除以形成输出 $Y$。
CTC 折叠函数是多对一的;许多不同的对齐可以映射到同一个输出字符串。 例如,图 15.13 所示的对齐并不是唯一产生字符串“dinner”的对齐方式。 图 15.14 展示了其他一些也会产生相同输出的对齐方式。

图 15.14 其他三种合法的对齐方式,均产生转录结果“dinner”。
思考所有可能产生相同输出 $Y$ 的对齐集合是有用的。 我们将使用 $B$ 函数的逆函数 $B^{-1}$,并用 $B^{-1}(Y)$ 表示该集合。
15.5.1 CTC 推理
在讨论如何计算 $P_{\text{CTC}}(Y \mid X)$ 之前,我们先看看 CTC 如何为某一个特定的对齐 $\hat{A} = (\hat{a}_1, \dots, \hat{a}_T)$ 分配概率。 CTC 做了一个很强的条件独立性假设:它假设在给定输入 $X$ 的条件下,CTC 模型在时刻 $t$ 的输出与任何其他时刻的输出标签 $a_i$ 相互独立。因此:
$$ P_{\text{CTC}}(\mathbf{A} \mid \mathbf{X}) = \prod_{t=1}^T p(a_t \mid \mathbf{X}) \tag{15.16} $$于是,为了找到最优对齐 $\hat{A} = (\hat{a}_1, \dots, \hat{a}_T)$,我们可以对每个时间步 $t$ 贪心地选择概率最大的字符:
$$ \hat{a}_t = \underset{c \in C}{\arg\max} \, p_t(c \mid \mathbf{X}) \tag{15.17} $$然后将得到的序列 $A$ 输入 CTC 折叠函数 $B$,从而获得最终的输出序列 $Y$。
我们谈谈这种寻找最优对齐 $A$ 的简单推理算法是如何实现的。 由于我们在每个时间点都做出独立决策,因此可以将 CTC 视为一个序列建模任务:在每个时间步 $t$,针对对应的输入帧 $x_t$ 输出一个字符 $\hat{\mathbf{y}}_t$,而无需完整的解码器。 图 15.15 展示了这种架构:我们仅使用一个编码器,在每个时间步生成隐藏状态 $\mathbf{h}_t$,然后通过对字符词汇表进行 softmax 得到该时刻的输出。
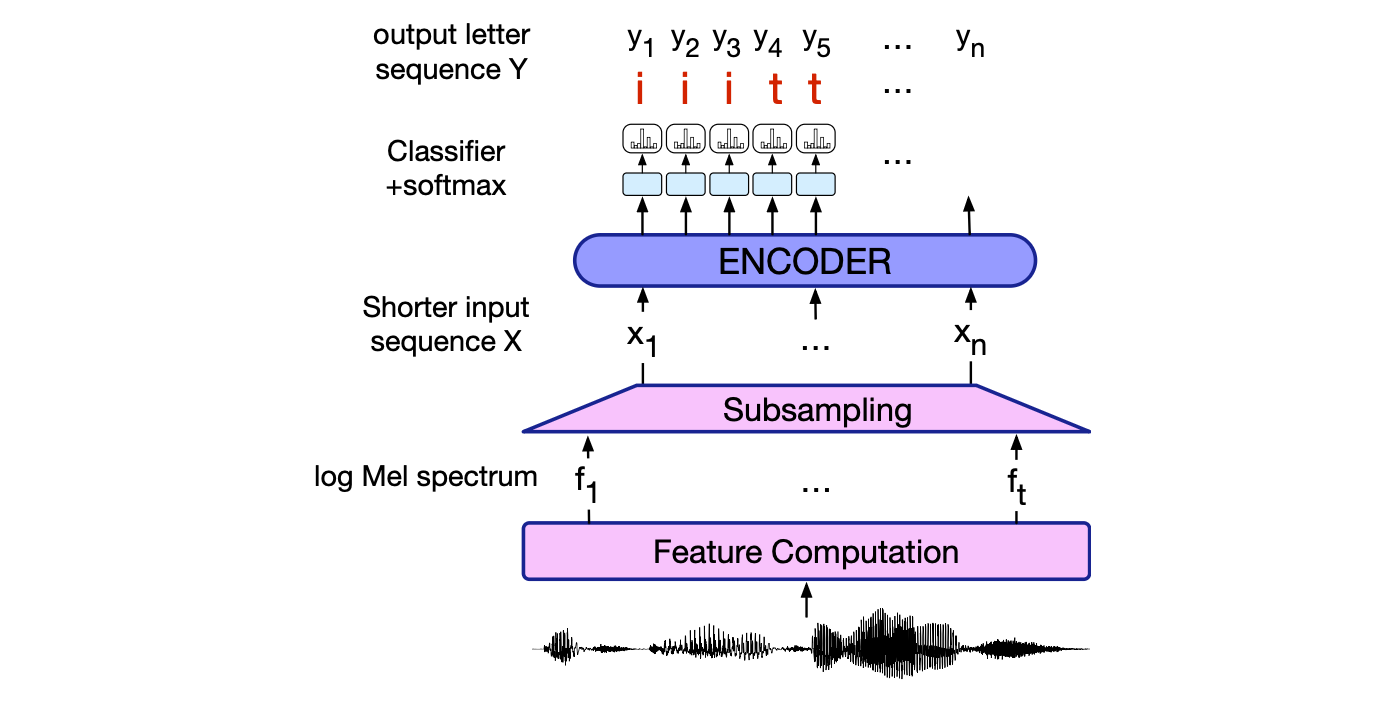
图 15.15 CTC 推理:使用纯编码器模型,每个输出步通过对隐藏状态 $\mathbf{h}_t$ 进行简单的 softmax 完成解码。
然而,公式 (15.17) 和图 15.15 所示的推理算法存在一个潜在缺陷。 这里的问题是我们选择了最可能的对齐 $A$,但这个对齐未必对应最可能的最终折叠输出字符串 $Y$。 这是因为多个不同的对齐可能折叠为同一个输出字符串;因此,最可能的输出字符串可能并非来自单一最高概率的对齐。 例如,假设对于输入 $X = [x_1, x_2, x_3]$,最可能的对齐是 $[a, b, \epsilon]$,但接下来两个次高概率的对齐分别是 $[b, \epsilon, b]$ 和 $[\epsilon, b, b]$。 那么输出 $Y = [b, b]$(由后两个对齐折叠而来)的总概率,可能高于 $Y = [a, b]$。
因此,最可能的输出序列 $Y$ 并非对应单个最优 CTC 对齐,而是对应其所有可能对齐的概率之和最大的那个:
$$ \begin{align*} P_{\text{CTC}}(Y \mid \mathbf{X}) &= \sum_{A \in B^{-1}(Y)} P(A \mid \mathbf{X}) \\ &= \sum_{A \in B^{-1}(Y)} \prod_{t=1}^T p(a_t \mid h_t) \\ \hat{Y} &= \underset{Y}{\arg\max} \, P_{\text{CTC}}(Y \mid \mathbf{X}) \tag{15.18} \end{align*} $$遗憾的是,对所有对齐求和的计算代价极高(因为对齐数量巨大)。 因此,实践中通常采用一种改进的 Viterbi 束搜索(beam search)来近似该求和:该方法巧妙地在束中保留那些映射到相同输出字符串的高概率对齐,并将它们的概率相加,以此作为公式 (15.18) 的近似。 关于这种适用于 CTC 的束搜索扩展,Hannun(2017)提供了清晰的解释。
此外,由于前述的强条件独立性假设(即在给定输入的前提下,时刻 $t$ 的输出与时刻 $t-1$ 的输出无关),CTC 不会隐式地学习数据上的语言模型(这与基于注意力的编码器-解码器架构不同)。 因此,在使用 CTC 时,必须显式地融合一个外部语言模型(以及某种长度因子 $L(Y)$),并通过在开发集上调整的插值权重进行组合:
$$ \text{score}_{\text{CTC}}(Y \mid \mathbf{X}) = \log P_{\text{CTC}}(Y \mid \mathbf{X}) + \lambda_1 \log P_{\text{LM}}(Y) + \lambda_2 L(Y) \tag{15.19} $$15.5.2 CTC 训练
要训练一个基于 CTC 的 ASR 系统,我们使用负对数似然损失,并采用专门的 CTC 损失函数。 因此,整个数据集 $D$ 上的损失是每个输入 $X$ 对应正确输出 $Y$ 的负对数似然之和:
$$ L_{\text{CTC}} = \sum_{(X,Y) \in D} -\log P_{\text{CTC}}(Y \mid \mathbf{X}) \tag{15.20} $$对于单个输入-输出对 $(\mathbf{X}, Y)$,要计算 CTC 损失,我们需要得到在给定输入 $\mathbf{X}$ 的条件下输出 $Y$ 的概率。 如公式 (15.18) 所示,计算某个输出 $Y$ 的概率需要对其所有可能折叠为 $Y$ 的对齐进行求和。 换句话说:
$$ P_{\text{CTC}}(Y \mid \mathbf{X}) = \sum_{A \in B^{-1}(Y)} \prod_{t=1}^T p(a_t \mid h_t) \tag{15.21} $$直接对所有可能的对齐进行穷举求和是不可行的(因为对齐数量呈指数级增长)。 然而,我们可以借助动态规划高效地完成这一求和:通过合并具有相同前缀或后缀的对齐路径,使用一种类似于训练 HMM(见附录 A)和 CRF 时所用的 前向-后向算法(forward-backward algorithm)的变体。 Graves 等人(2006)最初提出了用于 CTC 训练和推理的动态规划算法;Hannun(2017)则对这两种算法给出了更详细的解释。
15.5.3 融合 CTC 与编码器-解码器
我们还可以将前面介绍的两种架构(及其对应的损失函数)结合起来:即来自编码器-解码器架构的交叉熵损失与 CTC 损失。
图 15.16 展示了这种融合的示意图。 在训练阶段,我们可以简单地对两个损失加权求和,权重 $\lambda$ 在开发集上调整:
$$ L = -\lambda \log P_{\text{encdec}}(Y \mid \mathbf{X}) - (1 - \lambda) \log P_{\text{CTC}}(Y \mid \mathbf{X}) \tag{15.22} $$在推理阶段,也可以将两者与语言模型(或长度惩罚项)结合,同样使用学习得到的权重:
$$ \hat{Y} = \underset{Y}{\arg\max} \left[ \lambda \log P_{\text{encdec}}(Y \mid \mathbf{X}) + (1 - \lambda) \log P_{\text{CTC}}(Y \mid \mathbf{X}) + \gamma \log P_{\text{LM}}(Y) \right] \tag{15.23} $$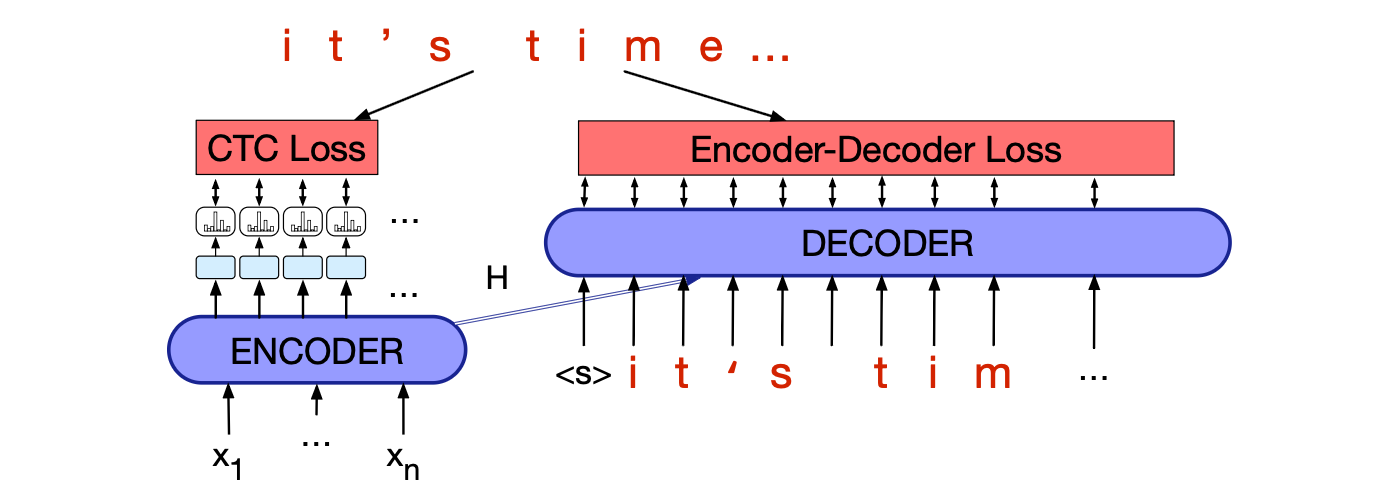
图 15.16 融合 CTC 与编码器-解码器损失函数的架构示意图。
15.5.4 流式模型:RNN-T 对 CTC 的改进
由于 CTC 做了很强的独立性假设(即假设时刻 $t$ 的输出与时刻 $t-1$ 的输出在给定输入条件下相互独立),基于 CTC 的识别器通常无法达到基于注意力机制的编码器-解码器识别器那样的高准确率。 然而,CTC 识别器有一个显著优势:它可用于流式识别(streaming)。 所谓流式识别,是指在用户说话过程中实时地逐词识别,而无需等到整句话说完才开始识别。 这对许多应用场景至关重要——无论是语音命令还是语音听写,我们都希望在用户仍在说话时就立即开始输出识别结果。 相比之下,基于注意力的算法必须先对整个输入序列计算完整的隐藏状态,才能为解码器提供用于注意力分布的上下文信息,之后解码器才能开始生成输出。 而 CTC 算法则可以立即从左到右逐帧输出字符,天然支持低延迟的流式处理。
如果我们希望实现流式识别,同时又想提升 CTC 的性能,就需要一种方法来打破其条件独立性假设,使其能够利用已生成的输出历史信息。 RNN-Transducer(RNN-T)正是为此设计的模型(Graves, 2012;Graves 等, 2013),如图 15.17 所示。 RNN-T 包含两个主要组件:一个类似 CTC 的声学编码器(acoustic encoder); 一个独立的预测器(predictor),作为语言模型组件,用于建模输出标记的历史依赖。 在每个时间步 $t$,声学编码器基于当前及之前的输入帧 $x_1, \dots, x_t$ 输出隐藏状态 $h^{\text{enc}}_t$。 预测器则接收此前已生成的非空白输出标记,输出其对应的隐藏状态 $h^{\text{pred}}_{u}$。 这两个隐藏状态随后被送入另一个网络,其输出再经过 softmax 层,用于预测下一个输出字符。
$$ \begin{align*} P_{\text{RNN-T}}(Y \mid \mathbf{X}) &= \sum_{A \in B^{-1}(Y)} P(A|\mathbf{X}) \\ &= \sum_{A \in B^{-1}(Y)} \prod_{t=1}^T p(a_t \mid h_t, y_{< u_t}) \end{align*} $$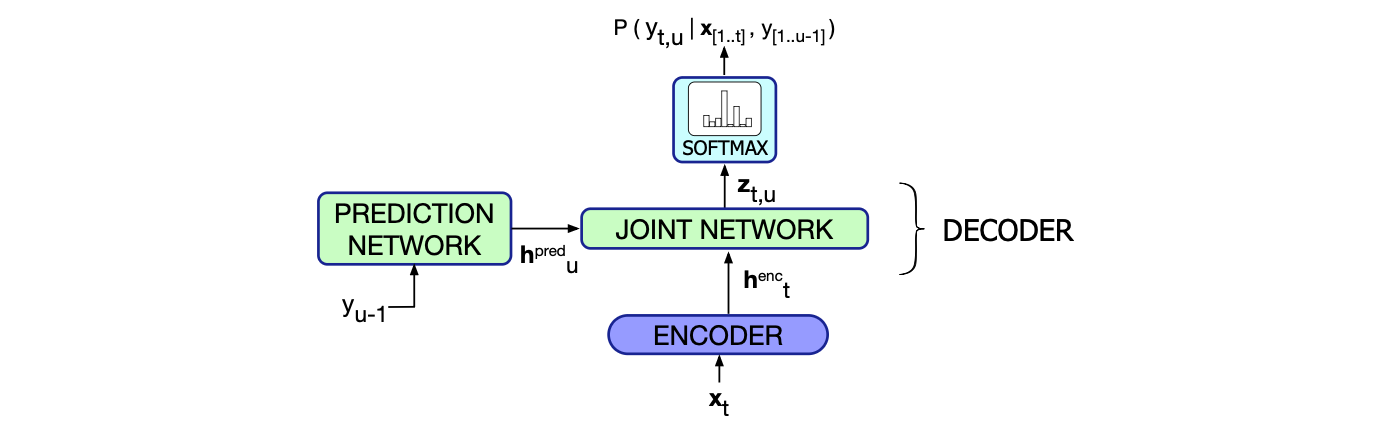
图 15.17 RNN-T 模型在时间步 $t$ 计算输出标记分布的方式:融合 CTC 声学编码器的输出与一个独立的“预测器”语言模型的输出。