除了编码器-解码器架构外,另一类重要的方法是自监督语音模型(self-supervised speech models)。 这类模型并不直接学习将声学输入映射为字母或标记序列。 相反,它们首先从声学信号中自举(bootstrap)出一组离散的音素单元,然后学习将原始波形映射到这些自动归纳出的单元上。 这一预训练阶段不需要转录文本,仅需未标注的语音文件即可。 完成预训练后,这些模型可以在较小规模的带标注数据集(即语音与其人工转录文本的配对)上进行微调,以执行 ASR 任务。 这种方法的优势在于:其大部分训练可以利用大量无转录文本的语音数据。
下面我们介绍一种典型的自监督模型——HuBERT(Hsu 等,2021)。 HuBERT 及其类似模型(如 wav2vec 2.0(Baevski 等,2020))借鉴了第10章所介绍的 BERT 等掩码语言模型的核心思想。 对输入的一部分进行掩码,并训练模型预测被掩码的内容。
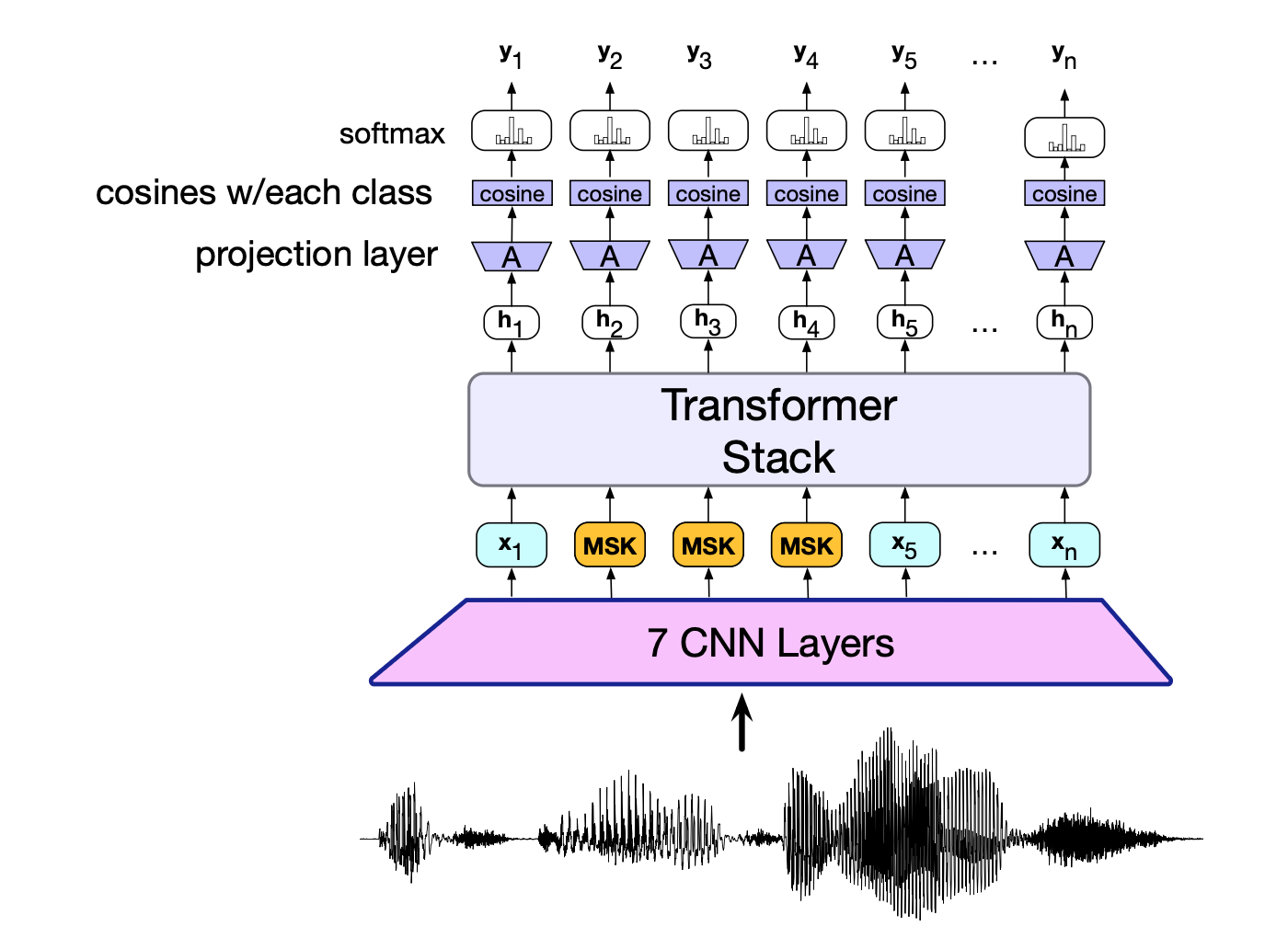
图 15.8 HuBERT 在训练阶段的推理流程示意图。 一个16 kHz的原始音频文件首先通过一系列卷积层;随后,部分帧被替换为一个 MASK 标记;接着,整个序列送入Transformer堆栈;最后通过一个线性层,将Transformer输出投影为输出嵌入。 该嵌入通过余弦相似度与 100(或 500)个音素类别的嵌入逐一比较,生成对应logits,再经 softmax 得到每个时间帧上各类别的概率分布。
15.4.1 HuBERT 的前向传播
我们首先描述 HuBERT 在训练时使用的前向传播过程,稍后再将其置于完整的训练上下文中(包括反向传播)。 如前所述,HuBERT 前向传播的输入是原始的 16 kHz 音频波形,其输出是在每个 20 毫秒时间帧上对一组归纳出的音素类别$C$ 的概率分布(类别数通常为 100 或 500,取决于训练阶段)。 图 15.8 展示了该流程的主要组件。 原始音频波形依次通过 7 层 512 通道的卷积层。这些层不仅学习提取频谱信息,还将输入序列压缩至每 20 毫秒一帧的速率;随后添加位置编码,并依次应用 GELU 激活函数和层归一化。 接着,部分时间帧被随机替换为一个特殊的 MASK 标记,这是一个可学习的嵌入向量,所有被掩码的帧共享同一个 MASK 嵌入。 整个序列被送入一个 Transformer 堆栈;Transformer 的输出再经过一个线性投影层 $\mathbf{A}$, 得到每个 20 毫秒帧的输出嵌入;该嵌入与 100(或500)个音素类别各自的嵌入向量计算余弦相似度,生成100(或500)个 logits,表示当前音频帧与每个类别的相似程度。 最后,这些 logits 经过 softmax 函数,转化为一个在所有音素类别上的概率分布。
15.4.2 HuBERT的学习过程
首先讨论如何诱导出作为训练目标的 100 或 500 个音素类别。 为了启动这些单元,HuBERT 最初使用梅尔频率倒谱系数(Mel Frequency Cepstral Coefficients, MFCC)向量,这是一个 39 维的特征向量,强调了信号中对于检测音素单位至关重要的方面。 这些向量可以从声学信号中提取,如第 14.6 节所述。 我们为整个声学训练数据集提取 MFCC 向量(最初的 HuBERT 实现使用了 960 小时的 LibriSpeech 数据,生成了大约 1.72 亿个向量)。 接下来,我们使用下面第 15.4.3 节描述的 k-means 聚类算法对这些 MFCC 向量进行聚类处理。 聚类意味着将向量分为 k 个类别。 聚类的结果是一个包含 $k$ 个向量的码本,称为码字或模板或原型,每个代表一个簇。 这 $k$ 个簇中的每一个都是我们可以用作训练黄金标准目标的声学单元。
现在考虑整个训练过程。 在声学输入通过 CNN 层之后,选择上下文窗口中的一段 token 进行掩码处理,这些标记的 CNN 输出被 MASK 嵌入所替代。 整个上下文窗口随后通过 Transformer 层,每一时间步 $t$ 处的 Transformer 输出 $h^L_t$ 乘以投影层矩阵 $\mathbf{A}$ 以将其映射到类别嵌入空间。 得到的表示形式然后与集合 $C$ 中的每个类别的嵌入(使用余弦相似度)进行比较,使用 softmax(温度参数 $\tau=0.1$)将相似度转化为概率:
$$ p(c|\mathbf{X},t) = \frac{exp(sim(\mathbf{Ah}_t, \mathbf{e}_c)/\tau)}{\sum^C_{c'=1} exp(sim(\mathbf{Ah}_t, \mathbf{e}_{c'})/\tau)} \tag{15.12} $$如图 15.9 所示,在这个前向传播的同时,输入波形会通过 MFCC 生成一个 39 维的向量,然后通过选择码本中最相似的质心映射到 100 个类别之一。 损失函数是所有被掩码的标记集 $M$ 上模型分配给这些正确单元的概率之和:
$$ L = \sum_{t \in M} \log p(z_t \mid \mathbf{X}) \tag{15.13} $$因此,类似于掩码语言建模,模型被训练用于预测与掩码帧相关的单元。 然后,该损失通过模型反向传播。
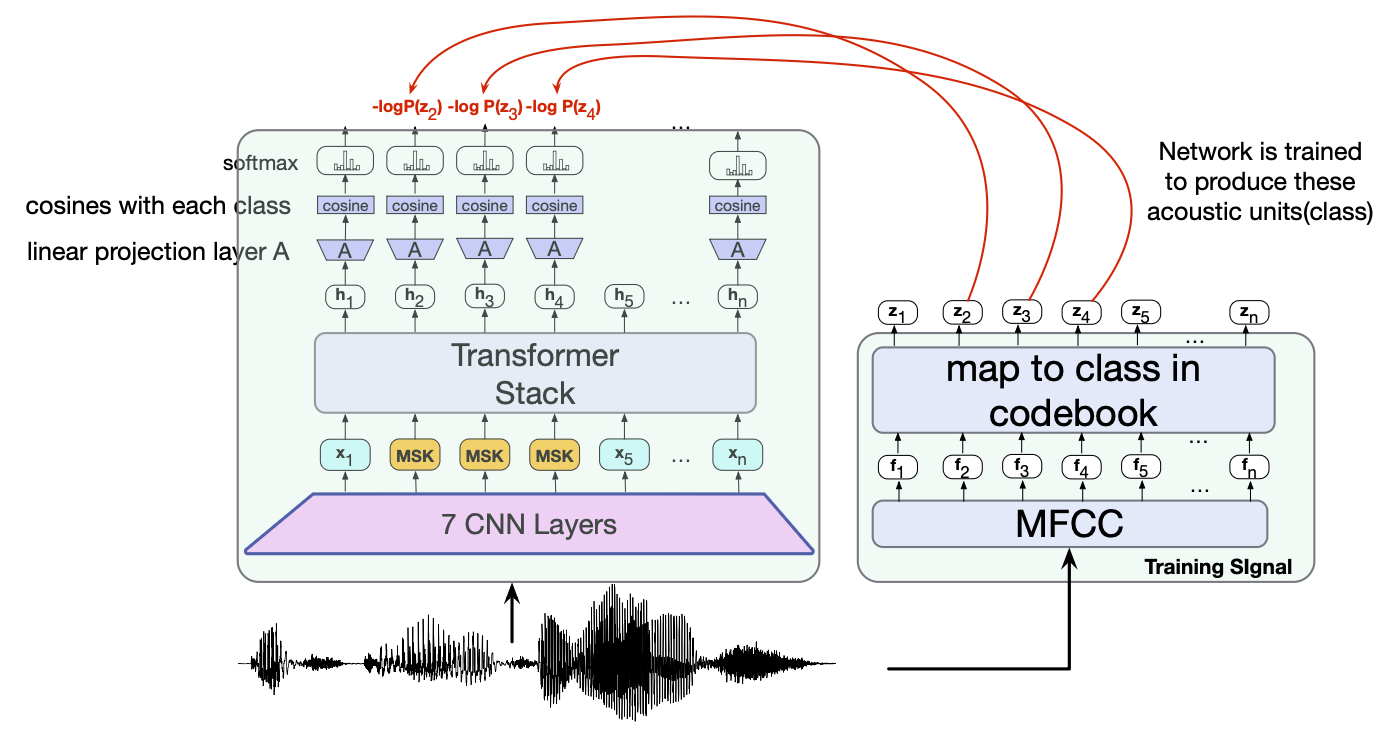
图15.9 HuBERT训练的第一阶段。 使用由 39 维MFCC向量组成的 100 个单元(定义为簇)作为训练目标。 对于每个时间步 $t$,计算该类别的概率,并使用 log 概率作为损失。
一旦模型初步训练完成,能够映射到MFCC向量质心后,就会进入第二个训练阶段,此时我们采用模型产生的表示,将它们聚类成500个簇,并使用这些簇作为新的训练目标。 原理是初始的 MFCC 簇使模型偏向于音素表示,但在经过足够的训练后,模型将会学习到更加精确和细致的表示。 图 15.10 展示了这一原理。
在 HuBERT 预训练完成后,移除投影和余弦层,并添加一个随机初始化的线性 + softmax 层,针对 ASR 任务映射至29个类别(对应于 26 个英文字母及几个额外字符)。 CNN部分被冻结,而模型的其余部分则使用 CTC 损失函数(将在第 15.5 节中介绍)进行微调,以适应 ASR 任务。
15.4.3 K-均值聚类
在本节中,我们将更正式地介绍K-均值聚类算法。 K-均值是一系列算法,用于将一组向量数据分组为 k 个簇。 每当我们想要以相同方式处理一组元素时,聚类就非常有用。 在语音处理中,每当我们需要将一组实数值向量转换为一组离散符号时,它就非常常用。 除了在这里 HuBERT 中的应用外,我们还将在第 16 章中回到这个话题,作为一种为 TTS 创建离散声学标记的算法。
我们通常使用 K-均值这个名字来指代该系列算法的一个简单版本:一个两步迭代算法,给定一组 $N$ 个向量 $\mathbf{v}^{(1)}..\mathbf{v}^{(N)}$,每个向量有 $d$ 维,即 $\forall i, \mathbf{v}^{(i)} \in \mathbb{R}^d$,以及一个常数 $k$,这里通常 $N > > k$。
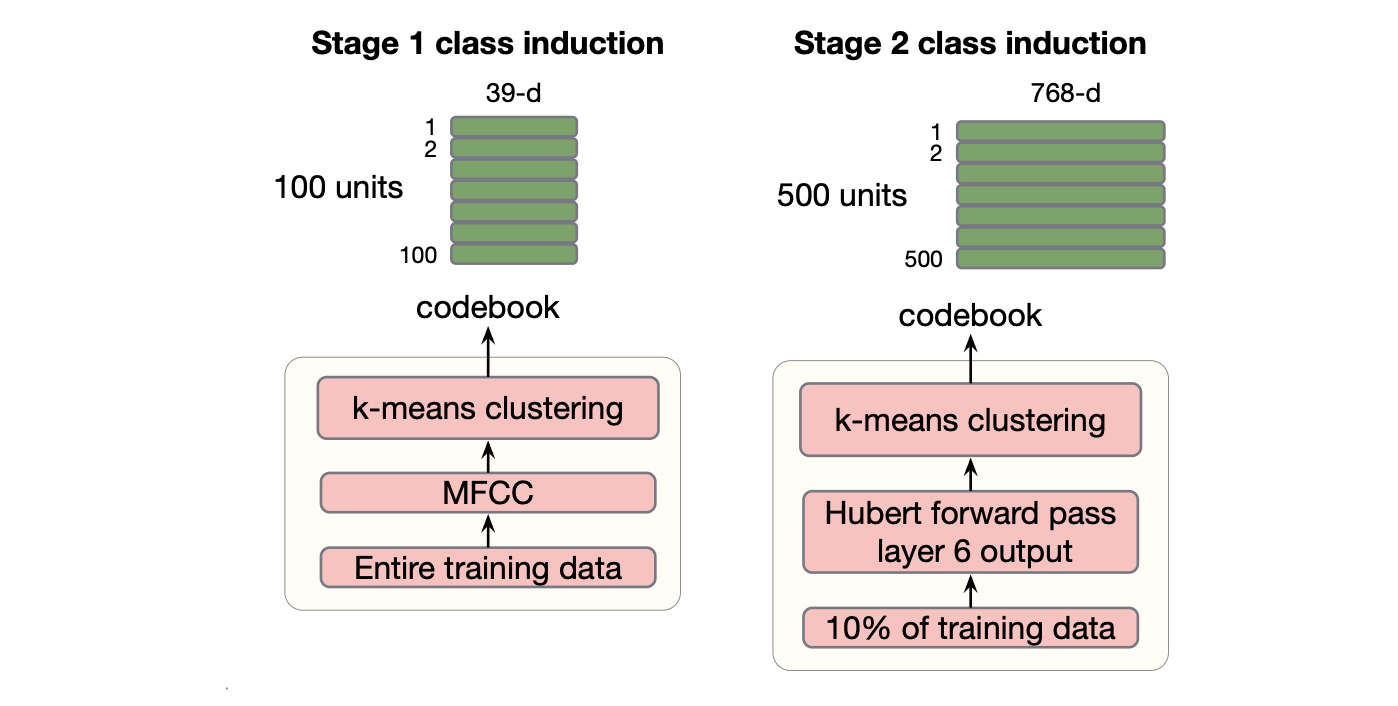
图15.10 创建两个阶段的HuBERT训练目标。 在第一阶段,计算整个训练数据的 39 维 MFCC 向量,然后用 k-means 进行聚类,创建了100个声学单元。 在第二阶段,将训练数据的一个子样本经过第一阶段训练后的 HuBERT 模型,取中间Transformer层(第6层)的输出,并用 k-means 进行聚类,从而创建 500 个单元。
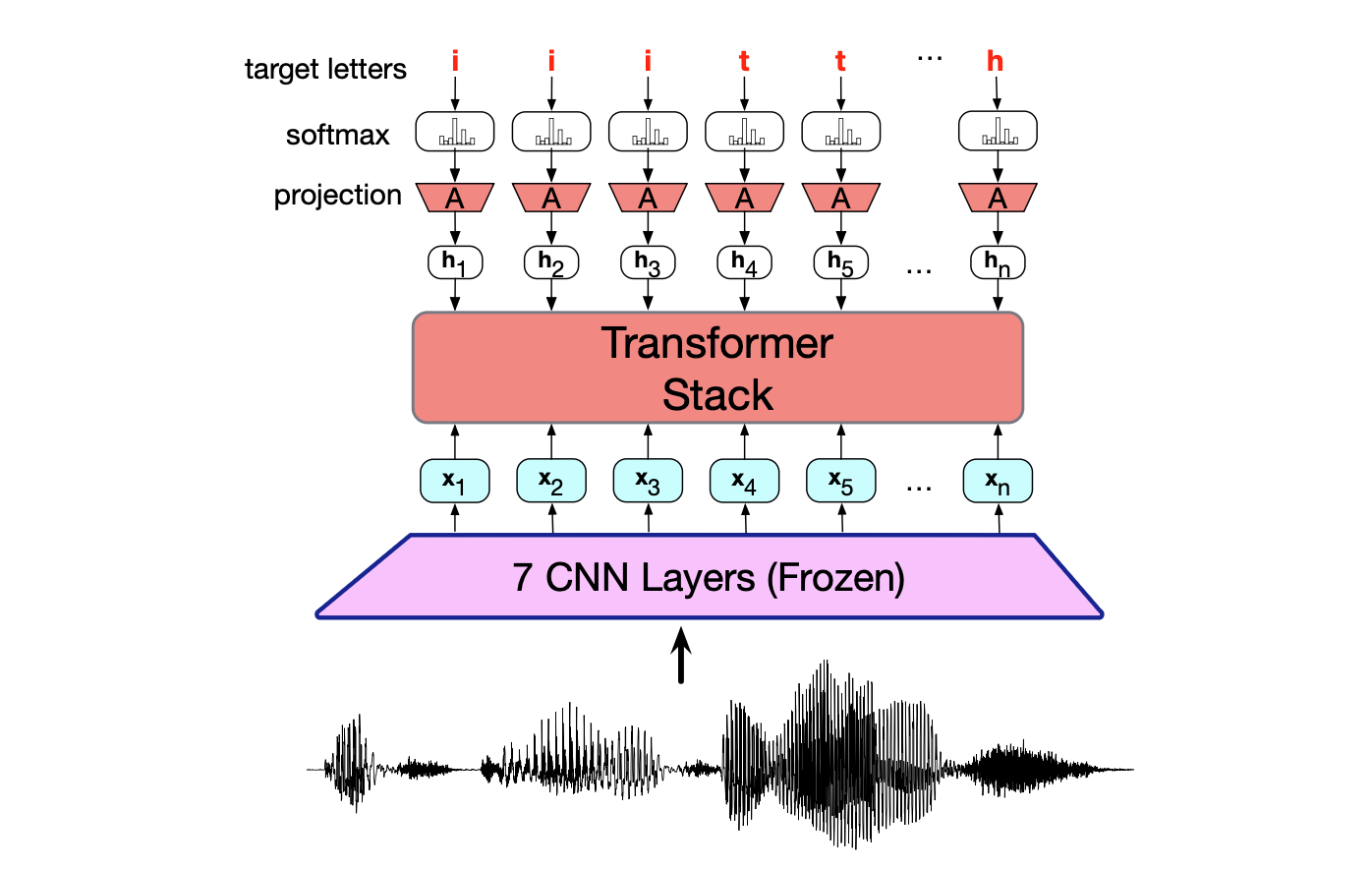
图15.11 预训练之后的 HuBERT 微调过程。 移除投影层和余弦步骤,仅保留一个随机初始化的投影/softmax 层。 CNN 层被冻结,而模型的其余部分则在一个带有转录文本的音频数据集上进行微调,使用 CTC 损失(第15.5节)训练以产生字母作为输出。 微调过程中更新的参数以红色显示(投影层和Transformer堆栈)。
该两步算法迭代更新一组 $k$ 个质心(centroid)向量。 所谓质心,是指 $n$ 维空间中一组点的几何中心。
该算法包含两个步骤。 分配步骤(Assignment step):给定当前的 $k$ 个质心和一个向量数据集,将每个向量分配给与其码字(codeword)最近的簇(以平方欧氏距离衡量)。 重估计步骤(Re-estimation step):通过重新计算每个簇内所有向量的均值,来更新该簇的码字。 注意,所得的均值向量不一定是原始数据集中的某个实际点。 算法在这两个步骤之间反复迭代,直至收敛。
具体算法如下:
初始化:为每个簇 $k$ 随机选择一个向量 $\mu_k \in \mathbb{R}^d$ 作为该簇的码字(也称为模板或原型)。 最终得到一个码本(codebook),其中包含 $k$ 个簇各自对应的码字。
然后重复以下步骤直至收敛:
- 分配(Assignment):对于数据集中的每个向量 $\mathbf{v}^{(i)}$,将其分配给 $k$ 个簇中码字 $\mu$ 最近的那个簇。 最简单的方式是将“最近”定义为具有最小平方欧氏距离的簇:
其中 $\|v\|$ 表示向量 $\sum_{j=1}^d (v_j^{(i)} - \mu_{j})^2$ 的 $L_2$ 范数。
- 重估计(Re-estimation):通过重新计算每个簇中所有向量的均值(即质心),来更新该簇的码字。 若 $S_i$ 表示第 $i$ 个簇中所有向量的集合,则: