我们将介绍的第一种自动语音识别(ASR)架构是编码器-解码器架构,这与第 12 章中为机器翻译(MT)引入的架构相同。 图 15.5 描绘了这种架构,被称为基于注意力的编码器解码器或简称AED,或者根据首次将其应用于语音的两篇论文中的名称,称为聆听、注意和拼写(LAS)(Chorowski等人,2014;Chan等人,2016)。
该架构的输入是一个包含 $t$ 个声学特征向量的序列 $\mathbf{X} = (\mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_t)$,其中每个向量对应于一个 10 毫秒的语音帧。 我们通常从上一节描述的对数梅尔频谱特征开始,尽管也可以直接从原始 wav 文件开始处理。 输出序列 $Y$ 可以是字母或标记(BPE或sentencepiece),为了简化解释,这里假设是字母。 因此,输出序列 $Y = (\langle \text{SOS} \rangle, y_1, \dots,y_m, \langle \text{EOS} \rangle)$,其中假设有特殊的序列起始和结束标记 $\langle \text{SOS} \rangle$ 和 $\langle \text{EOS} \rangle$,且每个 $y_i$ 都是一个字符;对于英语,我们可能会选择如下集合:
$$ y_i \in {a, b, c, \dots, z, 0, \dots,9, \langle \text{space} \rangle, \langle \text{comma} \rangle, \langle \text{period} \rangle, \langle \text{apostrophe} \rangle, \langle \text{unk} \rangle } $$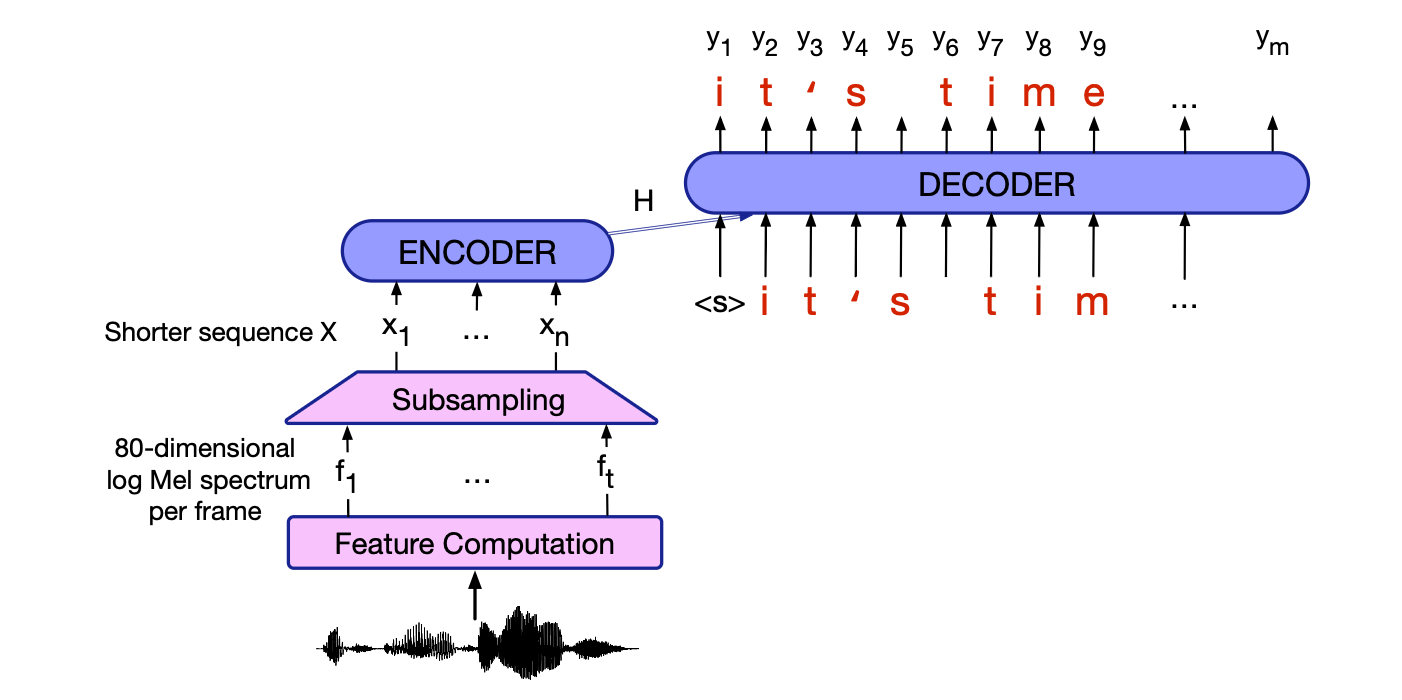
图 15.5 编码器-解码器语音识别器的架构示意图。
这种架构也被 OpenAI 的 Whisper 模型所使用(Radford 等人,2023)。 图15.6展示了 Whisper 架构的一部分(Whisper 还执行其他语音任务,如语音翻译和语音活动检测,我们将在下一章讨论)。 虽然Whisper的模型和推理代码已公开发布,但训练代码和训练数据并未公开。 然而,有一些开源项目使用了类似于 Whisper 的架构,比如开放 Whisper 风格的语音模型(OWSM),它重现了 Whisper 风格的训练,但提供了一个完全开源的工具包和公开可用的数据集(Peng等人,2023)。
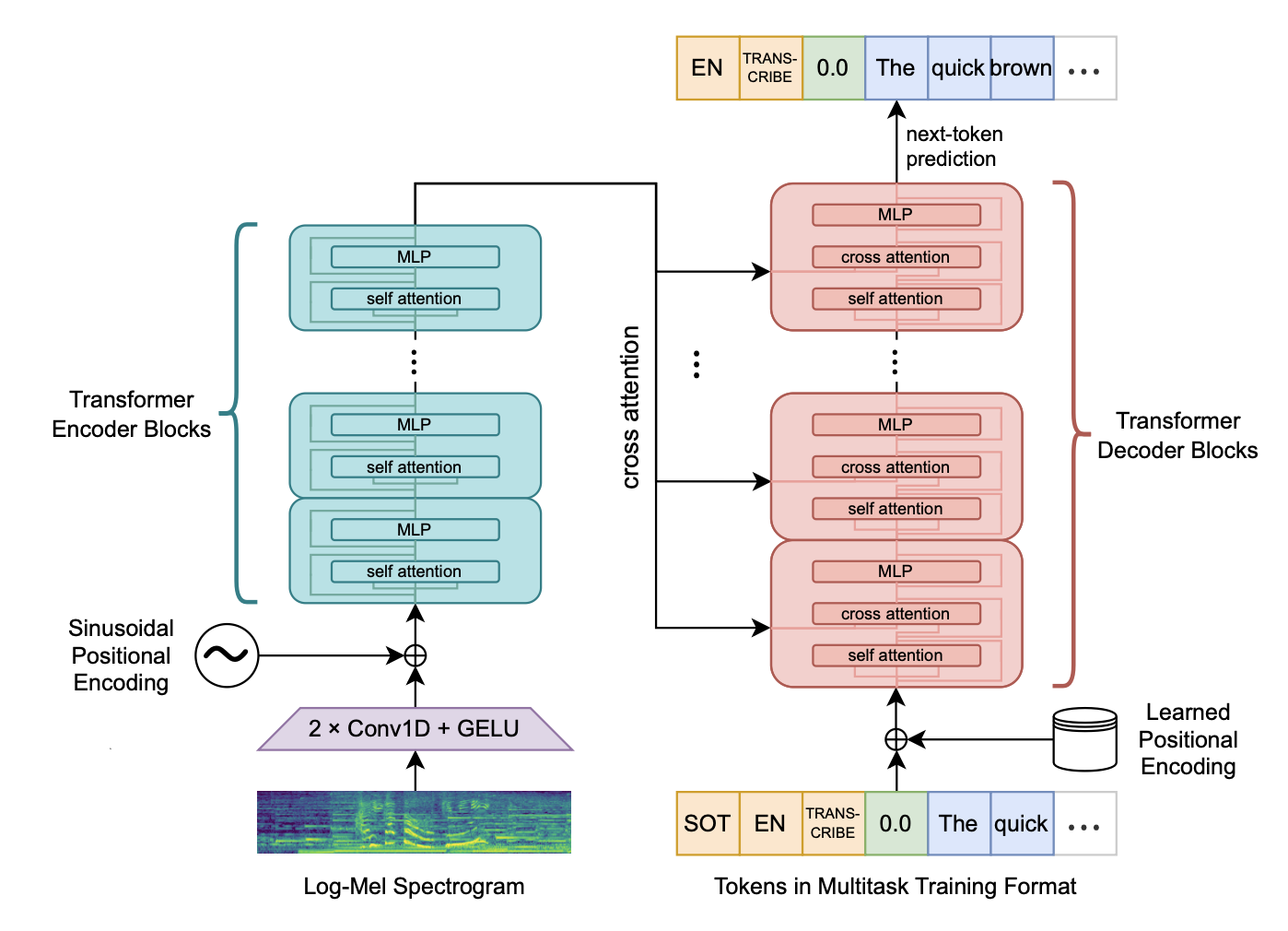
图 15.6 来自 Radford 等人(2023)的 Whisper 架构简图。由于 Whisper 是一个多任务系统,也进行翻译和说话人分离(我们将在接下来的一章中讨论这些非ASR任务),Whisper 的转录格式包含了一个转录开始(SOT)标记、一个语言标签以及指示是进行转录还是翻译的指令标记。
15.3.1 输入与卷积层
当输入序列与输出序列长度差异显著时,编码器-解码器架构尤为适用,语音任务正是如此:长的声学特征序列需映射为短得多的字母或词序列。 例如,在英语中,单词平均包含 5 个字母或 1.3 个BPE标记(Bostrom 与 Durrett,2020);而在自然对话中,一个单词平均持续约 250 毫秒(Yuan 等,2006),相当于 25 个 10 毫秒的帧。 因此,以 10 毫秒帧表示的语音信号,其长度大约是文本信号(以词或标记计)的 5 倍(25/5)到 19 倍(25/1.3)。
由于语音任务中的这种长度差异极为显著,语音领域的编码器-解码器架构通常会在编码器之前设置一个压缩阶段,用于缩短声学特征序列。 (此外,我们还可以配合使用专为处理压缩设计的损失函数,例如稍后将介绍的CTC损失函数。)
压缩的目标是生成一个更短的序列 $\mathbf{X} = (\mathbf{x}_1, \dots, \mathbf{x}_n)$,作为后续 Transformer 编码器的输入。 一种非常简单的基线方法有时被称为低帧率(low frame rate)(Pundak 与 Sainath,2016):在时间步 $i$,将当前声学特征向量 $f_i$ 与前两个向量 $f_{i-1}$ 和 $f_{i-2}$ 拼接(concatenate),形成一个长度为原先三倍的新向量。 然后直接丢弃 $f_{i-1}$ 和 $f_{i-2}$。 这样一来,原本每 10 毫秒一个 40 维的声学特征向量,就变成了每 30 毫秒一个 120 维的向量,序列长度也相应缩短为 $n = t / 3$。
然而,目前最常用的方法是使用我们在上一节介绍的卷积层。 当卷积层的步幅大于 1 时,输出序列就会比输入序列更短。下面以两个常用的 ASR 系统为例说明这一点。
Whisper 系统(Radford 等,2023)采用 30 秒的音频上下文窗口。 它对每一帧提取 128 通道的对数梅尔特征,窗长为 25 毫秒,帧移(stride)为 10 毫秒。 这些特征随后被归一化至均值为 0、取值范围为 $[-1, 1]$。 由于帧移为 10 毫秒(即每秒 100 帧),30 秒的上下文窗口共包含 3000 个输入帧。 这 3000 帧依次通过两个卷积层,每层后接一个非线性激活函数(Whisper使用GELU,即高斯误差线性单元,它是 ReLU 的一种平滑版本)。 第一个卷积层有 128 个输入通道,步幅为 1,输出通道数等于模型维度,输入序列长度为 3000。 第二个卷积层的输入和输出通道数均为模型维度,步幅为 2。 该层的步幅 2 使输出序列长度减半,降至 1500,相当于每 20 毫秒生成一个音频标记。 在将前端输出送入Transformer编码器之前,会为其加上正弦位置嵌入(sinusoidal position embeddings)。
HuBERT(Hsu 等,2021)则采用另一种前端架构:它完全用卷积层替代了传统频谱计算过程。 其输入是原始 16 kHz 采样的音频波形,依次通过七层卷积,每层均有 512 个通道,步幅序列为 $[5,2,2,2,2,2,2]$,核宽序列为 $[10,3,3,3,3,2,2]$。 这些卷积层既能学习提取频谱信息,又能将输入序列压缩 320 倍,从 16 kHz(即每 0.0625 毫秒一个样本)降至每 20 毫秒一个表示。 在送入 Transformer 编码器前,会先添加位置编码,再依次应用 GELU 激活函数和层归一化(layer norm)。
15.3.2 推理
在卷积阶段之后,语音领域的编码器-解码器采用与机器翻译(MT)相同的架构(即带交叉注意力的Transformer)。
让我们回顾一下第 12 章介绍的编码器-解码器架构。 它包含两个 Transformer 模块:一个编码器和一个解码器。其中,编码器与第8章所述的基础Transformer相同;而解码器则多了一个新组件:交叉注意力层(cross-attention layer)。 编码器接收声学输入 $\mathbf{X} = (\mathbf{x}_1, \dots, \mathbf{x}_n)$,并通过若干编码器块将其映射为输出表示 $\mathbf{H}^{\text{enc}} = (\mathbf{h}_1, \dots, \mathbf{h}_n)$。
解码器本质上是一个条件语言模型,它关注编码器的表示,逐个生成目标文本(字母或标记),即在每个时间步同时依赖两方面信息:一是来自编码器的音频表示,二是此前已生成的文本,从而预测下一个字母或标记。
解码器中的 Transformer 块包含一个额外的层,即交叉注意力(cross-attention)。 其形式与标准 Transformer 块中的多头注意力相同,但有一个关键区别:查询(queries)仍如常来自解码器的前一层,而键(keys)和值(values)则来自编码器的输出。
具体来说,在标准多头注意力中,每个注意力层的输入都是 $\mathbf{X}$;而在交叉注意力中,输入是编码器的最终输出 $\mathbf{H}^{\text{enc}} = (\mathbf{h}_1, \dots, \mathbf{h}_n)$。 $\mathbf{H}^{\text{enc}}$ 的形状为 $[n \times d]$,每一行对应一个声学输入标记。
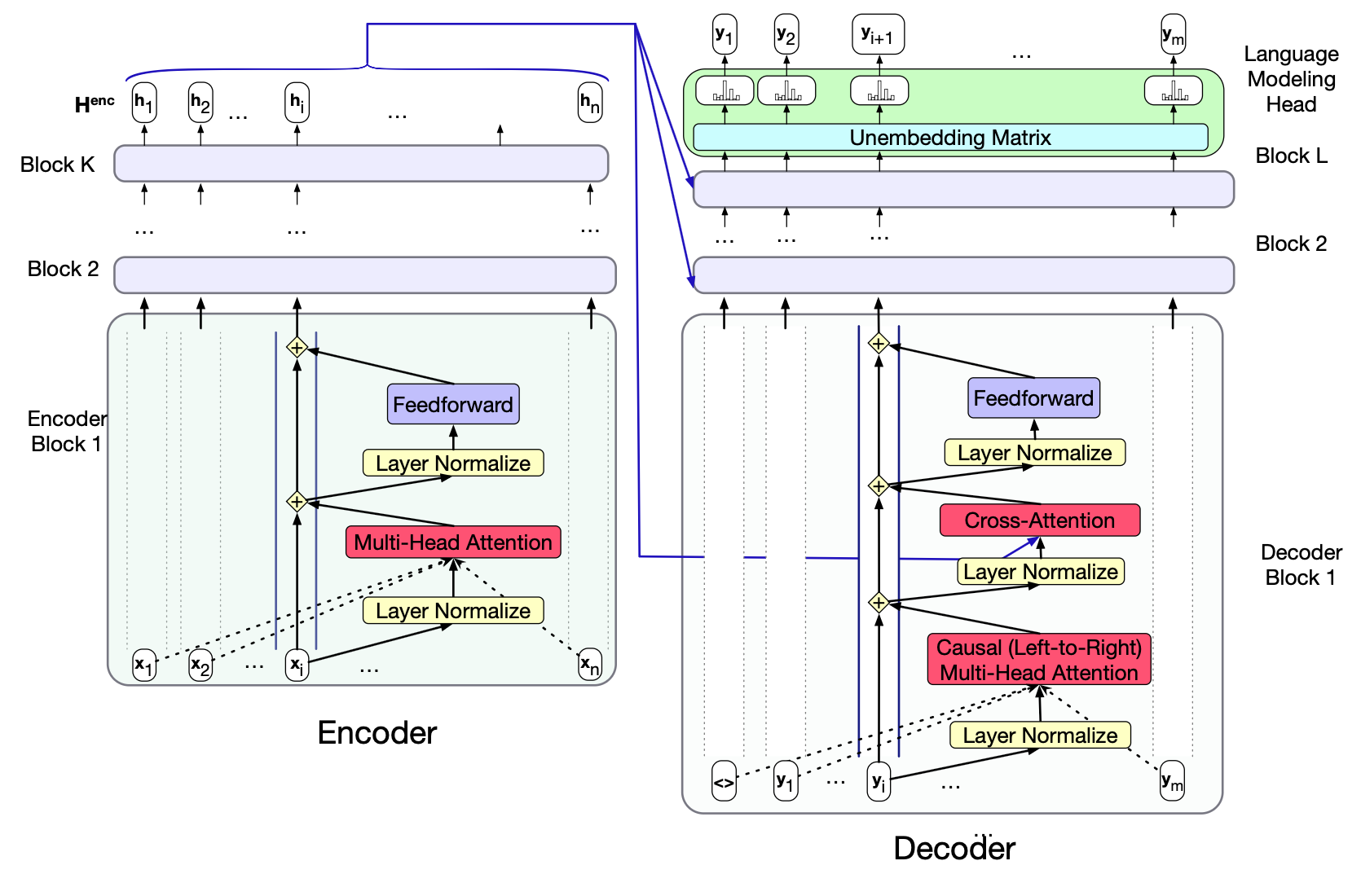
图 15.7 编码器与解码器的 Transformer 块结构(以残差流视角展示)。编码器的最终输出 $\mathbf{H}^{\text{enc}} = (\mathbf{h}_1, \dots, \mathbf{h}_n)$ 作为上下文信息供解码器使用。解码器本质上是一个标准Transformer,只是额外增加了一层交叉注意力层,该层接收编码器输出 $\mathbf{H}^{\text{enc}}$,并用它来构造键($\mathbf{K}$)和值($\mathbf{V}$)。
为了将编码器输出中的键和值与解码器前一层的查询关联起来,我们用交叉注意力层的键权重 $\mathbf{W^K}$ 和值权重 $\mathbf{W^V}$ 分别与编码器输出 $\mathbf{H}^{\text{enc}}$ 相乘。 查询则来自解码器前一层的输出 $\mathbf{H}^{\text{dec}}[\ell-1]$(注:此处原文误写为 $\mathbf{H}^{\text{enc}}[\ell-1]$,应为解码器状态),并乘以交叉注意力层的查询权重 $\mathbf{W^Q}$:
$$ \begin{align*} Q &= \mathbf{H}^{\text{dec}}[\ell-1] \mathbf{W^Q}; \\ K &= \mathbf{H}^{\text{enc}} \mathbf{W^K}; \\ V &= \mathbf{H}^{\text{enc}} \mathbf{W^V} \tag{15.4} \end{align*} $$$$ \text{CrossAttention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \tag{15.5} $$因此,交叉注意力使解码器能够关注整个编码器最终输出所表示的声学输入。 每个解码器块中的另一层注意力——多头注意力层——与第8章所述的因果(从左到右)注意力相同。 而编码器中的多头注意力则可以“看到”整个源语言序列,因此不使用掩码。
在推理阶段,输出字符串 $y$ 的概率被分解为:
$$ p(y_1, \dots, y_n) = \prod_{i=1}^n p(y_i \mid y_1, \dots, y_{i-1}, \mathbf{X}) \tag{15.6} $$我们可以采用贪心解码逐个生成输出字符:
$$ \hat{y}_i = \mathop{\arg\max}_{\text{char} \in \text{Alphabet}} P(\text{char} \mid y_1, \dots, y_{i-1}, X) \tag{15.7} $$不过,像 Whisper 或 OWSM 这样的编码器-解码器系统通常也会采用下节将介绍的束搜索(beam search)。这一点在引入语言模型时尤为重要。
引入语言模型
由于编码器-解码器模型本质上是一个条件语言模型,它会从训练数据中隐式地学习输出域(如字母序列)的语言模型。
然而,训练数据(即语音与其转录文本的配对)可能并不包含足够多的纯文本,难以训练出一个高质量的语言模型。
毕竟,获取海量纯文本数据远比获取语音-文本对容易得多。因此,我们通常可以通过融合一个大型语言模型来略微提升系统性能。
最简单的方法是:先用束搜索生成一组候选句子,这个候选集有时称为 n-best 列表(n-best list)。 然后,我们用一个外部语言模型对列表中的每个假设进行重打分(rescore)。 重打分通过插值实现:将语言模型给出的分数与生成该候选集时编码器-解码器的原始分数加权结合,权重 $\lambda$ 在开发集上调整。 此外,由于大多数模型倾向于生成较短的句子,ASR 系统通常会引入某种长度归一化机制。 一种常见做法是将概率按假设中的字符数 $|Y|_c$ 进行归一化。 以下是“聆听、注意和拼写”(Listen, Attend and Spell)系统所采用的打分函数(Chan 等,2016):
$$ \text{score}(Y \mid \mathbf{X}) = \frac{1}{|Y|_c} \log P(Y \mid \mathbf{X}) + \lambda \log P_{\text{LM}}(Y) \tag{15.8} $$15.3.3 训练
语音领域的编码器-解码器模型通常采用条件语言模型常用的标准交叉熵损失(cross-entropy loss)进行训练。 在解码的第 $i$ 个时间步,损失为正确标记(字母)$y_i$ 的对数概率:
$$ L_{\text{CE}} = -\log p(y_i \mid y_1, \dots, y_{i-1}, \mathbf{X}) \tag{15.9} $$整个句子的损失是各时间步损失之和:
$$ L_{\text{CE}} = -\sum_{i=1}^{m} \log p(y_i \mid y_1, \dots, y_{i-1}, \mathbf{X}) \tag{15.10} $$该损失随后通过整个端到端模型反向传播,用于联合训练编码器和解码器。
正如第 12 章所述,我们通常使用教师强制(teacher forcing)策略:在训练时,解码器的历史输入被强制设为真实的参考序列 $y_i$,而非模型自身预测的 $\hat{y}_i$。 此外,也可以采用真实标签与模型预测的混合策略。例如,90% 的情况下使用真实标签,而以 10% 的概率使用模型上一步的预测输出:
$$ L_{\text{CE}} = -\log p(y_i \mid y_1, \dots, \hat{y}_{i-1}, \mathbf{X}) \tag{15.11} $$如今的训练数据规模已非常庞大。 例如,Whisper-v2 的训练语料包含 68万小时 的语音数据,其中大部分为英语,但也包括来自其他96种语言的 11.8万小时 多语言数据。 数据质量至关重要,因此那些从网络爬取数据用于训练的系统会采用多种方法剔除由ASR自动生成的转录文本,例如过滤掉全部为大写或全部为小写的文本。 开源的 OWSM 系统则在 18万小时 的语音数据上进行训练,主要使用人工转录的公开可用数据,包括 LibriSpeech、多语言 LibriSpeech、Common Voice、FLEURS、Switchboard、AMI 等语料库;具体细节参见 Peng 等人(2023)。