卷积神经网络,或 CNN(有时简称为 convnet),是一种特别适用于语音和视觉应用中提取特征的网络架构。 语音中的卷积层将音频输入(可以是原始音频或梅尔频谱)作为输入,并输出一系列输入语音的潜在表示。 在像 Whisper、wav2vec2.0 或 HuBERT 这样的 ASR 系统中,卷积层被堆叠为初始层集,用于生成传递给 transformer 层的语音表示。
标准前馈层是全连接的;每个输入都连接到每个输出。 相比之下,卷积网络利用了“核”这一概念,即我们通过输入传递的一种小型网络。 例如,在图像分类任务中,我们将核水平和垂直地在图像上移动以识别视觉特征,因此将这种视觉网络描述为 2D(二维)卷积网络。 对于语音,我们将沿着时间维度滑动核以提取语音特征,因此语音的 CNN 是 1D 卷积网络。
我们更深入地探讨一下这个原理。 我们将从一个非常简化的卷积层版本开始,它接受单个向量序列 $\mathbf{x}_1 \cdots \mathbf{x}_t$ 作为输入,并产生相同长度 $t$ 的单个向量序列 $\mathbf{z}_1 \cdots \mathbf{z}_t$ 作为输出。 之后我们将看到如何处理更复杂的输入和输出。
CNN 使用一个核,这是一个小的权重向量 $\mathbf{w}_1 \cdots \mathbf{w}_k$,用来提取特征。 它是通过将这个核与输入进行卷积来实现的。 核与信号的卷积包含三个步骤:
- 将核左右翻转。
- 在输入上逐帧(按时间顺序)通过核。
- 在每一帧计算核与局部输入值的点积。
- 输出是这些点积的结果序列。
我们可以把卷积过程看作是在信号中找到与核相似的区域,因为当两个向量相似时,它们的点积会很高。 卷积操作用 * 符号表示(这是对这个符号的不幸重载,它也指简单的乘法)。 我们看看如何计算 $\mathbf{x} * \mathbf{w}$,即单个向量 $\mathbf{x}$ 与核向量 $\mathbf{w}$ 的卷积。首先考虑宽度为 1 的简单情况。 计算每个输出元素 $\mathbf{z}_j$ 作为核与 $\mathbf{x}_j$ 的乘积:
$$ \text{宽度为 1 的卷积}:\mathbf{z}_j = \mathbf{x}_j\mathbf{w}_1, \forall j : 1 \leq j \leq t \tag{15.1} $$图 15.2 展示了这种计算的直观理解。
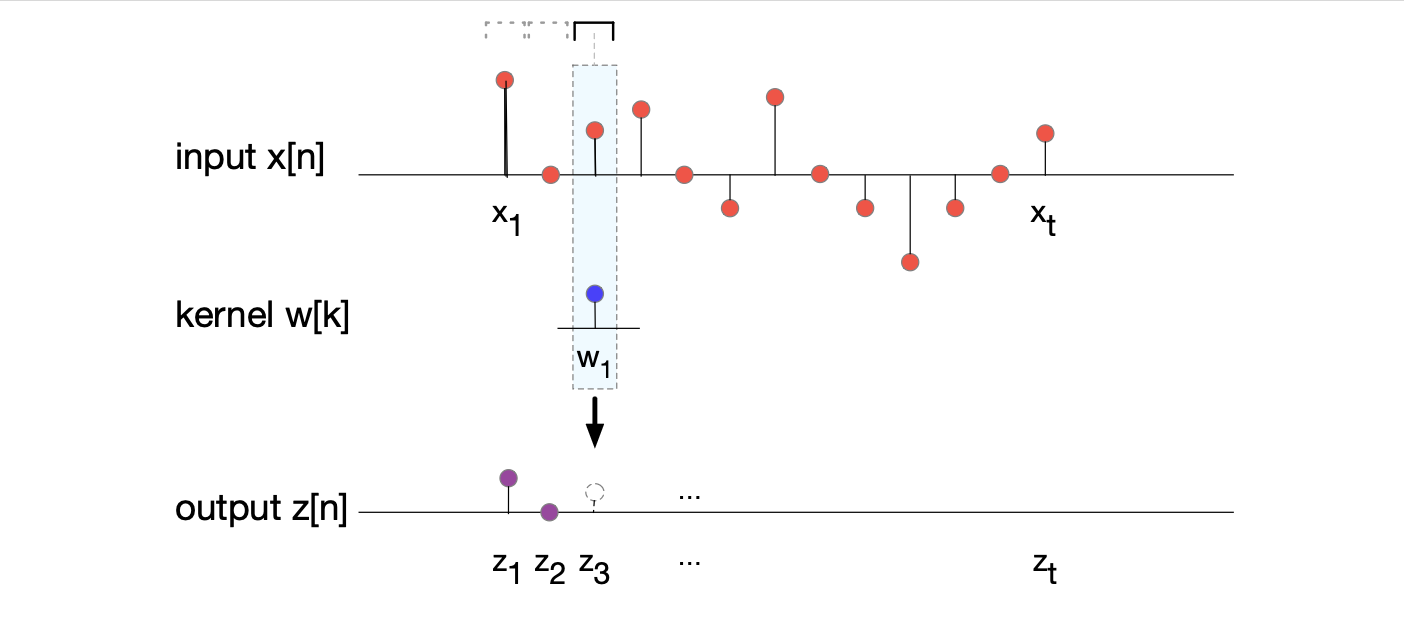
图 15.2 展示了宽度为 1 的核(滤波器)$\mathbf{w}$ 的卷积示意图。 核在整个输入上移动,每帧的输出 $\mathbf{z}_i$ 是核与输入帧的点积。 使用长度为 1 的核时,我们不需要担心翻转核的问题,点积就是标量乘积。 该图显示了 $\mathbf{z}_3$ 的计算方法,即 $\mathbf{x}_3 \times \mathbf{w}_1$。
现在我们来看更长的核。
虽然前面我们将卷积的第一步描述为“翻转核”,但实际上,在 ASR 系统(或像 PyTorch 这样的组件库)中,我们通常跳过这一步。从
技术上讲,这意味着我们实际使用的算法并不是真正的卷积,而是互相关(cross-correlation)。
互相关的定义是:将一个核在信号上滑动,并逐帧计算其与局部信号的点积,但不先翻转核。
不过,这种区别并不重要。因为在训练过程中,核的参数是通过学习得到的,模型完全可以轻松学会按任意顺序排列这些参数。
尽管如此,出于历史原因,我们仍然称这一过程为一维卷积,而非互相关。
下面我们来看适用于更长核的一般化公式。 为了避免卷积在信号左右边缘处未定义,我们可以在信号的开头和结尾各添加少量零值,这个操作称为填充(padding)。设填充长度为 $ p $,这样我们就可以让核的中心对准第一个输入元素 $\mathbf{x}_1$,并且在 $\mathbf{x}_1$ 左侧也有一个定义好的值(即 0)。 这样做还有一个好处:可以方便地使输出序列长度与输入序列长度保持一致。 为了实现这一点,通常将核向量的长度设为奇数,即 $k = 2p + 1$,这样核就有一个明确的中心元素,其左右各有 $p$ 个元素。 此时,输出向量 $\mathbf{z}$ 的每个元素 $\mathbf{z}_j$ 可按如下点积公式计算:
$$ \mathbf{z}_j = \sum_{i=-p}^{p} \mathbf{x}_{j+i} \, \mathbf{w}_{i+p} \tag{15.2} $$图 15.3 展示了宽度为 3 的核进行卷积 $\mathbf{x} * \mathbf{w}$ 的计算过程。其中,在 $ \mathbf{x} $ 的开头和结尾各填充了1帧零值。
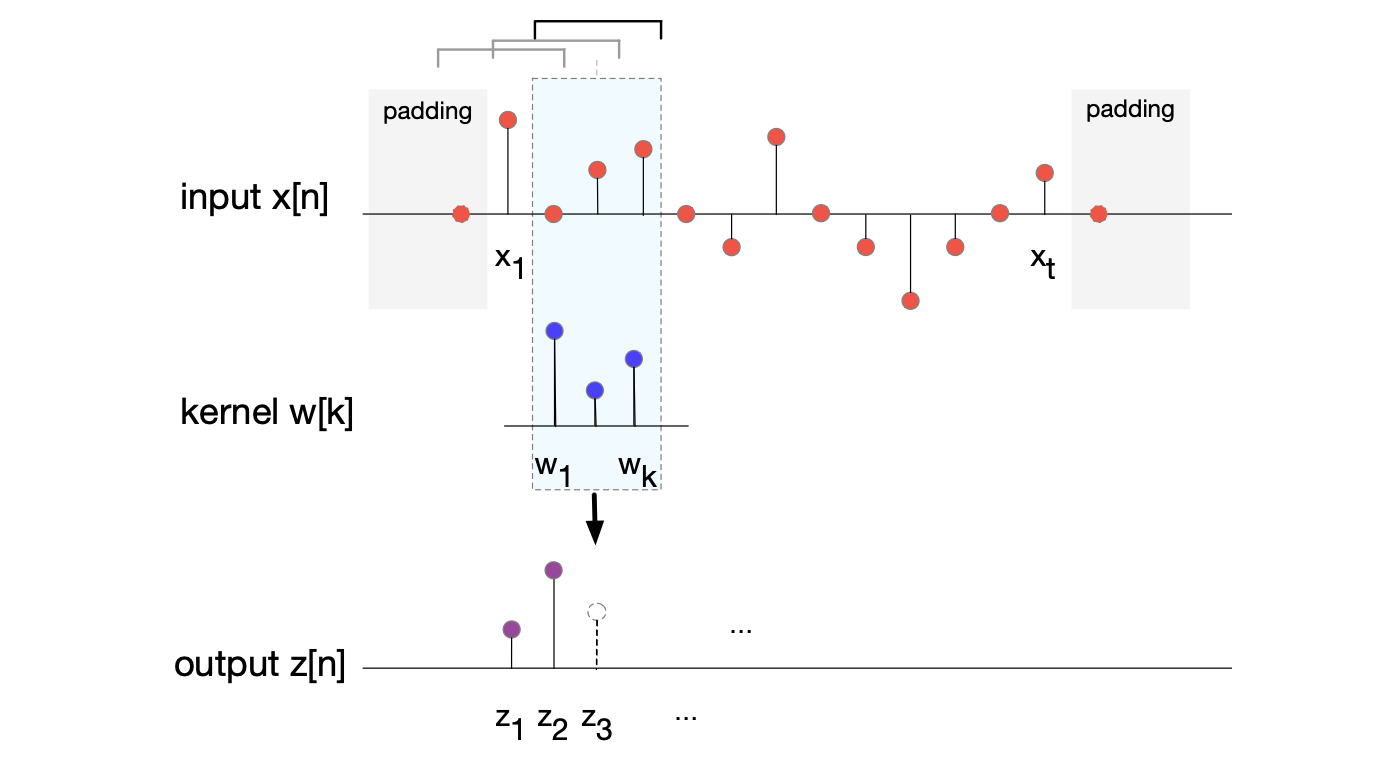
图 15.3 展示了核(滤波器)宽度为 3、填充为 1 的卷积示意图。信号首尾各添加了一个零值。 核(图中已按惯例视为翻转后的形式)在输入上滑动,每帧输出 $\mathbf{z}_i$ 是核与当前窗口内输入的点积。 图中具体展示了 $\mathbf{z}_3$ 的计算过程。
注意,核的大小 $k$(即感受野,receptive field)被设计得远小于整个信号长度。 例如,在 Whisper 的卷积层中,核宽度为 3 帧,意味着核是一个长度为 3 的向量(我们说该核的感受野为 3)。 也就是说,每个核会与连续3帧语音进行比较。 在 Whisper 中,每帧间隔 10 毫秒,而每帧本身代表 25 毫秒的语音信息窗口。 因此,每个核实际上覆盖约 40 毫秒的语音(10 + 10 + 12.5 + 12.5)。 这个时间跨度足以提取多种语音学特征,例如共振峰过渡、塞音闭合段或送气段等。
我们前面描述的是卷积的一种简化视图:输入是一个向量 $\mathbf{x}$,输出也是一个向量 $\mathbf{z}$,二者都对应于一个随时间变化的信号。 在实际应用中,卷积层的输入通常是来自对数梅尔频谱(log mel spectrum)的输出。这意味着输入包含多个通道(例如128个),每个通道对应一个对数梅尔滤波器的输出。 相应地,核也会为每个输入通道分别设置一组权重向量。 我们称该核具有深度(depth)128,即其形状为 $[128, 3]$(128个通道,每通道宽度为3)。
为了得到该核的输出,我们需要对所有输入通道的结果求和。 具体来说,先对每个输入通道 $\mathbf{x}^c$ 与对应的核 $\mathbf{w}$ 进行卷积,得到中间输出,然后将所有通道的卷积结果相加,得到 $\mathbf{z}$:
$$ \mathbf{z} = \sum_{c=1}^{C_i} \mathbf{x}^c * \mathbf{w} \tag{15.3} $$因此,在帧 $j$ 处的输出 $\mathbf{z}_j$ 实际上融合了所有输入通道的信息。
此外,卷积层的输出也比单个标量向量复杂得多。 对于每一帧输入,卷积层的输出需要是一个嵌入(embedding),即该帧的潜在表示。 与所有神经网络模型一样,这种潜在表示应具有模型指定的维度。 例如,Whisper 的模型维度为 1280,因此卷积层必须为这 1280 个维度各自生成一个输出通道。 为了实现这一点,我们会为模型的每个维度分别学习一个独立的核。 也就是说,总共学习 1280 个不同的核,每个核的深度等于输入通道数(例如 128),宽度则固定(例如 3)。 这样,每一帧的嵌入表示就包含了 1280 个独立计算出的输入信号特征。 图 15.4 给出了这一过程的示意图。
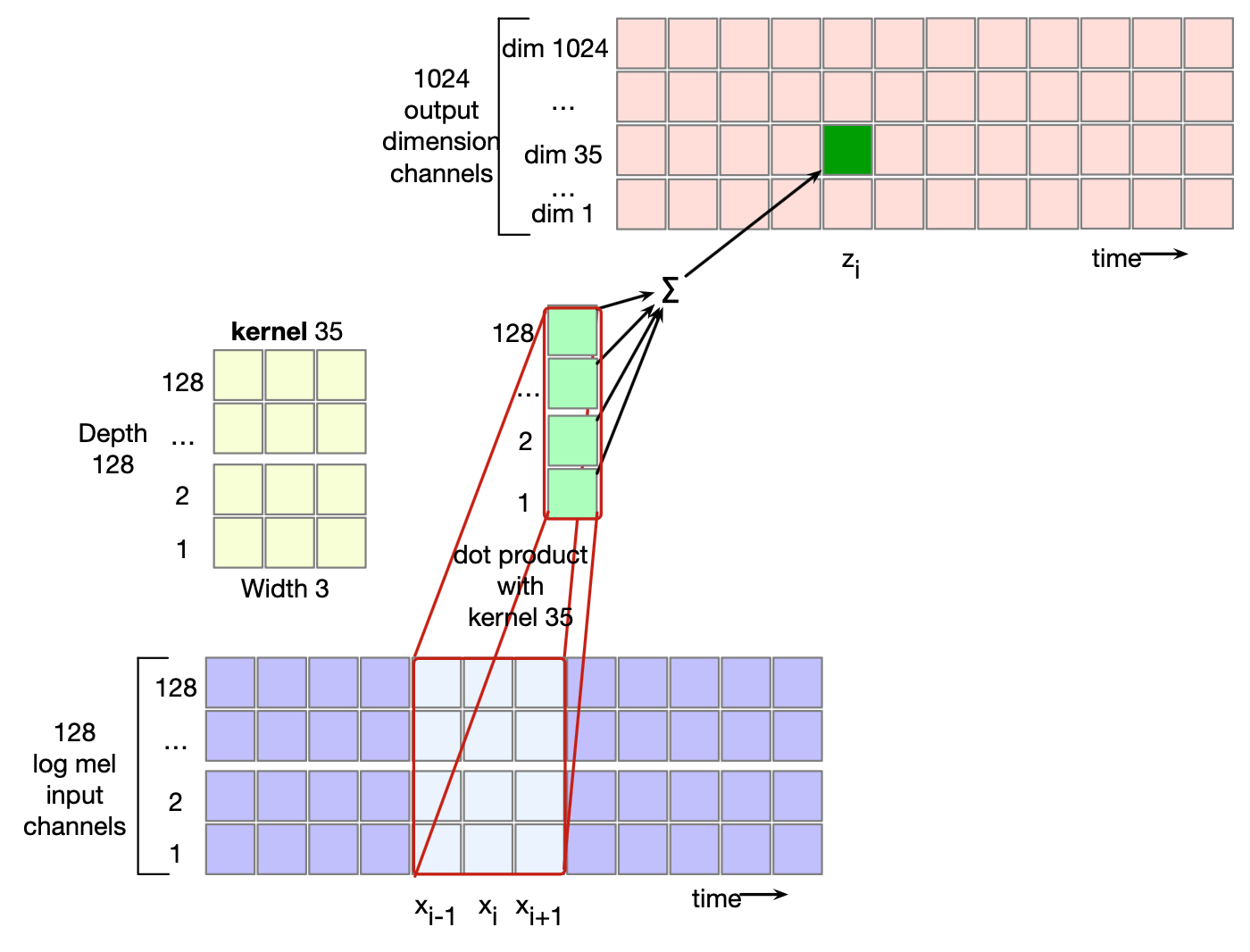
图15.4 展示了一个具有 128 个输入通道和 1024 个输出通道的卷积网络示意图。 在时间点 $i$,其中一个输出通道的核(例如“核 35”,深度为 128、宽度为 3)会分别与 128 个对数梅尔频谱输入向量做点积,再将结果求和,从而得到时间 $i$ 处输出嵌入中某一维度的单一数值。
一维卷积层还可以设置步幅(stride)。 步幅指每次滑动时核在输入上移动的距离。 上文图示均采用步幅为1的情况,即核依次覆盖 $\mathbf{x}_1$、$\mathbf{x}_2$、$\mathbf{x}_3$ 等位置。 若步幅为2,则核依次覆盖 $\mathbf{x}_1$、$\mathbf{x}_3$、$\mathbf{x}_5$ 等位置。 更大的步幅会导致更短的输出序列。例如,步幅为2时,输出序列 $\mathbf{z}$ 的长度将是输入序列 $\mathbf{x}$ 的一半。 步幅大于 1 的卷积层常被用来缩短输入序列长度。 这样做不仅因为较短的序列占用更少内存和计算资源,而且(正如下一节将要说明的)它有助于缓解声学帧嵌入(每帧 10 毫秒)与字母或词语之间的时间尺度不匹配问题:后者通常覆盖远长于 10 毫秒的语音片段。
最后,在实际应用中,卷积层之后通常还会接一个非线性激活函数,例如 ReLU 层。