用于分析波形声学语音特性的工具,也常常被用作语音处理算法的输入。 本节将介绍一种常用的信号处理流程,它经常作为自动语音识别(ASR)等任务的一部分——正如我们将在第 15 章中看到的那样。 语音处理的第一步通常是将输入波形转换为一系列声学特征向量(acoustic feature vectors),其中每个向量表示信号在一小段时间窗口内的信息。 有时,语音识别或处理算法会直接从原始波形开始;在这种情况下,这类处理通常由第 15 章将介绍的卷积神经网络(convnets) 来完成。
但其他系统则从更高层次的表示入手,例如对数梅尔频谱(log mel spectrum)。 因此,本节将介绍这种广泛使用的特征向量:对数梅尔频谱向量序列。 在下一节中,我们将介绍另一种常用表示:MFCC(梅尔频率倒谱系数)。 我们的介绍将保持在相对较高的抽象层次;若需深入了解,建议修读专门的语音信号处理课程。
我们首先回顾第 14.4.2 节中所述的模拟语音波形的数字化与量化过程。
14.5.1 采样与量化
语音识别器的输入是一系列复杂的空气压力变化。 这些气压变化显然源自说话人,是由气流通过声门并从口腔或鼻腔排出的特定方式所引起的。 我们通过绘制气压随时间的变化来表示声波。 有时,一个有助于理解这类图形的比喻是:想象一块垂直的薄板挡在声波传播路径上(例如说话人嘴前的麦克风振膜,或听者耳中的鼓膜)。 图中所测量的是该薄板处空气分子的压缩(compression) 或 稀疏(rarefaction,即“解压缩”) 程度。 图 14.25(重复自图 14.11)展示了一段来自 Switchboard 电话语音语料库的短时波形,内容是某人说 “she just had a baby” 中最后一个音节 baby 的元音 [iy]。

图 14.25 元音 [iy](单词 “baby” 中的最后一个元音)的波形。 Y 轴表示气压相对于正常大气压的高低,X 轴表示时间。 注意该波形呈现规律性重复。 (重复自图 14.11)
将图 14.15 这类声波数字化的第一步,是将模拟信号(首先是气压变化,随后是麦克风中产生的模拟电信号)转换为数字信号。 这种模数转换(analog-to-digital conversion) 包含两个步骤:采样(sampling) 和 量化(quantization)。 采样是指在特定时刻测量信号的振幅。采样率(sampling rate) 即每秒采集的样本数量。 为了准确还原一个波形,每个周期内至少需要两个采样点:一个用于测量波的正半周,另一个用于负半周。 若每周期采样多于两点,可提高振幅精度;但若少于两点,则会导致该频率完全无法被正确捕捉。 因此,对于给定采样率,所能准确测量的最高频率等于采样率的一半(因为每个周期至少需两个样本)。 这一上限频率称为奈奎斯特频率(Nyquist frequency)。 人类语音中的大部分信息集中在 10,000 Hz 以下的频率范围内。因此,要实现完全保真的语音数字化,需要 20,000 Hz 的采样率。 然而,电话语音会经过交换网络的滤波处理,仅传输低于 4,000 Hz 的频率成分。 因此,对于像 Switchboard 语料库这样的电话带宽(telephone-bandwidth) 语音,8,000 Hz 的采样率已足够。 而对于麦克风录制的宽频语音,通常采用 16,000 Hz 的采样率。
尽管使用更高的采样率可以提升自动语音识别(ASR)的准确率,但我们不能在训练和测试 ASR 系统时混用不同的采样率。 因此,如果我们在 Switchboard 这样的电话语音语料库(8 kHz 采样)上进行测试,就必须将训练语料下采样(downsample)至 8 kHz。 同样,如果我们在多个语料库上联合训练,而其中包含电话语音,那么我们就需要将所有宽频语料统一下采样至 8 kHz。
振幅测量值通常以整数形式存储,常见的是 8 位(取值范围为 -128 到 127)或 16 位(取值范围为 -32,768 到 32,767)。 将实数值表示为整数的过程称为量化(quantization);所有小于最小分辨粒度(即“量子大小”)的差异都会被表示为相同的值。 我们将数字化并量化后的波形中时间索引为 $n$ 的样本记作 $x[n]$。
数据量化后,会以多种格式进行存储。 这些格式的一个参数就是上文提到的采样率和采样位深:电话语音通常以 8 kHz 采样,并以 8 位样本存储;麦克风录制的数据则常以 16 kHz 采样,并以 16 位样本存储。 另一个参数是声道数(channels)。 对于立体声数据或两人对话,我们可以将两个声道存入同一个文件,也可以分别存入不同文件。 最后一个参数是单个样本的存储方式:线性存储或压缩存储。 电话语音常用的一种压缩格式是 μ-law(常写作 u-law,但仍读作 “mu-law”)。 像 μ-law 这类对数压缩算法的基本思想是:人耳对小强度声音的变化比对大强度更敏感;对数压缩能更忠实地表示小数值,代价是对大数值引入更多误差。 未经过对数压缩的线性值通常称为线性 PCM 值(PCM 指脉冲编码调制,pulse code modulation,此处无需深究其细节)。 以下是将线性 PCM 样本值 $x$(其中 $-1 \leq x \leq 1$)压缩为 8 位 μ-law 的公式(8 位时 $\mu = 255$):
$$ F(x) = \frac{\text{sgn}(x)\log(1 + \mu|x|)}{\log(1 + \mu)} \quad -1 \leq x \leq 1 \tag{14.10} $$14.5.2 窗函数
从数字化、量化的波形表示中,我们需要提取一小段语音窗口中的频谱特征,以表征特定音素的一部分。 在这个小窗口内,我们可以粗略地认为信号是平稳的(即其统计特性在这个区域内是恒定的)。(相比之下,一般来说,语音是一个非平稳信号,意味着它的统计特性随时间变化而改变)。 我们使用一个在某一区域内部非零而在其他地方为零的窗函数,并将其沿语音信号滑动,同时将它与输入波形相乘来产生加窗后的波形,从而提取出这段近似平稳的语音部分。
从每个窗口提取出来的语音称为一帧。 加窗过程由三个参数来描述:窗大小或帧大小(窗口宽度,单位为毫秒)、连续窗口之间的帧步长(也称为移位或偏移)、以及窗口的形状。
为了提取信号,我们将时间 $n$ 处的信号值 $s[n]$ 乘以时间 $n$ 处的窗函数值 $w[n]$:
$$ y[n] = w[n]s[n] \tag{14.11} $$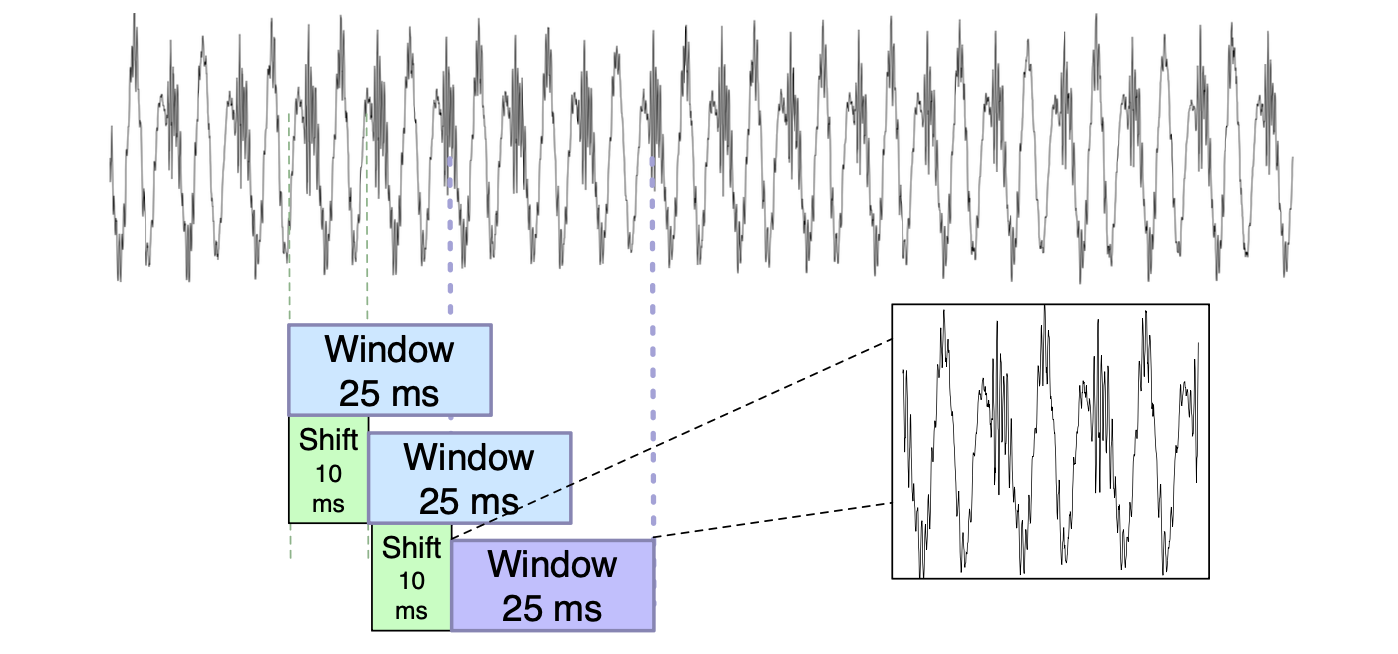
图 14.26 加窗示意图,展示了一个具有 25 毫秒矩形窗口和 10 毫秒步长的例子。
图 14.26 中所示的窗函数形状是矩形的;可以看到提取出的加窗信号看起来就像原始信号。 然而,矩形窗在边界处突然切断信号,在进行傅里叶分析时会引发问题。 因此,对于声学特征创建,我们更常用的是汉明窗(Hamming window),它能够在窗口边界处使信号值逐渐趋近于零,避免了不连续性。 图 14.27 展示了这两种窗函数,公式如下(假设窗口长度为 L 帧):
矩形窗:
$$ w[n] = \begin{cases} 1 & 0 \leq n \leq L -1 \\ 0 & \text{otherwise} \end{cases} (14.12) $$汉明窗:
$$ w[n] = \begin{cases} 0.54 - 0.46 \cos(\frac{2\pi n}{L}) & 0 \leq n \leq L -1 \\ 0 & \text{otherwise} \end{cases} \tag{14.13} $$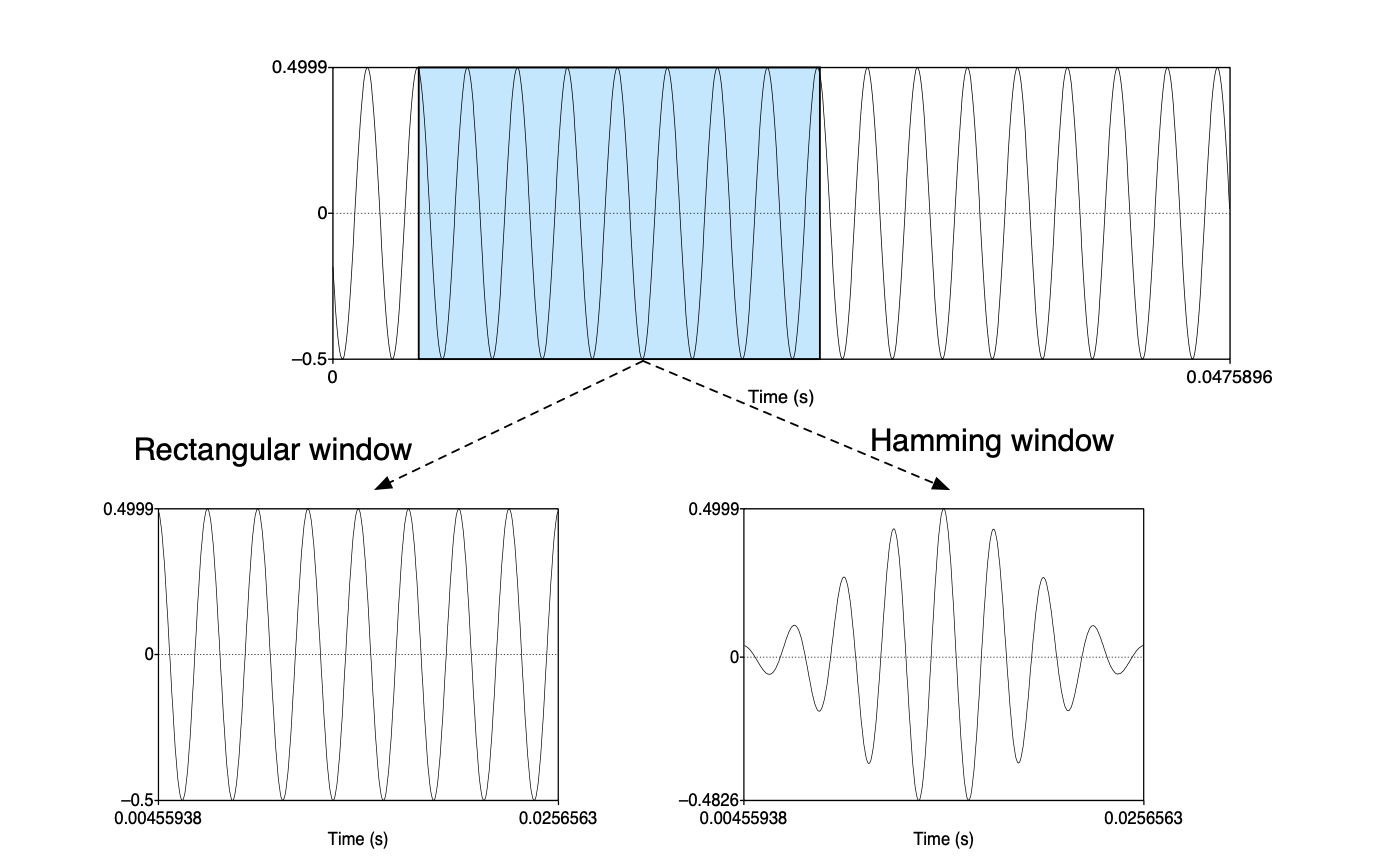
图 14.27 使用矩形或汉明窗对正弦波进行加窗处理。
这些技术帮助我们在处理语音信号时更好地捕捉到局部平稳的特性,减少边界效应带来的负面影响,从而提高后续频域分析的准确性。
14.5.3 离散傅里叶变换
下一步是从加窗后的信号中提取频谱信息;我们需要知道该信号在不同频带中包含多少能量。 用于从离散时间(即已采样)信号中提取离散频带频谱信息的工具是离散傅里叶变换(Discrete Fourier Transform, DFT)。
DFT 的输入是一段加窗信号 $x[n], \dots, x[m]$,输出是对 $N$ 个离散频率点中的每一个,给出一个复数 $X[k]$,表示原始信号中该频率成分的幅度和相位。 如果我们把幅度对频率作图,就能得到该信号的频谱(有关频谱的更多内容参见第 14 章)。 例如,图 14.28 展示了一段 25 毫秒长、经汉明窗处理的信号片段(来自元音 [iy])及其通过 DFT 计算出的频谱(并经过一定平滑处理)。
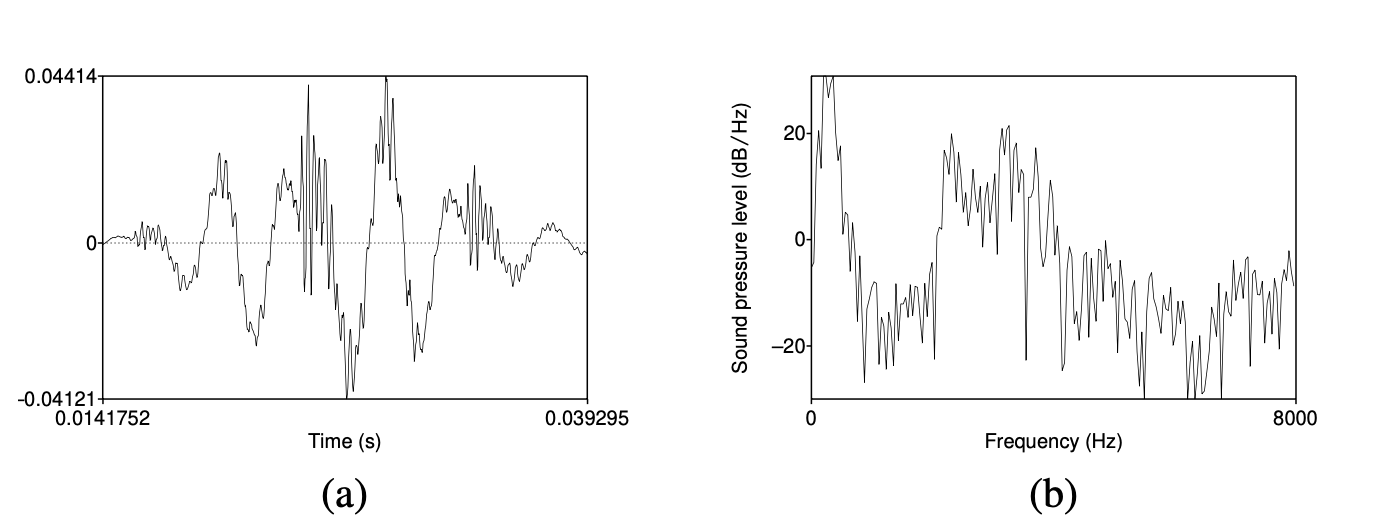
图 14.28 (a) 来自元音 [iy] 的一段 25 毫秒汉明窗信号片段;(b) 其通过 DFT 计算得到的频谱。
我们在此不深入介绍 DFT 的数学细节,仅指出傅里叶分析依赖于欧拉公式(Euler’s formula),其中 $j$ 为虚数单位:
$$ e^{j\theta} = \cos \theta + j \sin \theta \tag{14.14} $$对于已经学过信号处理的同学,这里简要回顾一下:DFT 的定义如下:
$$ X[k] = \sum^{N-1}_{n=0} x[n] \, e^{-j\frac{2\pi}{N}kn} \tag{14.15} $$计算 DFT 的常用高效算法是快速傅里叶变换(Fast Fourier Transform, FFT)。 这种 DFT 的实现方式非常高效,但仅适用于 $N$ 为 2 的整数幂的情形。
14.5.4 梅尔滤波器组与对数变换
FFT 的结果告诉我们每个频率带的能量。 然而,人耳对不同频段的敏感度并不相同——它对高频部分的敏感度较低。 这种对低频的偏向有助于人类语音识别,因为低频信息(如共振峰)对于区分元音或鼻音至关重要,而高频信息(如塞音爆发或擦音噪声)在成功识别中相对次要。 通过建模这种人类感知特性,也能以类似方式提升语音识别系统的性能。
我们实现这一思想的方式不是等间距地收集各频带能量,而是依据梅尔尺度(mel scale)——一种听觉频率尺度。 梅尔(mel)(Stevens 等,1937;Stevens 与 Volkmann,1940)是一种音高单位:如果两个声音在感知上音高距离相等,则它们之间的梅尔差值也相等。 梅尔频率 $m$ 可通过对原始声学频率 $f$ 进行对数变换得到:
$$ \text{mel}(f) = 1127 \ln\left(1 + \frac{f}{700}\right) \tag{14.16} $$为实现这一思想,我们构建一个滤波器组(filter bank),其中每个滤波器从特定频率范围收集能量,并按对数方式分布:在低频区域具有非常精细的分辨率,而在高频区域分辨率较低。 图 14.29 展示了一组典型的三角形滤波器,它们沿梅尔尺度对数分布,可与频谱相乘以获得梅尔频谱(mel spectrum)。
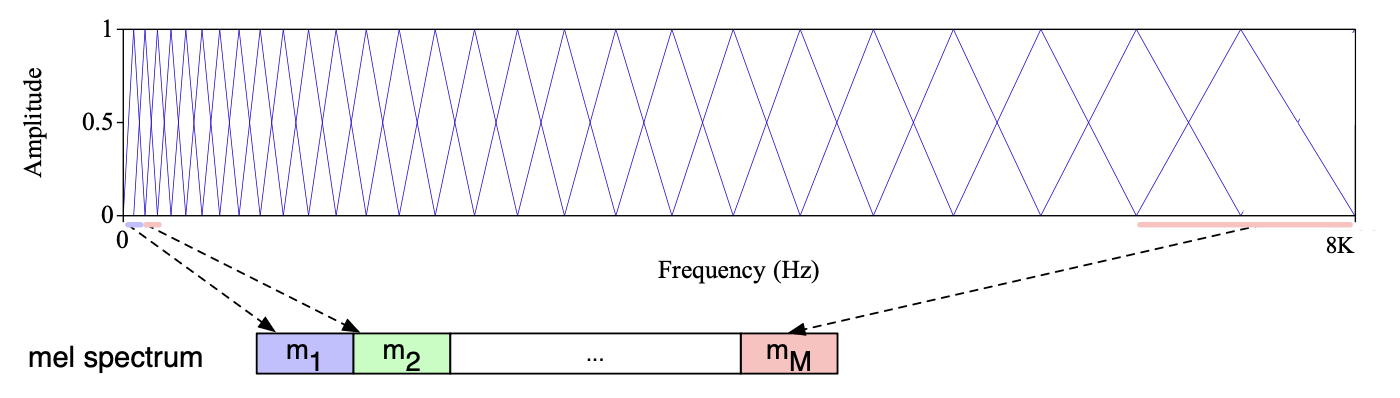
图 14.29 梅尔滤波器组(Davis 和 Mermelstein,1 980)。每个三角形滤波器沿梅尔尺度对数分布,用于收集特定频率范围内的能量。
最后,我们对每个梅尔频谱值取对数。 人类对信号强度的响应是对数性的(正如对频率的响应一样)。 在高振幅下,人耳对微小振幅差异的敏感度低于在低振幅时。 此外,使用对数变换还能降低特征估计受输入变化的影响(例如因说话人嘴部离麦克风远近不同导致的功率波动)。
我们将每个滤波器输出的标量值称为一个通道(channel)。因此,对于每一帧输入,滤波器组会输出一个向量(例如包含 80 或 128 个通道),每个通道代表某一(按梅尔尺度划分的)频带的对数能量。
在将这个对数梅尔通道向量送入下游神经网络层之前,语音系统通常会对其进行重缩放,使其数值范围一致。 一种常见的语音归一化方法是将整个预训练数据集输入缩放到均值为零的区间 $[-1, 1]$ (参见第 4 章 4.3.2 节)。