我们首先对声学波形及其数字化和频域分析做一个非常简要的介绍;有兴趣的读者可参考本章末尾所列的参考资料。
14.4.1 波
声学分析基于正弦(sine)和余弦(cosine)函数。 图 14.10 展示了一条正弦波的图像,具体对应以下函数:
$$ y = A \cdot \sin(2 \pi f t) \tag{14.3} $$其中,振幅 $A$ 设为 1,频率 $f$ 设为每秒 10 个周期。
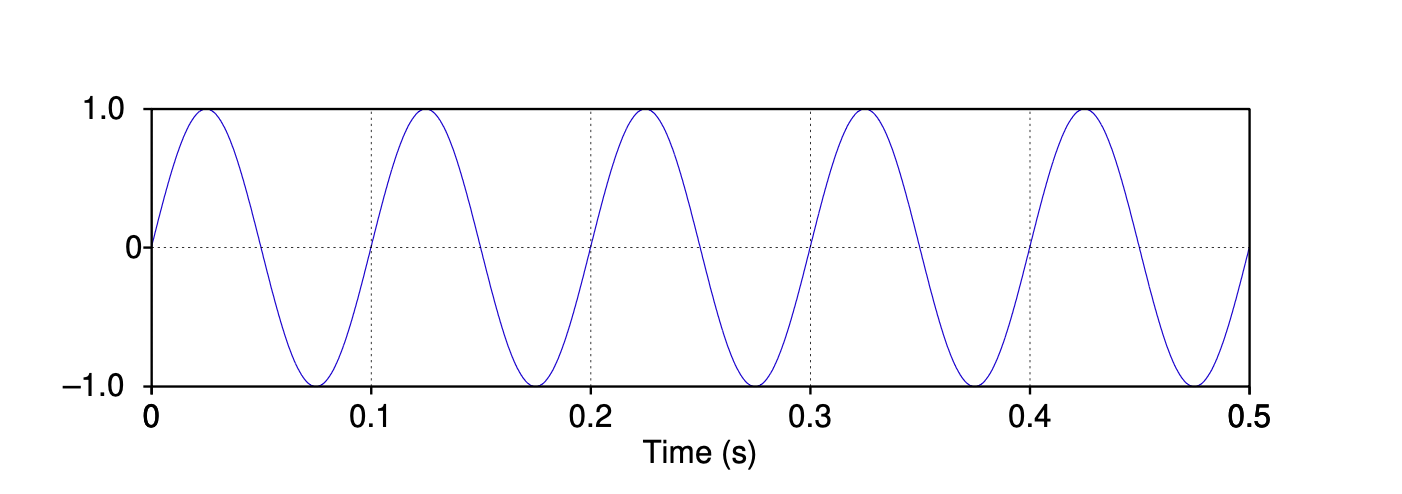
图 14.10 频率为 10 Hz、振幅为 1 的正弦波。
根据基础数学知识,波有两个重要特征:频率(frequency) 和 振幅(amplitude)。 频率指波每秒重复的次数,即周期(cycles) 的数量。 频率通常以每秒周期数来度量。 图 14.10 中的信号在 0.5 秒内重复了 5 次,因此频率为每秒 10 个周期。 每秒周期数通常称为赫兹(hertz),缩写为 Hz,所以图 14.10 中的频率可描述为 10 Hz。 正弦波的振幅 $A$ 是其在 Y 轴上的最大值。 波的周期 $T$ 是完成一个完整循环所需的时间,定义为:
$$ T = \frac{1}{f} \tag{14.4} $$图 14.10 中每个周期持续十分之一秒,因此 $T = 0.1$ 秒。
14.4.2 语音声波
现在我们从理想化的波转向真实的声波。 语音识别系统的输入,就像人耳的输入一样,是一系列复杂的空气压力变化。 这些气压变化显然源自说话人,是由气流通过声门并从口腔或鼻腔排出的特定方式所引起的。 我们通过绘制气压随时间的变化来表示声波。 有时,一个有助于理解这类图形的比喻是:想象一块垂直的薄板挡在声波传播路径上(例如说话人嘴前的麦克风振膜,或听者耳中的鼓膜)。 图中所测量的是该薄板处空气分子的压缩(compression) 或 稀疏(rarefaction,即“解压缩”) 程度。 图 14.11 展示了一段来自 Switchboard 电话语音语料库的短时波形,内容是某人说 “she just had a baby” 中的元音 [iy]。

图 14.11 元音 [iy] 的波形,取自第 319 页图 14.15 所示话语的一部分。 Y 轴表示气压相对于正常大气压的高低,X 轴表示时间。 注意该波形呈现规律性重复。
将图 14.11 这类声波数字化的第一步,是将模拟信号(首先是气压变化,随后是麦克风中产生的模拟电信号)转换为数字信号。 这种模数转换(analog-to-digital conversion) 包含两个步骤:采样(sampling) 和 量化(quantization)。 采样是指在特定时刻测量信号的振幅。采样率(sampling rate) 即每秒采集的样本数量。 为了准确还原一个波形,每个周期内至少需要两个采样点:一个用于测量波的正半周,另一个用于负半周。 若每周期采样多于两点,可提高振幅精度;但若少于两点,则会导致该频率完全无法被正确捕捉。 因此,对于给定采样率,所能准确测量的最高频率等于采样率的一半(因为每个周期至少需两个样本)。 这一上限频率称为奈奎斯特频率(Nyquist frequency)。 人类语音中的大部分信息集中在 10,000 Hz 以下的频率范围内。因此,要实现完全保真的语音数字化,需要 20,000 Hz 的采样率。 然而,电话语音会经过交换网络的滤波处理,仅传输低于 4,000 Hz 的频率成分。 因此,对于像 Switchboard 语料库这样的电话带宽(telephone-bandwidth) 语音,8,000 Hz 的采样率已足够。而对于麦克风录制的宽频语音,通常采用 16,000 Hz 的采样率。
即使采用 8,000 Hz 的采样率,每秒语音也需要记录 8,000 个振幅测量值,因此高效存储这些振幅数据非常重要。 它们通常以整数形式存储,常见的是 8 位(取值范围为 -128 到 127)或 16 位(取值范围为 -32,768 到 32,767)。 将实数值表示为整数的过程称为量化(quantization),因为两个相邻整数之间的差值构成了最小分辨粒度(即“量子大小”),所有小于该粒度的差异都会被表示为相同的值。
数据量化后,会以多种格式进行存储。 这些格式的一个参数就是上文提到的采样率和采样位深:电话语音通常以 8 kHz 采样,并以 8 位样本存储;麦克风录制的数据则常以 16 kHz 采样,并以 16 位样本存储。 另一个参数是声道数(channels)。 对于立体声数据或两人对话,我们可以将两个声道存入同一个文件,也可以分别存入不同文件。 最后一个参数是单个样本的存储方式:线性存储或压缩存储。 电话语音常用的一种压缩格式是 μ-law(常写作 u-law,但仍读作 “mu-law”)。 像 μ-law 这类对数压缩算法的基本思想是:人耳对小强度声音的变化比对大强度更敏感;对数压缩能更忠实地表示小数值,代价是对大数值引入更多误差。 未经过对数压缩的线性值通常称为线性 PCM 值(PCM 指脉冲编码调制,pulse code modulation,此处无需深究其细节)。 以下是将线性 PCM 样本值 $x$(其中 $-1 \leq x \leq 1$)压缩为 8 位 μ-law 的公式(8 位时 $\mu = 255$):
$$ F(x) = \frac{\text{sgn}(x)\log(1 + \mu|x|)}{\log(1 + \mu)} \quad -1 \leq x \leq 1 \tag{14.5} $$数字化后的波形数据有多种标准文件格式用于存储,例如微软的 .wav 和苹果的 AIFF,它们都包含特定的文件头信息;此外也常使用不含文件头的“原始(raw)”格式。 例如,.wav 格式是微软多媒体文件 RIFF 格式的一个子集;RIFF 是一种通用格式,可表示一系列嵌套的数据块与控制信息。 图 14.12 展示了一个仅含一个数据块的简单 .wav 文件,包括其格式块(format chunk)和数据块(data chunk)。
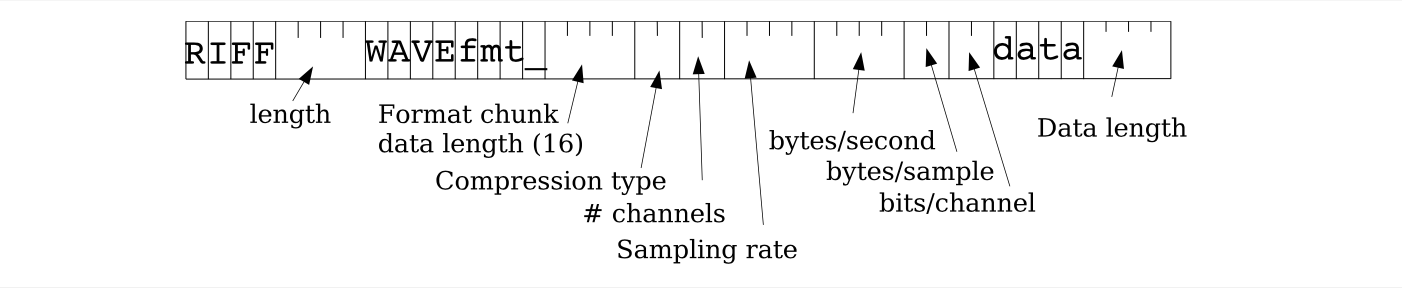
图 14.12 微软波形文件(.wav)的文件头格式(假设为仅含一个数据块的简单文件)。 此 44 字节的文件头之后紧接的是实际音频数据块。
14.4.3 频率与振幅;音高与响度
声波和其他所有波一样,可以用频率、振幅等我们在纯正弦波中介绍过的特征来描述。 但在真实声波中,这些参数不像在正弦波中那样容易直接测量。 以频率为例。注意图 14.11 中的波形虽然并非完美的正弦波,但它是周期性的——在图中所截取的 38.75 毫秒(即 0.03875 秒)内重复了 10 次。 因此,该波形片段的频率为 $10 / 0.03875 \approx 258$ Hz。
这个周期为 258 Hz 的波从何而来?它源自声带振动的速度。 由于图 14.11 中的波形来自元音 [iy],而该元音是浊音(voiced),因此存在周期性。 回想一下,浊音是由声带规律性地开合产生的:当声带打开时,肺部气流向上推动,形成高压区;当声带闭合时,肺部气流被阻断,压力下降。 因此,在声带振动时,我们会看到像图 14.11 中那样规律的振幅峰值,每个主要峰值大致对应一次声带的开启。 这种声带振动的频率(或复杂波形的基频)被称为该波形的基频(fundamental frequency),通常缩写为 F0。 我们可以将 F0 随时间的变化绘制成一条音高轨迹(pitch track)。 图 14.13 展示了一个简短疑问句 “Three o’clock?” 的音高轨迹,位于波形图下方。 注意疑问句末尾 F0 的明显上升。
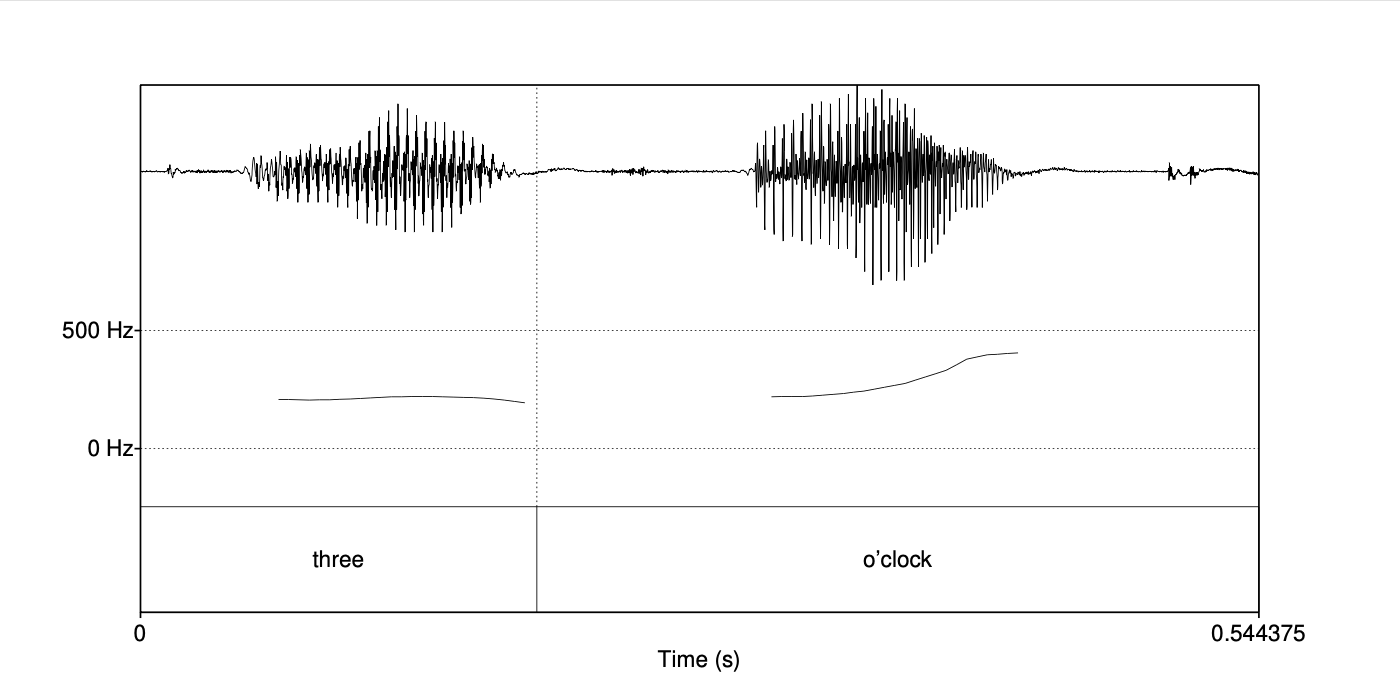
图 14.13 疑问句 “Three o’clock?” 的音高轨迹(显示在波形图下方)。 注意句末 F0 的上升。 同时注意在非常安静的部分(“o’” in “o’clock”)没有音高轨迹;自动音高追踪依赖于对浊音区域脉冲的计数,若无浊音(或声音太弱),则无法计算。
图 14.11 的纵轴表示气压变化的幅度;气压是单位面积上的力,单位为帕斯卡(Pa)。 纵轴上的高正值表示该时刻气压高于大气压,零值表示正常大气压,负值则表示气压低于大气压(即稀疏状态)。
除了某一时刻的瞬时振幅外,我们还经常需要知道某段时间内的平均振幅,以了解空气压力平均偏移的程度。 但我们不能简单地对这段时间内所有振幅值求算术平均——因为正负值会相互抵消,结果接近零。 因此,通常采用均方根振幅(RMS, root-mean-square amplitude):先将每个数值平方(使其为正),再求平均,最后取平方根:
$$ \text{RMS amplitude} = \sqrt{\frac{1}{N}\sum^N_{i=1} x^2_i} \tag{14.6} $$信号的功率(power) 与振幅的平方相关。若一段声音包含 $N$ 个采样点,则其功率定义为:
$$ \text{Power} = \frac{1}{N}\sum^N_{i=1} x^2_i \tag{14.7} $$不过,我们更常使用的是声音的强度(intensity),它将功率相对于人耳听觉阈值进行归一化,并以分贝(dB)为单位表示。 设 $P_0$ 为人耳听觉阈值气压($P_0 = 2 \times 10^{-5}$ 帕斯卡),则强度定义如下:
$$ \text{Intensity} = 10 \log_{10}\left( \frac{1}{N P_0^2} \sum^N_{i=1} x^2_i \right) \tag{14.8} $$图 14.14 展示了来自 CallHome 语料库的句子 “Is it a long movie?” 的强度图,同样显示在波形图下方。
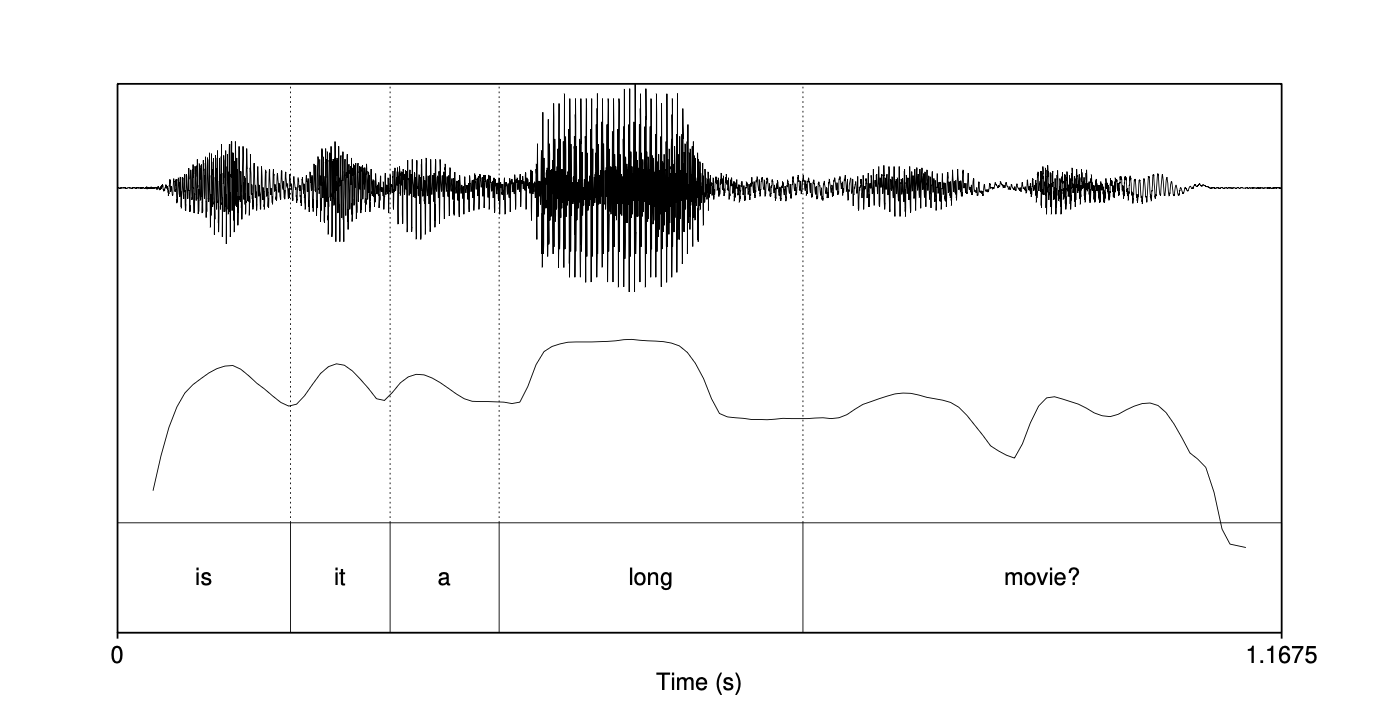
图 14.14 句子 “Is it a long movie?” 的强度图。注意每个元音处都有强度峰值,其中单词 long 的峰值尤其高。
有两个重要的感知属性——音高(pitch) 和 响度(loudness)——分别与频率和强度相关。 音高 是人对基频(F0)的主观感知或心理对应量。一般来说,基频越高,我们感知到的音高也越高。 之所以说“一般来说”,是因为这种关系并非线性:人耳对不同频率的敏感度不同。 粗略而言,人耳对 100 Hz 到 1000 Hz 范围内的音高感知最为准确,在此范围内音高与频率近似呈线性关系。 对于高于 1000 Hz 的频率,人耳分辨能力下降,此时音高与频率呈对数关系。 对数表征意味着高频之间的差异被压缩,因此感知精度降低。 存在多种心理声学模型用于描述音高感知尺度。 其中一种常用模型是 mel 尺度(mel scale)(Stevens 等,1937;Stevens 与 Volkmann,1940)。 mel 是一种音高单位,其定义使得在感知上音高距离相等的声音对之间具有相同的 mel 差值。 mel 频率 $m$ 可通过原始声学频率 $f$(单位:Hz)按下式计算:
$$ m = 1127 \ln\left(1 + \frac{f}{700}\right) \tag{14.9} $$正如我们将在第 15 章看到的那样,mel 尺度在语音识别中扮演着重要角色。
响度(loudness) 是人对功率的主观感知。 因此,振幅越大的声音听起来越响,但这种关系同样不是线性的。 首先,正如前文介绍 μ-law 压缩时提到的,人类在低功率范围内具有更高的分辨能力——耳朵对微小的功率差异更敏感。 其次,功率、频率与感知响度之间存在复杂的关系:某些频率范围内的声音会被感知为比其他频率的声音更响。
目前存在多种自动提取 F0 的算法。 尽管术语上略有不严谨,这些算法通常被称为音高提取(pitch extraction)算法。 例如,自相关法(autocorrelation method) 通过将信号与其自身在不同时间偏移下进行相关计算,找到相关性最高的偏移量,该偏移即对应信号的周期。 已有多种公开可用的音高提取工具包;例如,语音分析软件 Praat(Boersma 和 Weenink,2005)就提供了一种增强型自相关音高追踪器。
14.4.4 波形中的音素解读
通过对波形的视觉检查可以了解到很多信息。 例如,元音相对容易识别。 回想一下,元音是浊音;另一个特性是它们往往较长且相对较响(如图 14.14 中的强度图所示)。 时间长度直接体现在 x 轴上,而响度与 y 轴上的振幅平方相关。 在前一节中我们看到,浊音通过规律的振幅峰值表现出来,如图 14.11 所示,每个主要峰值对应一次声带开启。 图 14.15 展示了短句 “she just had a baby” 的波形, 我们标注了词和音素标签。 注意该图中的六个元音 [iy]、[ax]、[ae]、[ax]、[ey]、[iy] 都有规律的振幅峰值。
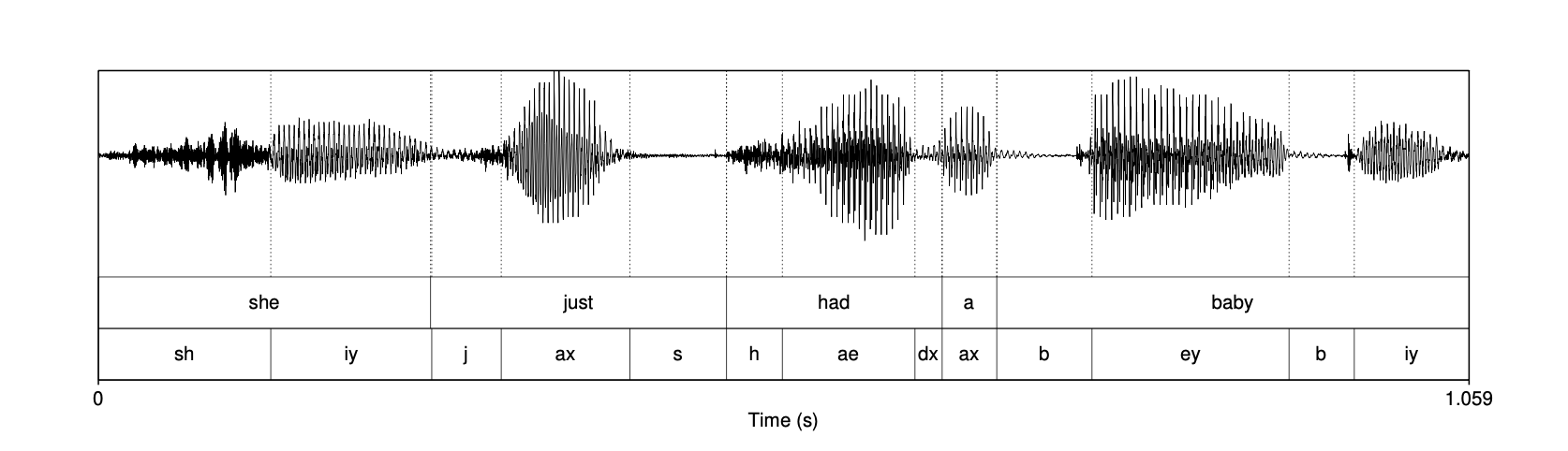
图 14.15 来自 Switchboard 语料库(对话编号 4325)的句子 “She just had a baby” 的波形。 说话者为女性,1991 年时 20 岁,大约是录音制作的时间,她讲的是美国英语的南中部方言。
对于一个由闭合和释放组成的塞音辅音,我们通常可以看到一段静默或近乎静默的时期,随后是一段轻微的振幅爆发。 在图 14.15 中单词 baby 的两个 [b] 音都可以看到这种现象。
波形中另一个常容易辨认的音素是擦音。 回忆一下,当气流通过狭窄通道产生嘈杂、湍流空气时就产生了擦音,尤其是像 [sh] 这样非常刺耳的擦音。 由此产生的嘶嘶声具有嘈杂、不规则的波形。 这在图 14.15 中有所体现,而在图 14.16 中,我们将第一个词 “she” 放大来看,这种现象更加明显。
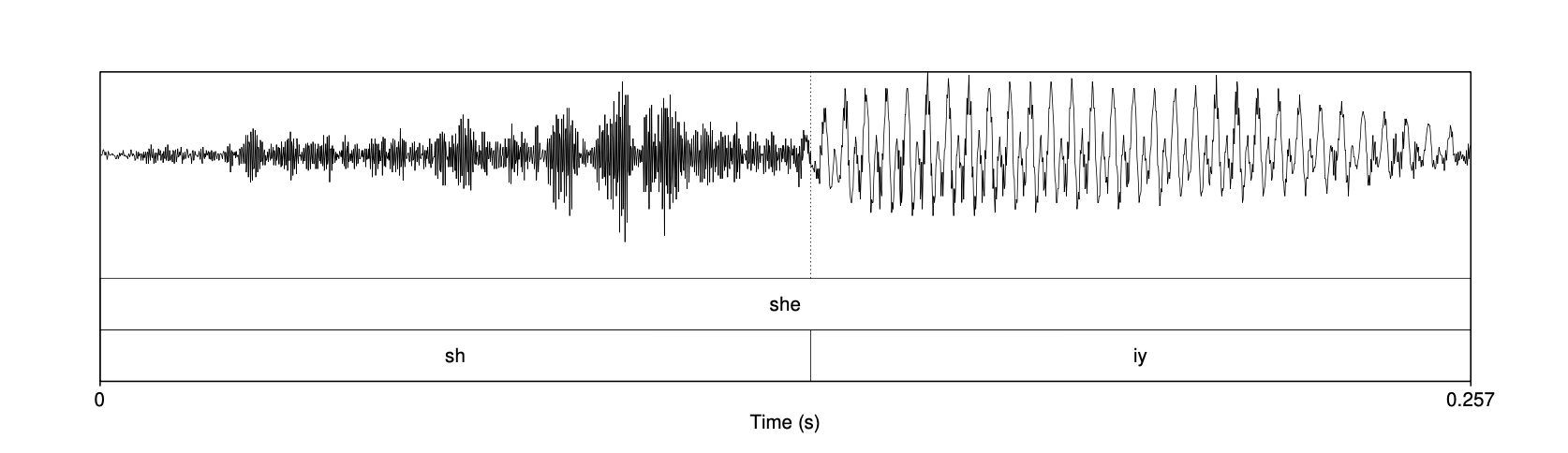
图 14.16 从图 14.15 中提取的第一个词 “she” 的更详细视图。注意擦音 [sh] 的随机噪声与元音 [iy] 的规律振动之间的差异。
14.4.5 频谱和频域
尽管一些宽泛的语音特征(如能量、音高以及浊音、塞音闭合或擦音的存在)可以直接从波形中解读,但大多数计算应用(如语音识别,以及人类听觉处理)都是基于声音的成分频率的不同表示。 傅里叶分析 的洞见在于:每一个复杂的波都可以表示为许多不同频率的正弦波之和。 考虑图 14.17 中的波形。这个波形是通过将两个正弦波叠加生成的(在 Praat 中实现),其中一个频率为 10 Hz,另一个频率为 100 Hz。
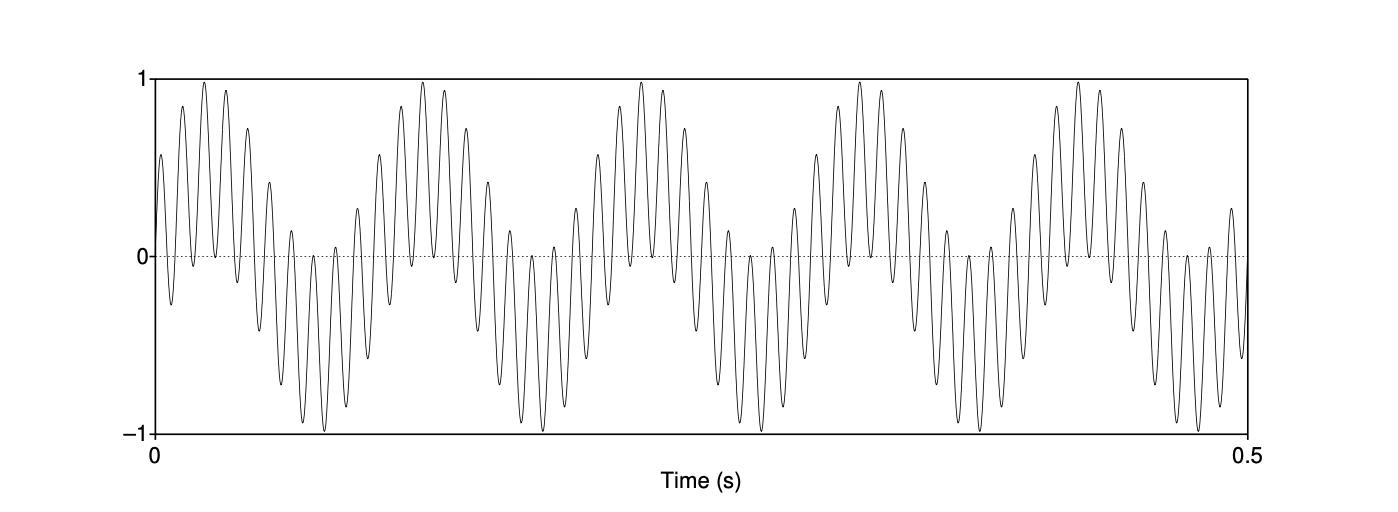
图 14.17 这个波形是由两个正弦波叠加而成,一个是频率为 10 Hz 的正弦波(注意在半秒窗口中有五次重复),另一个是频率为 100 Hz 的正弦波,两者振幅均为 1。
我们可以用频谱(spectrum) 来表示这两个成分频率。 信号的频谱是对每个频率成分及其振幅的表示。 图 14.18 展示了图 14.17 中波形的频谱。 横轴表示频率(Hz),纵轴表示振幅。 注意图中的两个峰值,一个在 10 Hz 处,另一个在 100 Hz 处。 因此,频谱是原始波形的另一种表示形式,我们使用频谱作为工具来研究特定时间点声波的成分频率。
现在让我们来看看语音波形的频率成分。 图 14.19 显示了单词 had 中元音 [ae] 的一部分波形,该部分是从图 14.15 所示的句子中截取出来的。
请注意,这里有一个复杂的波形,在图中大约重复了十次;但还有一个较小的重复波形,它在每次较大的模式中重复四次(注意到每个重复波形内的四个小峰)。 复杂波形的频率约为 234 Hz(由于它在约 0.0427 秒内重复了大约 10 次,所以 10 个周期 / 0.0427 秒 = 234 Hz)。
图 14.18 图 14.17 中波形的频谱。
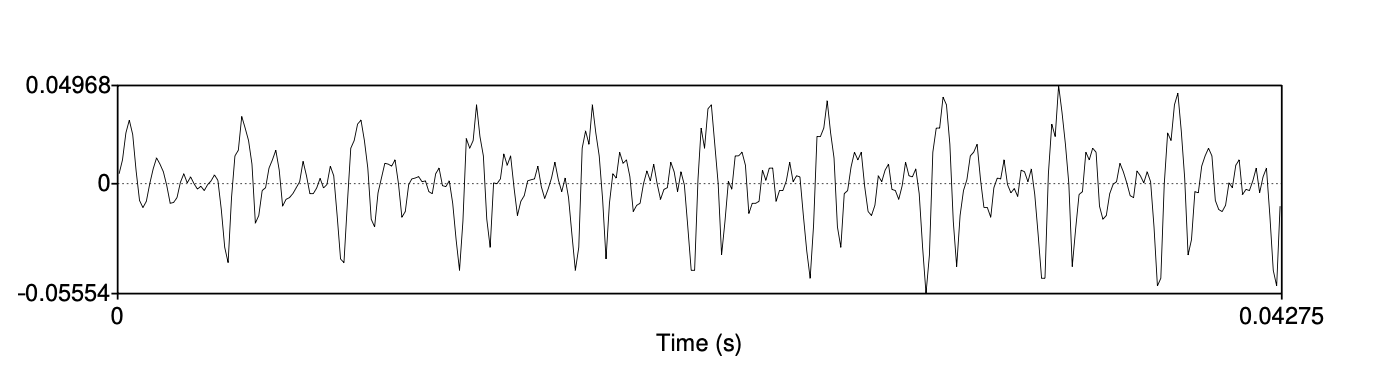
图 14.19 从图 14.15 所示波形中截取的单词 had 中元音 [ae] 的一部分波形。
较小的波形应该具有大约是较大波形频率四倍的频率,即大约936 Hz。 接着,如果你仔细观察,会看到在许多 936 Hz 的波上还有两个小波。 这个最小波形的频率应该是936 Hz波的两倍左右,因此为1872 Hz。
图14.20显示了图14.19中波形的一个平滑频谱,它是通过离散傅里叶变换(DFT)计算得出的。
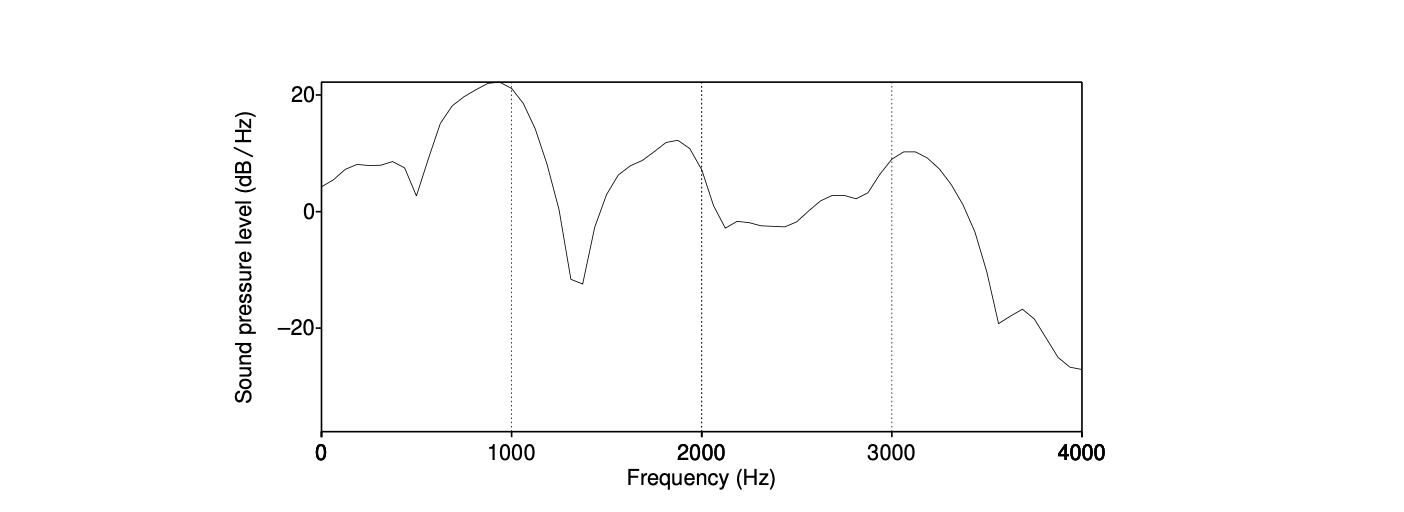
图14.20 来自单词 had 中的元音[ae]在波形 She just had a baby 中的频谱,如图14.15所示。
频谱的横轴表示频率,纵轴表示每个频率成分的幅度大小(以分贝(dB)为单位,这是我们之前见过的振幅的对数测量)。 因此,图14.20展示了大约 930 Hz、1860 Hz 和 3020 Hz 的重要频率成分,以及许多其他较低幅度的频率成分。 这些前两个成分正是我们在时域中查看图14.19中的波形时所注意到的!
为什么频谱有用? 事实证明,在频谱中容易看到的这些频谱峰值是区分不同语音特征的关键;不同的语音具有特征性的频谱“签名”。 就像化学元素燃烧时发出不同的光波长一样,这让我们可以通过分析恒星光的频谱来检测其中的元素,我们也可以通过查看波形的频谱来检测不同语音的特征签名。 这种频谱信息的使用对于人类和机器的语音识别都是至关重要的。 在人类听觉中,耳蜗或内耳的功能是计算输入波形的频谱。 类似地,用于语音识别的声学特征也是基于频谱表示的。
让我们看看不同元音的频谱。 由于某些元音随时间变化,我们将使用一种称为语谱图的不同类型的图。 虽然频谱显示了一个时间点上的波的频率成分,但语谱图是一种展示构成波形的不同频率如何随时间变化的方法。 横轴显示时间,像波形图一样,但纵轴现在显示赫兹(Hz)中的频率。 语谱图上一个点的暗度对应于该频率成分的幅度。 非常暗的点表示高幅度,浅色点表示低幅度。 因此,语谱图是可视化三个维度(时间x频率x幅度)的一种有效方式。
图14.21展示了三个美式英语元音 [ih]、[ae] 和 [uh] 的语谱图。 请注意,每个元音在各个频率带上都有一组深色条纹,每个元音稍微不同的频率带。 它们每一个代表了我们在图 14.19 中看到的相同类型的频谱峰值。
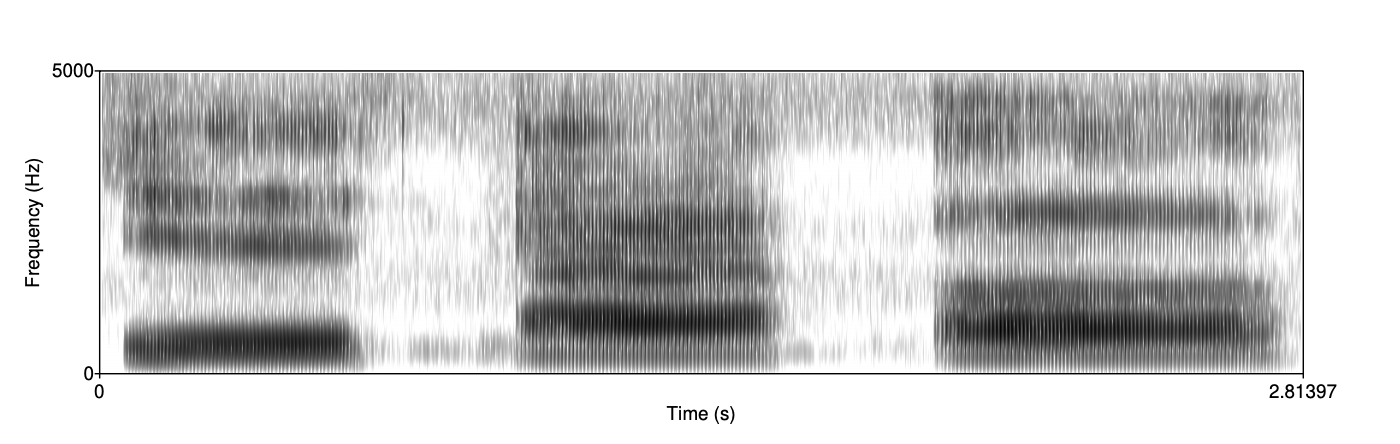
图14.21 三个美式英语元音 [ih]、[ae] 和 [uh] 的语谱图
每个深色条(或频谱峰值)被称为共振峰(formant)。 正如下面讨论的,共振峰是由声道特别放大的频率带。 由于不同的元音是通过声道在不同位置发出的,因此会产生不同类型的声音放大或共振。 让我们看看前两个共振峰,称为 F1 和 F2。 注意 F1(最靠近底部的深色条)在这三个元音中的位置不同;对于 [ih] 来说它较低(大约在 470 Hz 中心),而对于 [ae] 和 [ah] 则较高(大约在 800 Hz 左右)。 相比之下,F2(从底部数第二个深色条)在 [ih] 中最高,在 [ae] 中居中,在 [ah] 中最低。
即使在连续语音中我们也能看到这些共振峰,尽管缩减和协同发音过程使得它们稍微难以辨认。 图 14.22 展示了句子 “she just had a baby” 的语谱图,其波形如图 14.15 所示。 对于 just 中的 [ax]、had 中的 [ae] 以及 baby 中的 [ey],F1、F2(及 F3)都非常清晰。
频谱表示能为语音识别提供哪些具体线索? 首先,由于不同的元音具有特征性的共振峰位置,频谱可以区分不同的元音。 我们已经看到样本波形中的 [ae] 在 930 Hz、1860 Hz 和 3020 Hz 处有共振峰。 考虑图 14.15 中话语开头的元音 [iy]。 该元音的频谱如图 14.23 所示。 [iy] 的第一个共振峰是 540 Hz,远低于 [ae] 的第一个共振峰,而第二个共振峰(2581 Hz)则远高于 [ae] 的第二个共振峰。 如果你仔细观察,可以在图 14.22 中大约 0.5 秒的位置看到这些作为深色条的共振峰。

图 14.22 句子 “she just had a baby” 的语谱图,其波形如图 14.15 所示。我们可以将语谱图视为一系列频谱(时间片段),像图 14.20 那样依次排列。
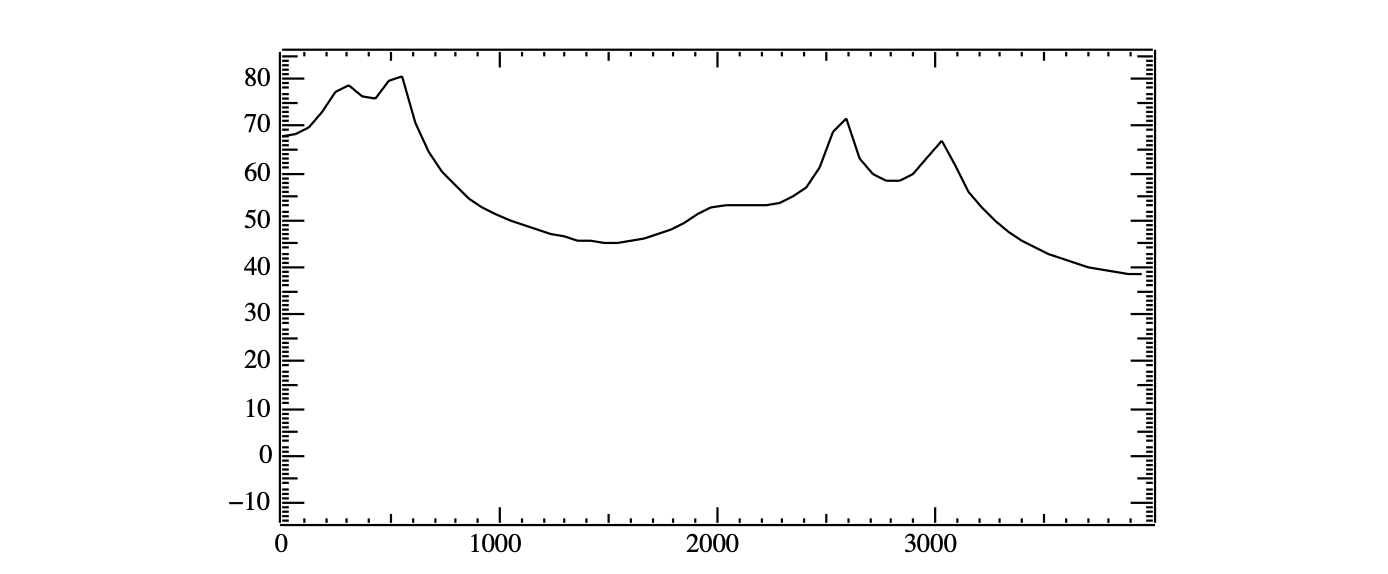
图 14.23 元音 [iy] 在 She just had a baby 开始时的平滑(LPC)频谱。请注意,第一个共振峰(540 Hz)远低于图 14.20 中 [ae] 的第一个共振峰,而第二个共振峰(2581 Hz)远高于 [ae] 的第二个共振峰。
前两个共振峰(称为 F1 和 F2)的位置在确定元音身份方面起着重要作用,尽管共振峰仍因说话者而异。 较高的共振峰往往更多地由说话者声道的一般特性决定,而不是由个别元音决定。 共振峰也可以用于识别鼻音 [n]、[m] 和 [ng] 以及流音 [l] 和 [r]。
14.4.6 声源-滤波器模型
为什么不同的元音具有不同的频谱特征? 正如前文简要提到的,共振峰是由口腔中的共鸣腔体产生的。 声源-滤波器模型(source-filter model) 是一种解释语音声学特性的方法,它将声门产生的脉冲(声源)如何被声道(滤波器)所塑造进行建模。
我们看看这一机制是如何运作的。 每当存在一个由声门脉冲引起的空气振动波时,该波还会包含一系列谐波(harmonics)。 谐波是指频率为基频整数倍的其他波动。 例如,若声带以 115 Hz 振动,则会产生 230 Hz、345 Hz、460 Hz 等一系列谐波。 一般来说,这些谐波的强度会逐级减弱,即它们的振幅远小于基频处的振幅。
然而,声道实际上起到一种滤波器或放大器的作用:任何空腔(如管道)都会对某些特定频率的声波产生放大,而抑制其他频率。 这种放大效应源于空腔的形状——特定形状会使某些频率的声音发生共振,从而被增强。 因此,通过改变空腔的形状,我们就能选择性地放大不同的频率成分。
当我们发出特定元音时,本质上是通过将舌头和其他发音器官置于特定位置来改变声道腔体的形状。 其结果是,不同的元音会放大不同的谐波成分。 也就是说,即使基频相同的声源波,经过不同形状的声道后,也会导致不同的谐波被增强。
我们可以通过观察声道形状与对应频谱之间的关系来看到这种放大效果。 图 14.24 展示了三个元音的声道构型及其典型的频谱结果。 频谱中的共振峰正是声道恰好放大了某些谐波频率的位置。
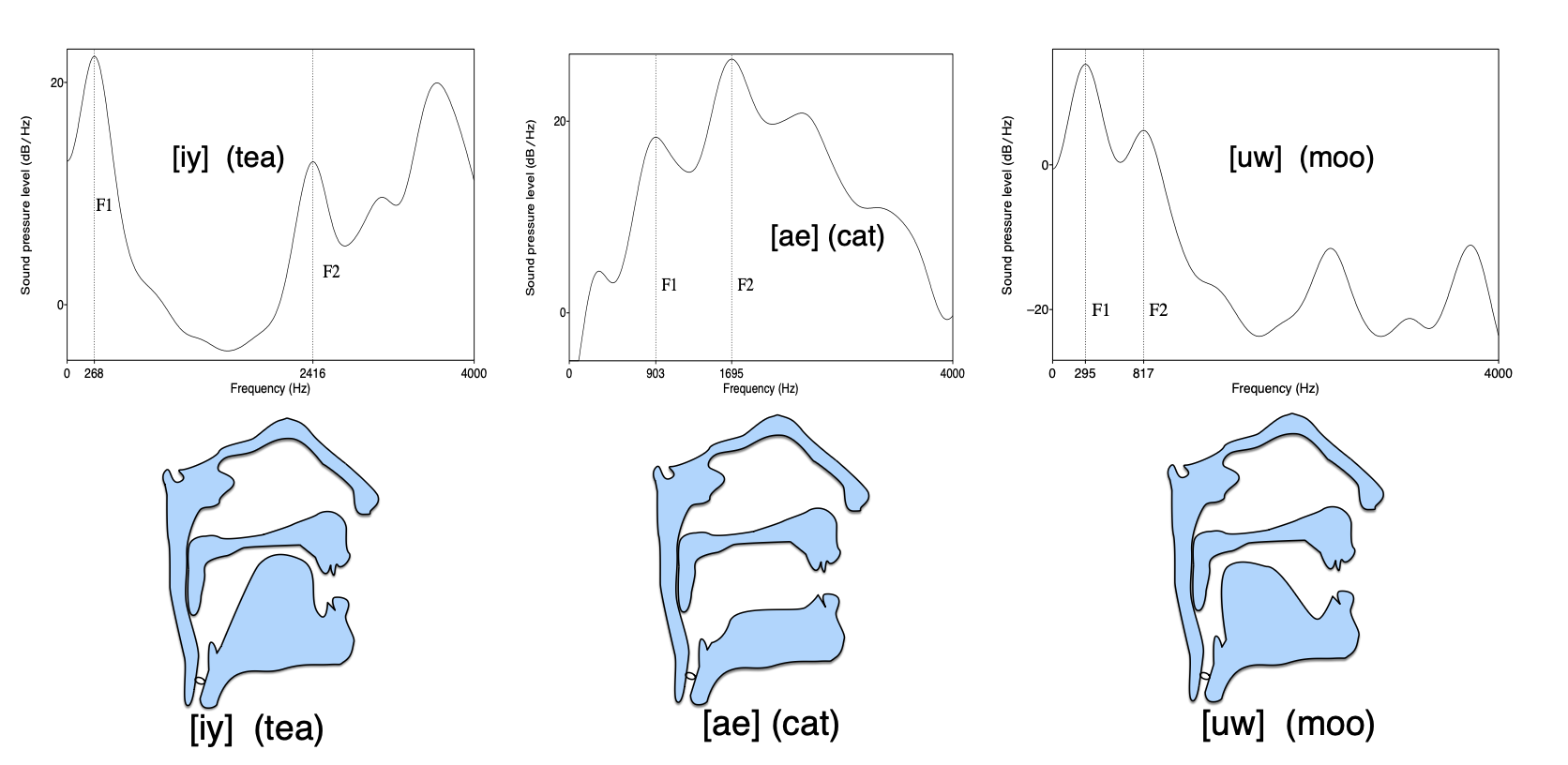
图 14.24 将声道视为滤波器的可视化示意图:三个英语元音的舌位及其对应的平滑频谱,显示了 F1 和 F2 共振峰。