本书所讨论的文本,其组成字符并非随意的符号。 它们还是一项了不起的科学发明:一种对人类语音基本单元的理论建模。
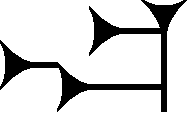
目前已知最早的文字系统(如苏美尔文、中文和玛雅文)主要是表意文字:一个符号代表一个完整的词。 但从我们所能追溯的最早阶段起,有些符号也用来表示构成词语的语音。 例如,右侧的楔形文字符号在苏美尔语中读作 ba,意思是“口粮”,但它也可以纯粹用作音素 /ba/。 我们现存最早的汉字刻在用于占卜的甲骨上,其中同样包含表音成分。 纯以语音为基础的文字系统——无论是音节文字(如日语的平假名)、字母文字(如罗马字母),还是辅音文字(如闪米特语系的文字)——都可以追溯到这些早期的意音混合系统。这类演变常常发生在两种文化接触之时。 例如,阿拉伯文、阿拉姆文、希伯来文、希腊文和罗马字母都源自一种西闪米特文字。这种文字据信是由西闪米特雇佣兵从埃及象形文字的草书形式改造而来。 而日语的音节文字则是在汉字草书形式的基础上改造而成;这些汉字本身在中国也曾被用来音译唐代传入的佛教经典中的梵语词汇。
这种隐含的观点——即口语词由更小的语音单元构成——构成了语音识别(将声波转录为文本)和文本到语音合成(将文本转换为声波)两类算法的基础。 本章将从计算的角度介绍语音学:研究世界各语言中所使用的语音,包括这些语音如何在人类声道中产生、如何在声学上实现,以及如何被数字化并加以处理。