编码器-解码器模型的简洁之处在于它清晰地分离了两个组件:编码器负责构建源文本的表示,而解码器则利用这一上下文生成目标文本。 在我们目前为止所描述的模型中,这个上下文向量就是 $\mathbf{h}_n$——即源文本第 $n$ 个(最后一个)时间步的隐藏状态。 因此,这个最终隐藏状态实际上构成了一个瓶颈(bottleneck):它必须承载源文本全部语义信息,因为解码器对源文本的了解完全依赖于这个上下文向量(见图 13.20)。 尤其对于长句子而言,句首的信息可能无法在该上下文向量中得到充分保留。

图 13.20 要求上下文向量 $\mathbf{c}$ 仅取自编码器的最终隐藏状态,迫使整个源句的所有信息都必须通过这一表征瓶颈。
注意力机制(attention mechanism)正是为解决这一瓶颈问题而提出的:它允许解码器在生成每个目标词时,从编码器所有隐藏状态中获取信息,而不仅限于最后一个状态。
在注意力机制中(与基础编码器-解码器模型类似),上下文向量 $\mathbf{c}$ 仍然是一个单一向量,并且是编码器隐藏状态的函数。 但不同的是,它不再是最后一个隐藏状态,而是对所有编码器隐藏状态进行加权平均的结果。 而且,这些权重本身也受到解码器状态的影响——具体来说,是当前要生成第 $i$ 个词之前的解码器状态 $\mathbf{h}^d_{i-1}$。 也就是说,$\mathbf{c}_i = f(\mathbf{h}^e_1, \dots, \mathbf{h}^e_n, \mathbf{h}^d_{i-1})$。 这些权重会“聚焦”(attend to)源文本中与当前正在生成的目标词 $i$ 最相关的部分。 因此,注意力机制用一个动态生成的上下文向量取代了原先静态的上下文向量——该向量不仅源自所有编码器状态,还根据解码过程中的每一步进行调整,从而对每个目标词都提供不同的上下文。
这个上下文向量 $\mathbf{c}_i$ 在每个解码步骤 $i$ 都会被重新计算,并在计算过程中综合考虑所有编码器的隐藏状态。 随后,我们在解码时将该上下文向量纳入当前解码器隐藏状态的计算中(同时结合前一时刻的隐藏状态和解码器上一步生成的输出),如以下公式(及图 13.21)所示:
$$ \mathbf{h}^d_i = g(\hat{y}_{i-1}, \mathbf{h}^d_{i-1}, \mathbf{c}_i) \tag{13.34} $$
图 13.21 注意力机制允许解码器的每个隐藏状态访问一个不同的、动态的上下文,该上下文是所有编码器隐藏状态的函数。
计算 $\mathbf{c}_i$ 的第一步,是确定应关注每个编码器状态的程度——即评估每个编码器状态 $\mathbf{h}^e_j$ 相对于当前解码器状态 $\mathbf{h}^d_{i-1}$ 的相关性(relevance)。 这种相关性通过在解码的每一步 $i$ 为每个编码器位置 $j$ 计算一个得分(score)$\text{score}(\mathbf{h}^d_{i-1}, \mathbf{h}^e_j)$ 来实现:
最简单的得分函数称为点积注意力(dot-product attention),它将相关性定义为相似性:通过计算解码器隐藏状态与编码器隐藏状态之间的点积,衡量二者有多相似:
$$ \text{score}(\mathbf{h}^d_{i-1}, \mathbf{h}^e_j) = \mathbf{h}^d_{i-1} \cdot \mathbf{h}^e_j \tag{13.35} $$点积运算得到的得分是一个标量,反映了两个向量之间的相似程度。 将所有编码器隐藏状态对应的这些得分组成一个向量,就能表示每个编码器状态对当前解码步骤的相关性。
为了利用这些得分,我们通过 softmax 函数对其进行归一化,得到一组权重 $\alpha_{ij}$,它表示在给定前一解码器隐藏状态 $\mathbf{h}^d_{i-1}$ 的条件下,第 $j$ 个编码器隐藏状态的相对重要性:
$$ \begin{align*} \alpha_{ij} &= \text{softmax}\big(\text{score}(\mathbf{h}^d_{i-1}, \mathbf{h}^e_j)\big) \\ &= \frac{\exp\big(\text{score}(\mathbf{h}^d_{i-1}, \mathbf{h}^e_j)\big)}{\sum_k \exp\big(\text{score}(\mathbf{h}^d_{i-1}, \mathbf{h}^e_k)\big)} \tag{13.36} \end{align*} $$最后,基于这个权重分布 $\alpha$,我们通过对所有编码器隐藏状态进行加权平均,计算出当前解码步骤所对应的固定长度上下文向量:
$$ \mathbf{c}_i = \sum_j \alpha_{ij} \mathbf{h}^e_j \tag{13.37} $$至此,我们得到了一个固定维度的上下文向量 $\mathbf{c}_i$,它综合了整个编码器序列的信息,并能根据解码器在每一步的实际需求动态调整。 图 13.22 展示了一个带注意力机制的编码器-解码器网络,重点描绘了单个上下文向量 $\mathbf{c}_i$ 的计算过程。
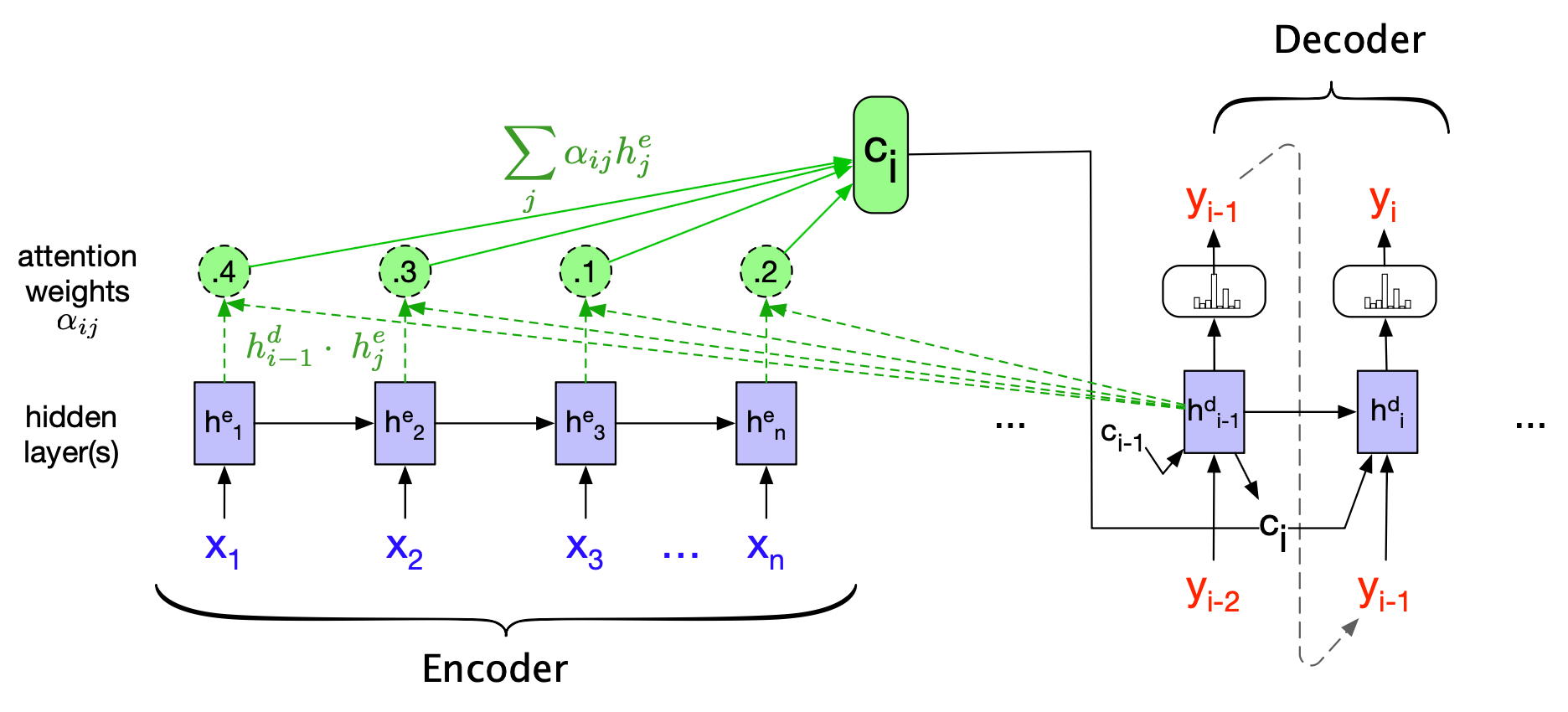
图 13.22 带注意力机制的编码器-解码器网络示意图,聚焦于 $\mathbf{c}_i$ 的计算。 上下文向量 $\mathbf{c}_i$ 是计算当前解码器隐藏状态 $\mathbf{h}^d_i$ 的输入之一,它通过对所有编码器隐藏状态进行加权求和得到,每个权重由对应编码器状态与前一解码器隐藏状态 $\mathbf{h}^d_{i-1}$ 的点积决定。
当然,也可以设计更复杂的注意力打分函数。 除了简单的点积注意力之外,我们还可以采用一个更强大的函数:通过引入一组独立的可学习权重 $\mathbf{W}_s$ 来参数化打分函数,从而计算每个编码器隐藏状态与解码器隐藏状态之间的相关性。
$$ \text{score}(\mathbf{h}^d_{i-1}, \mathbf{h}^e_j) = (\mathbf{h}^d_{i-1})^\top \mathbf{W}_s \mathbf{h}^e_j \tag{13.38} $$这些权重 $\mathbf{W}_s$ 会在端到端训练过程中一同学习,使网络能够自动发现:在当前任务中,编码器与解码器状态之间的哪些相似性特征是重要的。 这种双线性(bilinear)模型还允许编码器和解码器使用不同维度的隐藏向量,而简单的点积注意力则要求二者维度必须一致。
我们将在第 8 章介绍 Transformer 架构时再次回到注意力这一概念——该架构基于一种稍作修改的注意力机制,称为自注意力(self-attention)。