本节将介绍编码器-解码器(encoder-decoder)模型。该模型适用于这样一类任务:输入是一个序列,需要将其转换为另一个长度不同、且无法与输入进行逐词对齐的输出序列。
如果你已经读过第 12 章,那么你可能已经在 Transformer 架构中见过这种模型,并了解其在机器翻译中的应用。 但为了照顾阅读顺序不同的读者——例如先学习 RNN 再接触 Transformer 的人——我们在此重新介绍这一架构。
回想一下,在序列标注任务中,虽然也涉及两个序列,但它们长度相同(例如在词性标注中,每个词元都对应一个标签),每个输入都明确关联一个特定输出,且该输出的预测主要依赖局部上下文信息。 例如,判断一个词是动词还是名词,通常只需关注该词本身及其邻近词。
相比之下,编码器-解码器模型特别适用于像机器翻译这样的任务:输入序列和输出序列长度可能不同,且输入词与输出词之间的映射关系往往非常间接(例如,某些语言中动词出现在句首,而另一些语言则放在句末)。 我们在第 12 章已介绍过机器翻译,此处仅指出:将一句英语翻译成他加禄语(Tagalog)或约鲁巴语(Yoruba)时,译文的词数可能大不相同,词序也可能截然不同。
编码器-解码器网络(有时也称为序列到序列(sequence-to-sequence)网络)是一类能够根据输入序列生成语境恰当、任意长度输出序列的模型。 这类网络已被广泛应用于文本摘要、问答系统和对话生成等任务,尤其在机器翻译中极为流行。
这类网络的核心思想是:使用一个编码器(encoder)网络接收输入序列,并生成该序列的上下文化表示(通常称为上下文(context)); 然后将该表示传递给一个解码器(decoder),由解码器生成与具体任务相关的输出序列。 图 13.16 展示了这一架构。
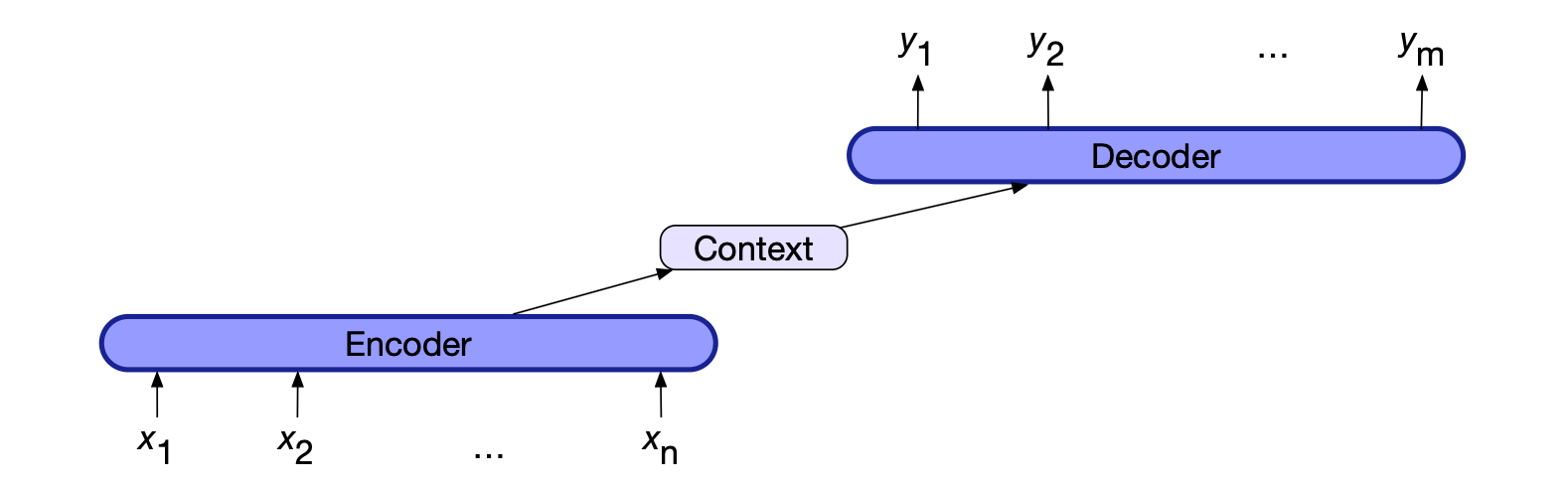
图 13.16 编码器-解码器架构。上下文是输入隐藏表示的函数,可被解码器以多种方式使用。
编码器-解码器网络包含三个概念性组件:
- 编码器(Encoder):接收输入序列 $x_{1:n}$,并生成对应的上下文化表示序列 $h_{1:n}$。LSTM、卷积网络或 Transformer 均可用作编码器。
- 上下文向量(Context vector)$c$:它是 $h_{1:n}$ 的某种函数,用于将输入序列的核心信息传递给解码器。
- 解码器(Decoder):以 $c$ 为输入,生成一个任意长度的隐藏状态序列 $h_{1:m}$,并由此得到对应的输出序列 $y_{1:m}$。与编码器类似,解码器也可采用任何类型的序列建模架构实现。
在本节中,我们将描述一种基于一对 RNN 的编码器-解码器网络;而在第 12 章中,我们还会看到如何将其应用于 Transformer 架构。 我们将从条件 RNN 语言模型 $p(y)$(即序列 $y$ 的概率)出发,逐步构建编码器-解码器模型的数学表达式。
回忆一下,在任何语言模型中,我们都可以将序列概率分解如下:
$$ p(y) = p(y_1)\, p(y_2|y_1)\, p(y_3|y_1,y_2) \cdots p(y_m|y_1,\dots,y_{m-1}) \tag{13.28} $$在 RNN 语言建模中,在某一特定时刻 $t$,我们将前 $t-1$ 个词元组成的前缀输入语言模型,通过前向推理生成一系列隐藏状态,最终得到与该前缀最后一个词对应的隐藏状态。 随后,我们以该最终隐藏状态为起点,生成下一个词元。
更形式化地讲,若 $g$ 是一个激活函数(如 tanh 或 ReLU),它是当前时刻输入 $\mathbf{x}_t$ 与前一时刻隐藏状态 $\mathbf{h}_{t-1}$ 的函数,且 softmax 操作作用于整个词汇表,则在时刻 $t$,输出 $\hat{y}_t$ 和隐藏状态 $\mathbf{h}_t$ 的计算方式如下:
$$ \begin{align*} \mathbf{h}_t = g(\mathbf{h}_{t-1}, \mathbf{x}_t ) \tag{13.29} \\ \hat{y}_t = \text{softmax}(\mathbf{h}_t ) \tag{13.30} \end{align*} $$我们只需做一处微小改动,就能将这种具有自回归生成能力的语言模型转变为一个编码器-解码器模型,即一个能将一种语言的源文本(source text)翻译成另一种语言的目标文本(target text)的翻译模型:在源文本末尾添加一个句子分隔符(sentence separator)标记,然后简单地将目标文本拼接在其后。
我们用 <s> 表示这个句子分隔符。例如,考虑将英文源句 “the green witch arrived” 翻译为西班牙语句子 “llegó la bruja verde”(逐词直译为 “arrived the witch green”)。
当然,我们也可以用问答对或摘要-原文对来说明编码器-解码器模型。
令 $x$ 表示源文本(此处为英文)加上分隔符 <s>,$y$ 表示目标文本(此处为西班牙文)。
那么,编码器-解码器模型计算条件概率 $p(y|x)$ 的方式如下:
图 13.17 展示了编码器-解码器模型的一个简化版本(我们将在下一节介绍完整模型,它需要引入一个新的概念——注意力机制(attention))。
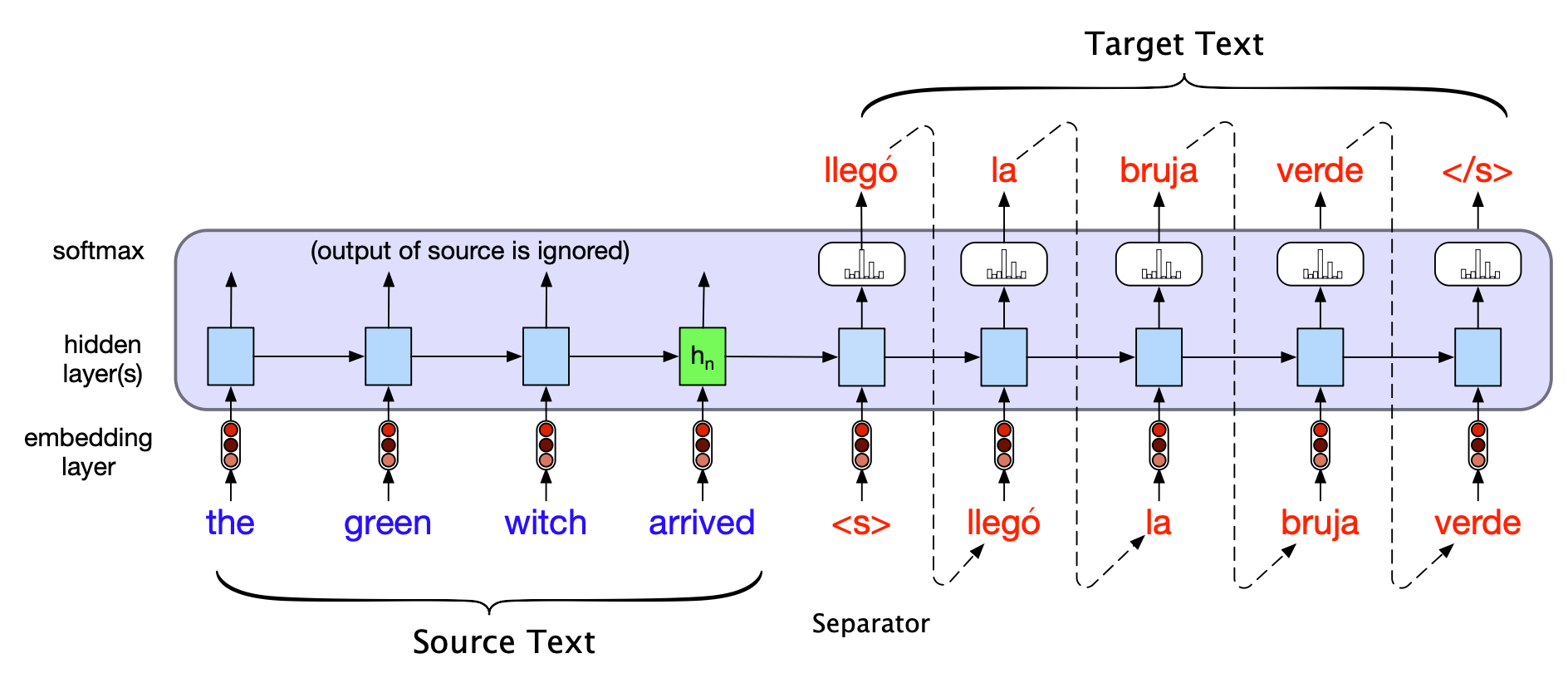
图 13.17 基于基本 RNN 的编码器-解码器机器翻译方法在推理阶段翻译单个句子的情形。 源句与目标句之间用分隔符连接,解码器利用编码器最后一个隐藏状态提供的上下文信息进行生成。
图 13.17 显示了一个英文源句(“the green witch arrived”)、一个句子分隔符 <s>,以及一个西班牙语目标句(“llegó la bruja verde”)。
要翻译一个源句,我们首先将其输入网络,执行前向推理,逐词生成隐藏状态,直到处理完源句末尾。
接着,我们开始自回归生成:在源句末尾隐藏状态和句子结束标记所提供的上下文中,预测第一个目标词。
后续的每个词则以其前一时刻的隐藏状态和上一个生成词的词嵌入为条件进行预测。
让我们在图 13.18 中对该模型稍作形式化和泛化。 (为便于区分,我们在必要时使用上标 $e$ 和 $d$ 分别表示编码器和解码器的隐藏状态。) 左侧网络组件处理输入序列 $x$,构成编码器。 虽然我们的简化图中仅展示了一层编码器网络,但实际中通常采用堆叠架构:取堆叠结构顶层的输出状态作为最终表示。 更常见的是,编码器由堆叠的双向 LSTM(biLSTM)组成,其中每个时间步的上下文化表示由前向和后向传播在顶层的隐藏状态拼接而成。
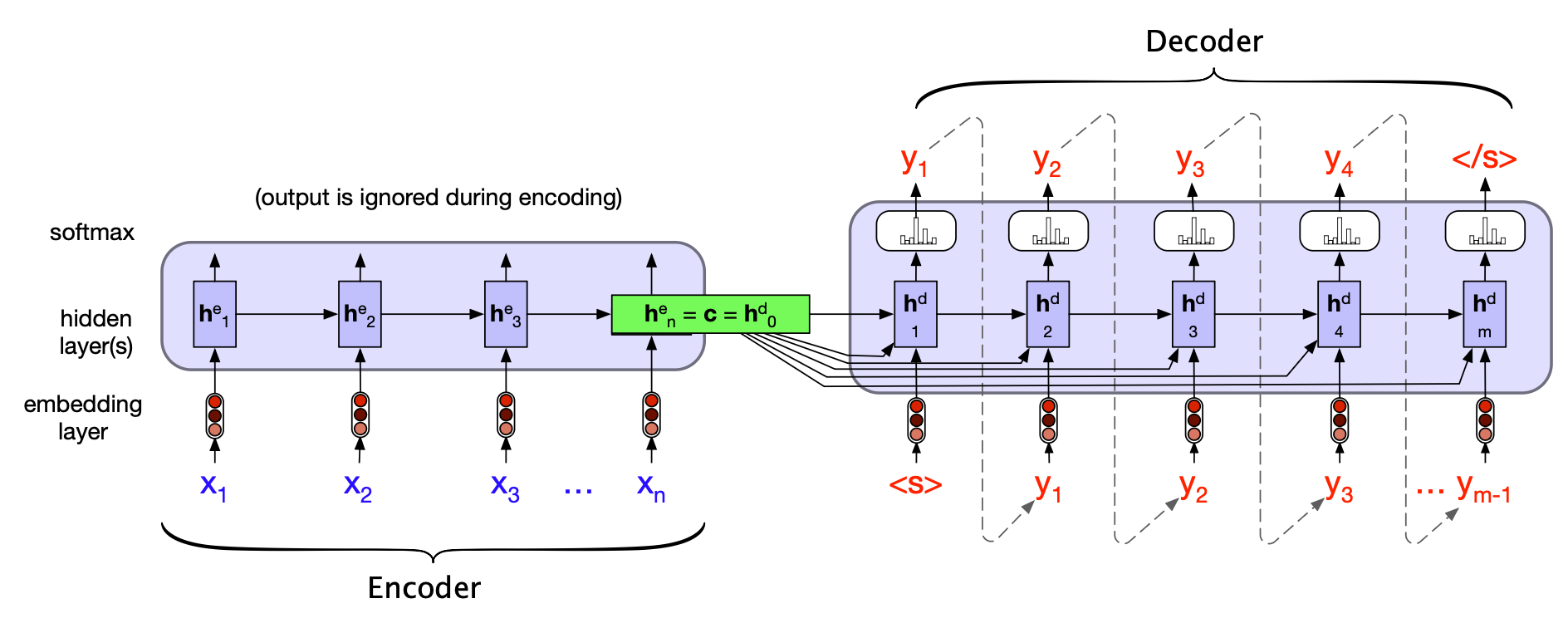
图 13.18 基于 RNN 的编码器-解码器架构在推理阶段翻译句子的更正式表示。 编码器 RNN 的最终隐藏状态 $\mathbf{h}^e_n$ 作为上下文信息,一方面作为解码器 RNN 的初始隐藏状态 $\mathbf{h}^d_0$,另一方面也被提供给解码器的每一个时间步的隐藏状态计算中。
编码器的全部目的,就是为输入生成一个上下文化表示。 这一表示体现在编码器的最终隐藏状态 $\mathbf{h}^e_n$ 中。 该表示也常被称为上下文向量(context vector),记作 $\mathbf{c}$,随后被传递给解码器。
最简单的解码器网络仅将该上下文向量用于初始化解码器的第一个隐藏状态:即第一个解码器 RNN 单元将其作为初始隐藏状态 $\mathbf{h}^d_0 = \mathbf{c}$。 之后,解码器以自回归方式逐个生成输出序列,直到生成一个序列结束标记为止。 每个隐藏状态都依赖于前一时刻的隐藏状态和前一时刻生成的输出。
然而,如图 13.18 所示,我们采用了一种更复杂的做法:不仅将上下文向量 $\mathbf{c}$ 提供给解码器的第一个隐藏状态,而是使其在生成整个输出序列的过程中始终可用,以防止随着生成步数增加,$\mathbf{c}$ 的影响逐渐衰减。 具体做法是:在计算当前解码器隐藏状态时,显式地将 $\mathbf{c}$ 作为一个额外输入,使用如下公式:
$$ \mathbf{h}^d_t = g(\hat{y}_{t-1}, \mathbf{h}^d_{t-1}, \mathbf{c}) \tag{13.32} $$现在,我们可以完整写出这种基础编码器-解码器模型中解码器的方程组——其中上下文向量 $\mathbf{c}$ 在每个解码时间步都可被访问。 回忆一下,$g$ 代表某种形式的 RNN(如 LSTM 或 GRU),而 $\hat{y}_{t-1}$ 是上一步 softmax 输出所采样词的嵌入向量:
$$ \begin{align*} \mathbf{c} &= \mathbf{h}^e_n \\ \mathbf{h}^d_0 &= \mathbf{c} \\ \mathbf{h}^d_t &= g(\hat{y}_{t-1}, \mathbf{h}^d_{t-1}, \mathbf{c}) \\ \hat{y}_t &= \text{softmax}(\mathbf{h}^d_t) \tag{13.33} \end{align*} $$因此,$\hat{y}_t$ 是一个词汇表上的概率分布向量,表示在时刻 $t$ 各个词出现的概率。 为了生成文本,我们从该分布 $\hat{y}_t$ 中进行采样。 例如,最简单的贪心策略(greedy decoding)就是在每个时间步选择概率最高的词。 我们在第 7.4 节讨论过其他采样方法。
13.7.1 编码器-解码器模型的训练
编码器-解码器架构采用端到端的方式进行训练。 每个训练样本由一对字符串组成:一个源句和一个目标句。 在中间加入分隔符后,这些源-目标对即可作为训练数据使用。
对于机器翻译(MT),训练数据通常由句子及其译文组成。 这些数据可来自标准的平行语料库(aligned sentence pairs),我们将在第 12.2.2 节进一步讨论。 一旦有了训练集,训练过程就与任何基于 RNN 的语言模型类似。 网络首先接收源文本,然后从分隔符开始,以自回归方式训练模型预测下一个词,如图 13.19 所示。
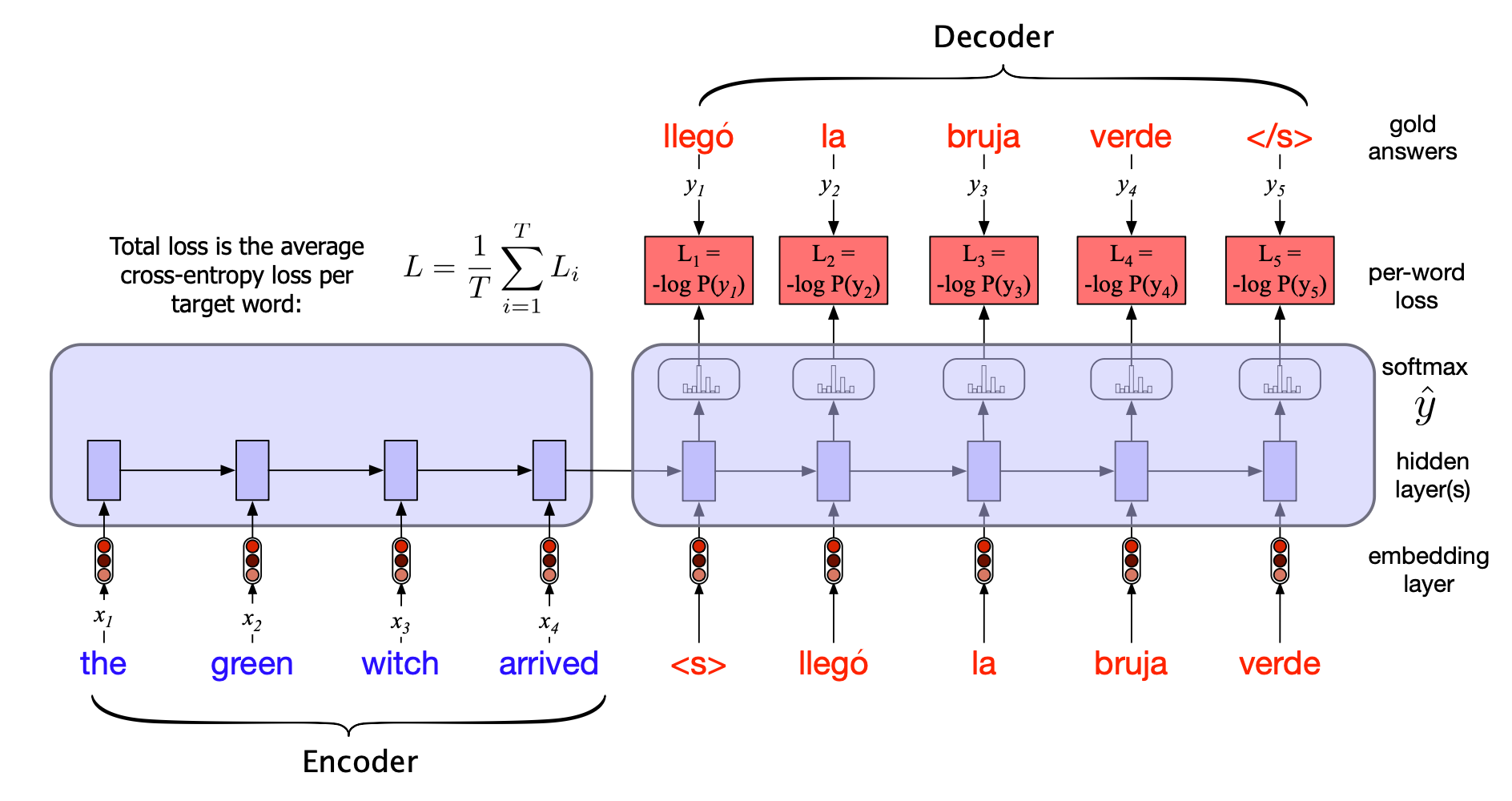
图 13.19 基于 RNN 的编码器-解码器机器翻译模型的训练过程。 注意:在解码器中,我们通常不将模型自身的 softmax 输出 $\hat{y}_t$ 作为下一步输入,而是使用教师强制,强制每个输入使用训练数据中的正确目标词。 我们仍会在解码器中计算每个时间步的 softmax 输出分布 $\hat{y}_t$,以便计算该词的损失;随后对整句各词的损失取平均,得到句子级别的损失。 该损失再通过反向传播,同时更新解码器和编码器的参数
注意训练(图 13.19)与推理(图 13.17)在每个时间步输出处理上的关键区别。 在推理阶段,解码器使用自己预测的输出 $\hat{y}_t$ 作为下一时间步的输入 $x_{t+1}$。 因此,随着生成的词越来越多,解码器可能会逐渐偏离真实的参考译文。 因此,在训练中通常采用教师强制(teacher forcing)策略:即强制解码器在每一步使用训练数据中的真实目标词(“黄金”标签)作为下一时间步的输入 $x_{t+1}$,而不是依赖其自身可能出错的预测 $\hat{y}_t$。 这种方法能显著加快训练速度。