至此,我们已经介绍了基本的 RNN 模型,学习了其高级组件(如多层堆叠和 LSTM 变体),并探讨了 RNN 在多种任务中的应用方式。现在,让我们对这些应用场景所对应的典型架构做一个简要总结。
图 13.15 展示了我们迄今讨论过的三种主要架构:序列标注、序列分类 和 语言建模。 在序列标注任务中(例如词性标注或命名实体识别),模型为输入序列中的每个词或词元生成一个对应的标签。 在序列分类任务中(例如情感分析),我们忽略中间每个词元的输出,仅使用序列末尾的表示进行最终预测;相应地,模型的训练信号也仅来自最后一个时间步的反向传播。 在语言建模任务中,模型在每个时间步都接受此前的上下文,并被训练用于预测下一个词。 在下一节中,我们将介绍第四种架构——编码器-解码器(encoder-decoder)。
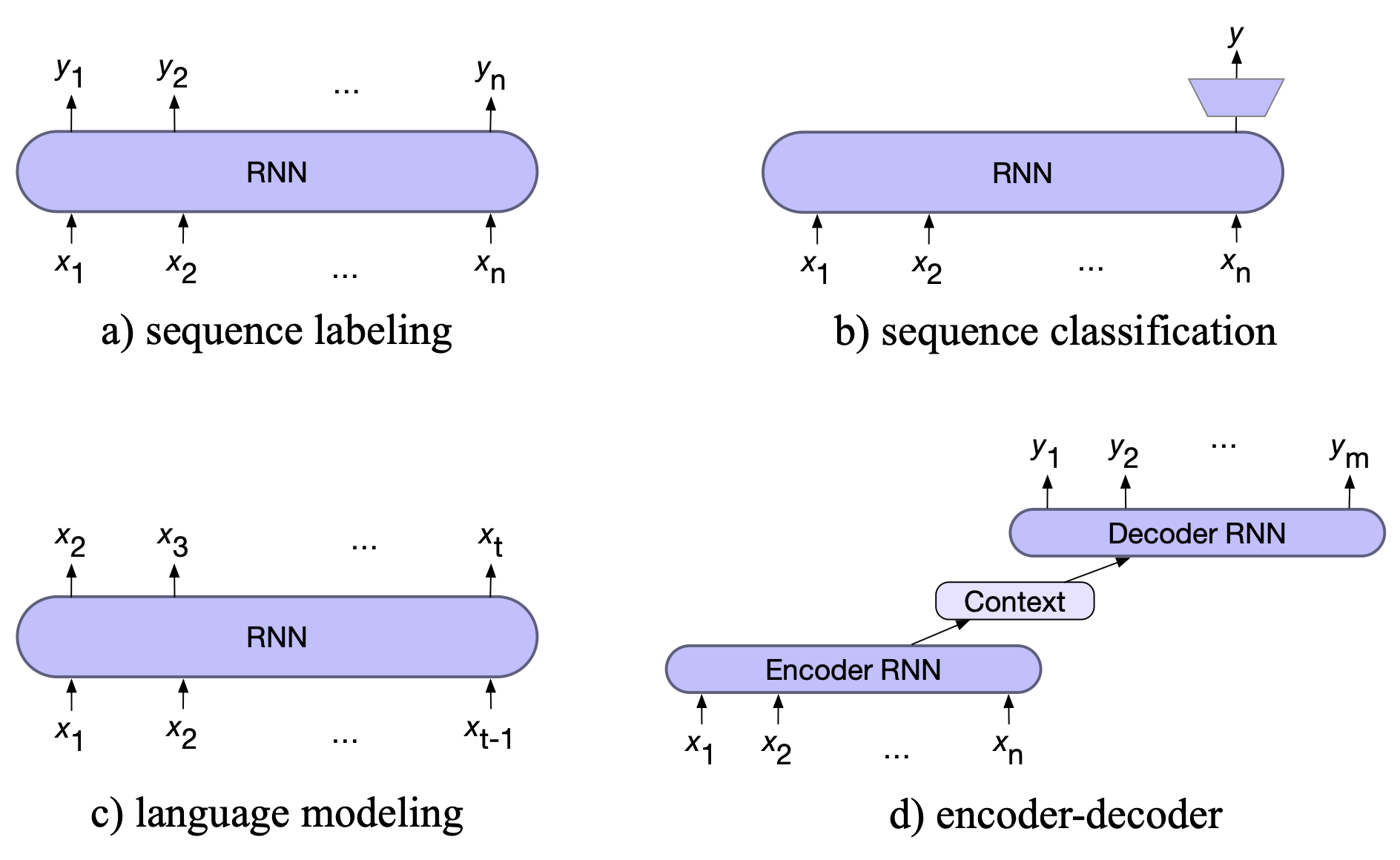
图 13.15 四种 NLP 任务的典型架构。 在序列标注(如词性标注或命名实体识别)中,我们将每个输入词元 $x_i$ 映射到一个输出标签 $y_i$; 在序列分类中,整个输入序列被映射为一个单一类别; 在语言建模中,模型基于先前的词元预测下一个词元; 在编码器-解码器架构中,包含两个独立的 RNN 模型:第一个(编码器)将输入序列 $x$ 映射为一个中间表示(称为上下文或语义向量),第二个(解码器)则基于该上下文生成输出序列 $y$。