在实践中,当任务所需的信息远离当前处理位置时,RNN 很难训练。 尽管 RNN 理论上可以访问整个先前序列,但其隐藏状态中编码的信息往往具有较强的局部性,更侧重于输入序列最近的部分以及最近的决策。 然而,在许多语言任务中,远距离信息至关重要。
考虑以下语言建模中的例子:
(13.19) The flights the airline was canceling were full.
在 airline 之后预测 was 是相对直接的,因为 airline 提供了很强的局部上下文,支持单数主谓一致。 但要为 were 分配合适的概率则非常困难:不仅因为复数主语 flights 距离较远,还因为在中间上下文中出现了更近的单数名词 airline。 理想情况下,网络应能在处理中间部分的同时,将关于复数 flights 的远距离信息保留到需要时再使用。
RNN 难以传递关键的远距离信息,一个原因是隐藏层(以及决定隐藏层值的权重)被要求同时完成两项任务:一是为当前决策提供有用信息,二是更新并向前传递未来决策所需的信息。
训练 RNN 的另一个困难源于随时间反向传播(backpropagation through time, BPTT)错误信号的需求。 回顾第 13.1.2 节,时刻 $t$ 的隐藏层会参与下一时刻损失的计算,因此对总损失有贡献。 结果是在训练的反向传播过程中,梯度需沿着时间步反复相乘,乘积次数由序列长度决定。 这一过程常常导致梯度逐渐趋近于零,即所谓的梯度消失(vanishing gradients)问题。
为解决这些问题,研究者设计了更复杂的网络架构,明确地管理如何在时间上维持相关上下文:让网络能够学会遗忘不再需要的信息,并记住未来决策所需的信息。
其中最广泛使用的 RNN 扩展是长短期记忆网络(Long Short-Term Memory, LSTM)(Hochreiter 和 Schmidhuber, 1997)。 LSTM 将上下文管理问题分解为两个子问题:从上下文中移除不再需要的信息;添加可能对未来决策有用的信息。
解决这两个问题的关键在于让网络学习如何管理上下文,而不是在架构中硬编码某种策略。 LSTM 通过以下方式实现这一点:首先,在原有循环隐藏层之外,显式引入一个额外的“上下文”层;其次,使用特殊的神经单元结构,通过门控机制(gates)来控制信息流入和流出这些单元。 这些门由额外的可学习权重实现,它们依次作用于当前输入、前一时刻的隐藏状态以及前一时刻的上下文。
LSTM 中的各个门控机制遵循一种通用的设计模式:每个门都由一个前馈层、一个 sigmoid 激活函数,以及与被门控层进行逐元素相乘(pointwise multiplication)三部分组成。 之所以选择 sigmoid 作为激活函数,是因为它的输出倾向于趋近于 0 或 1。 将 sigmoid 输出与被门控层进行逐元素相乘的效果,类似于应用了一个二值掩码(binary mask)。 掩码中接近 1 的位置所对应的被门控层信息几乎原样保留;而对应掩码值较低的位置则基本被“抹除”。
我们首先来看遗忘门(forget gate)。 遗忘门的作用是从上下文(即细胞状态)中删除不再需要的信息。 它计算前一时刻隐藏状态 $\mathbf{h}_{t-1}$ 与当前输入 $\mathbf{x}_t$ 的加权和,并通过 sigmoid 函数生成一个介于 0 到 1 之间的掩码。 随后,该掩码与前一时刻的上下文向量 $\mathbf{c}_{t-1}$ 进行逐元素相乘,从而清除上下文中不再需要的信息。 两个向量的逐元素相乘(用符号 $\odot$ 表示,有时也称为哈达玛积(Hadamard product))会得到一个与输入向量维度相同的向量,其中第 $i$ 个元素是两个输入向量第 $i$ 个元素的乘积:
$$ \begin{align*} \mathbf{f}_t &= \sigma(\mathbf{U}_f \mathbf{h}_{t-1} + \mathbf{W}_f \mathbf{x}_t ) \tag{13.20} \\ \mathbf{k}_t &= \mathbf{c}_{t-1} \odot \mathbf{f}_t \tag{13.21} \end{align*} $$接下来,我们计算实际需要从先前隐藏状态和当前输入中提取的信息——这与我们在所有循环网络中使用的基本计算相同:
$$ \mathbf{g}_t = \tanh(\mathbf{U}_g \mathbf{h}_{t-1} + \mathbf{W}_g \mathbf{x}_t ) \tag{13.22} $$然后,我们生成输入门(add gate,也常称 input gate)的掩码,用于选择哪些新信息应被添加到当前上下文中:
$$ \begin{align*} \mathbf{i}_t &= \sigma(\mathbf{U}_i \mathbf{h}_{t-1} + \mathbf{W}_i \mathbf{x}_t ) \tag{13.23} \\ \mathbf{j}_t &= \mathbf{g}_t \odot \mathbf{i}_t \tag{13.24} \end{align*} $$接着,我们将这部分新信息加到经过遗忘门处理后的上下文上,得到更新后的上下文向量:
$$ \mathbf{c}_t = \mathbf{j}_t + \mathbf{k}_t \tag{13.25} $$最后一个门是输出门(output gate),用于决定当前隐藏状态需要哪些信息(即哪些上下文内容应当输出,而非仅保留在细胞状态中供未来使用):
$$ \begin{align*} \mathbf{o}_t &= \sigma(\mathbf{U}_o \mathbf{h}_{t-1} + \mathbf{W}_o \mathbf{x}_t) \tag{13.26} \\ \mathbf{h}_t &= \mathbf{o}_t \odot \tanh(\mathbf{c}_t) \tag{13.27} \end{align*} $$图 13.13 展示了单个 LSTM 单元的完整计算流程。 在给定各门对应权重的前提下,LSTM 接收前一时间步的上下文向量、隐藏状态以及当前输入向量作为输入。 输出更新后的上下文向量和隐藏状态。
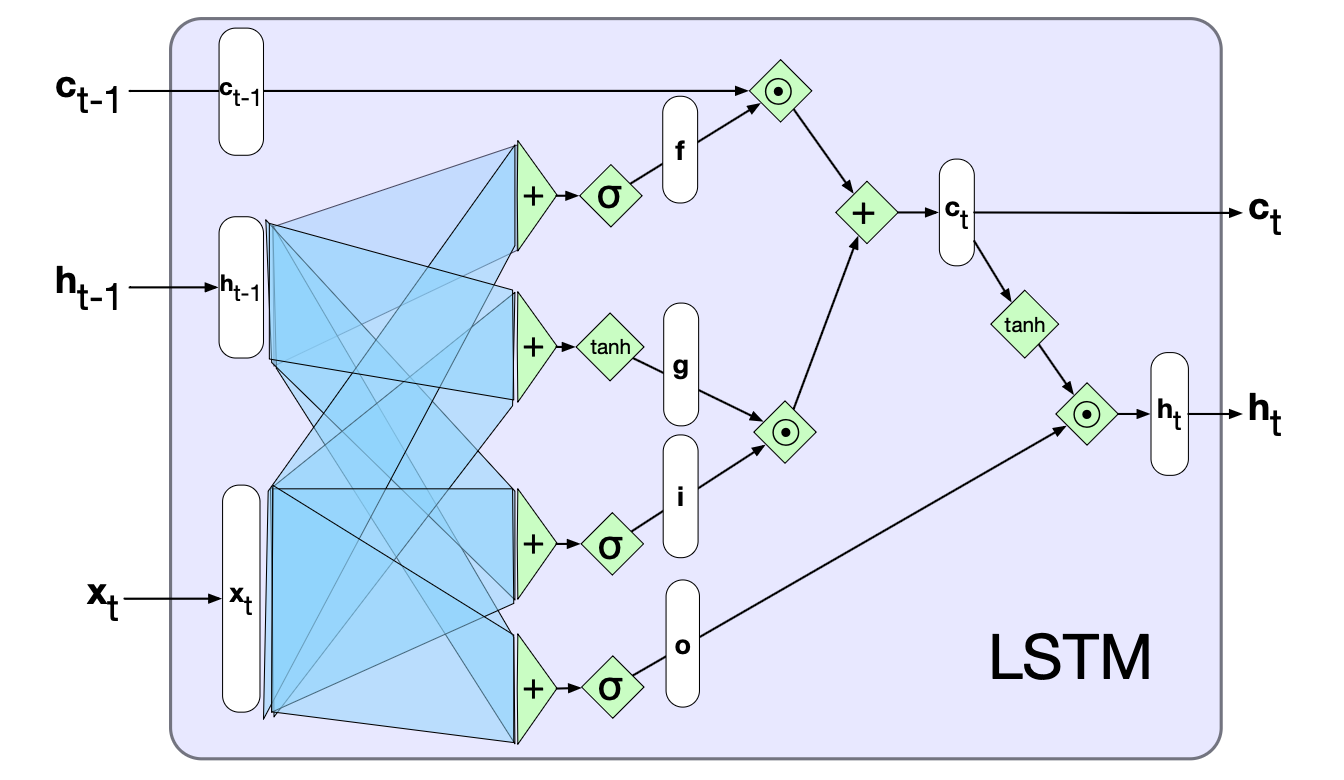
图 13.13 单个 LSTM 单元的计算图表示。每个单元的输入包括当前输入 $\mathbf{x}_t$、前一时刻的隐藏状态 $\mathbf{h}_{t-1}$ 和前一时刻的上下文(细胞状态)$\mathbf{c}_{t-1}$;输出为新的隐藏状态 $\mathbf{h}_t$ 和更新后的上下文 $\mathbf{c}_t$。
在每个时间步,LSTM 的输出由隐藏状态 $\mathbf{h}_t$ 提供。 该输出可作为堆叠式 RNN 中下一层的输入,也可在网络的最后一层直接用作 LSTM 的最终输出。
13.5.1 门控单元、层与网络
LSTM 中使用的神经单元显然比基本前馈网络中的单元复杂得多。 幸运的是,这种复杂性被封装在基本处理单元内部,使我们仍能保持模块化设计,并轻松尝试不同的架构。 为了说明这一点,请看图 13.14,它展示了各类单元的输入与输出结构。
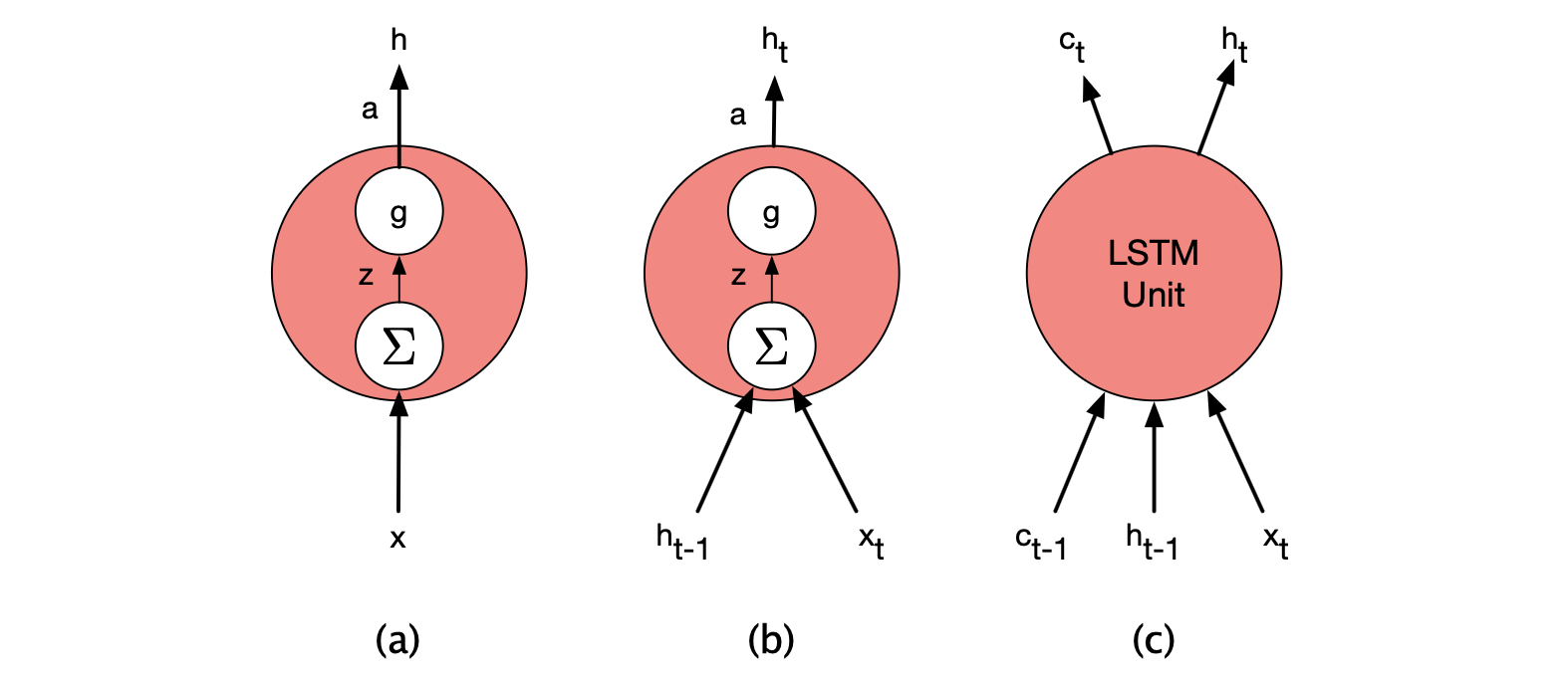
图 13.14 前馈网络、简单循环网络(SRN)和长短期记忆网络(LSTM)中使用的基本神经单元。
最左侧的 (a) 是基本的前馈单元:其输出由一组权重和一个激活函数决定;当这些单元组成一层时,层内各单元之间没有连接。 接着,(b) 表示简单循环网络(SRN)中的单元,它有两个输入,并对应两组权重,但仍然只使用一个激活函数和一个输出。
LSTM 单元的更高复杂度完全被封装在单元内部。 与基本循环单元 (b) 相比,LSTM 在外部仅增加了一项复杂性:即多了一个上下文向量作为额外的输入和输出。
这种模块化设计正是 LSTM 单元强大功能和广泛应用的关键所在。 LSTM 单元(或其他变体,如 GRU)可以无缝替换到第 13.4 节所述的任何网络架构中。 而且,与简单 RNN 一样,使用门控单元构建的多层网络也可以展开为深度前馈网络,并通过标准的反向传播算法进行训练。 因此,在实践中,LSTM 已取代传统 RNN,成为现代所有基于循环网络系统的标准单元。